标签:不同 现在 ati sof Alexnet size 原理 简化 span
R-CNN网络架构图
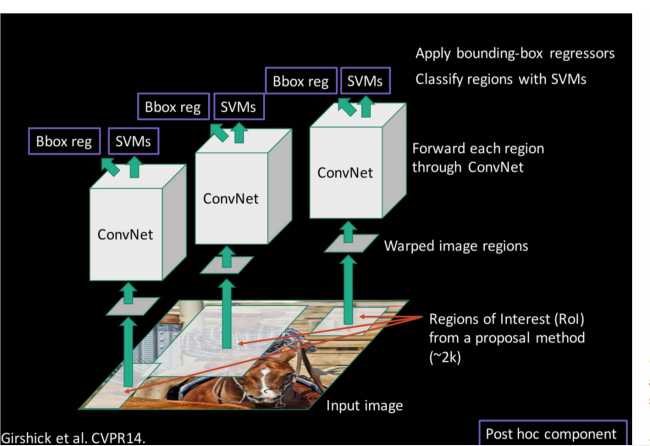
R-CNN网络框架流程
1)原图像经过 selective search算法提取约2000个候选框
2)候选框缩放到同一大小,原因是上图的ConvNet需要输入图片大小一致
3)通过ConvNet提取特征,原文ConvNet使用的是Alexnet,Alexnet需求的图片大小为(227*227),最后获得4096维特征向量
4)使用SVM对ConvNet提取的特征分类
使用4096维特征向量训练k个SVM分类器(k为分类数目),k个SVM分类器组成4096*k的矩阵N;把2000个候选框和4096维特征向量组合成2000*4096维矩阵M,
M和N做矩阵乘法得到2000*k的矩阵S,S中$s_{ij}$就是第i个候选框中属于第j个分类的概率
5)删除多余候选区域,边框回归
使用非极大值抑制NMS去除重叠候选区域,对SVM分好类的候选区域进行边框回归
R-CNN存在2个大问题
SPP-Net就是为了解决这2个问题,SPP-Net架构图如下
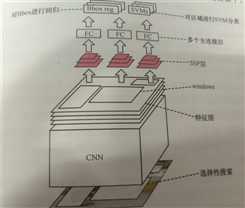
1)原图像经过 selective search算法提取约2000个候选框
2)通过CNN提取n个特征图
3)将 selective search算法提取的2000个候选框映射到n个feature map上,映射后的候选框叫windows,一共有2000*n个windows
4)把不同大小的windows经过SPP层处理为相同维度的特征向量,把特征向量作为FC的输入
SPP层架构图如下
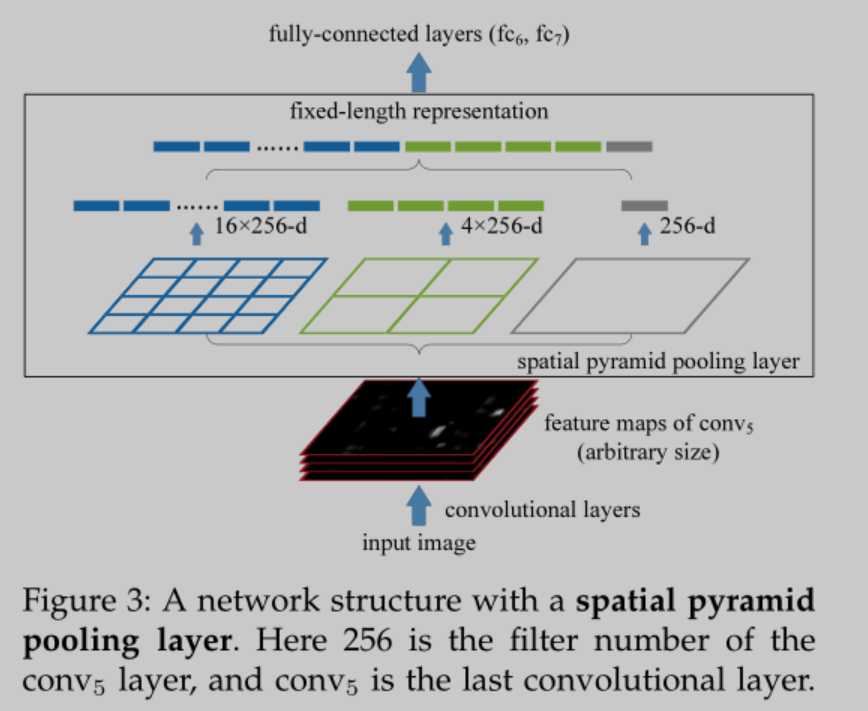
把每个w*h的window划分为4*4,2*2,1*1的网格,每个网格有(w/4,h/4)的特征,对每个网格进行Max Pooling,这样一个网格就只有1个最大的特征了。spatial pyramid pooling layer的第一个网格图有16维特征。3个网格图有21维特征,即一个window用21维向量表示,上图中feature map的深度n是256,256个feature map一共有256*2000个windows,最终2000个windows组成(2000,21,256)维特征向量输入到FC层
5)FC输出的特征向量使用SVM分类,并进行边框回归
Fast R-CNN的创新主要体现在
Fast R-CNN架构图如下
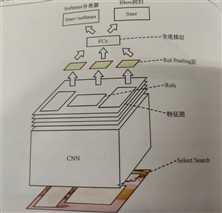
1)原图像经过 selective search算法提取约2000个候选框
2)通过ConvNet提取n个feature map
3)将 selective search算法提取的2000个候选框映射到n个feature map上,映射后的候选框叫Rols,一共有2000*n个Rols
4)把不同大小的Rols经过Rol Pooling层处理为相同维度的特征,此特征作为FC的输入
RoI Pooling层是一个简化版的spp layer,spp layer使用了4*4,2*2,1,*1的网格,RoI Pooling层只有一个7*7的网格。这样一个RoI就被表示成了一个(7*7,n)维特征,最终2000个候选框组成(2000,49,n)维特征作为FC输入
5)Rols通过FC后,用softmax分类,并进行边框回归
Fast R-CNN不在使用SVM分类,而是使用神经网络分类;同时利用多任务损失函数组合了分类和边框回归
Fast R-CNN的损失函数
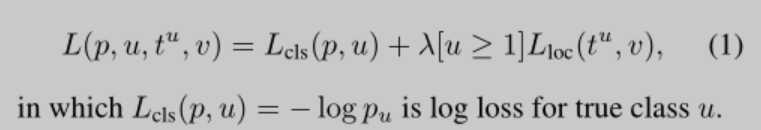
其中$p_u$是softmax函数
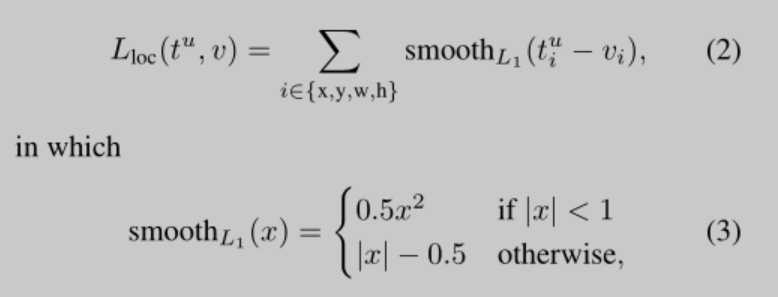

Fast R-CNN的创新主要体现在
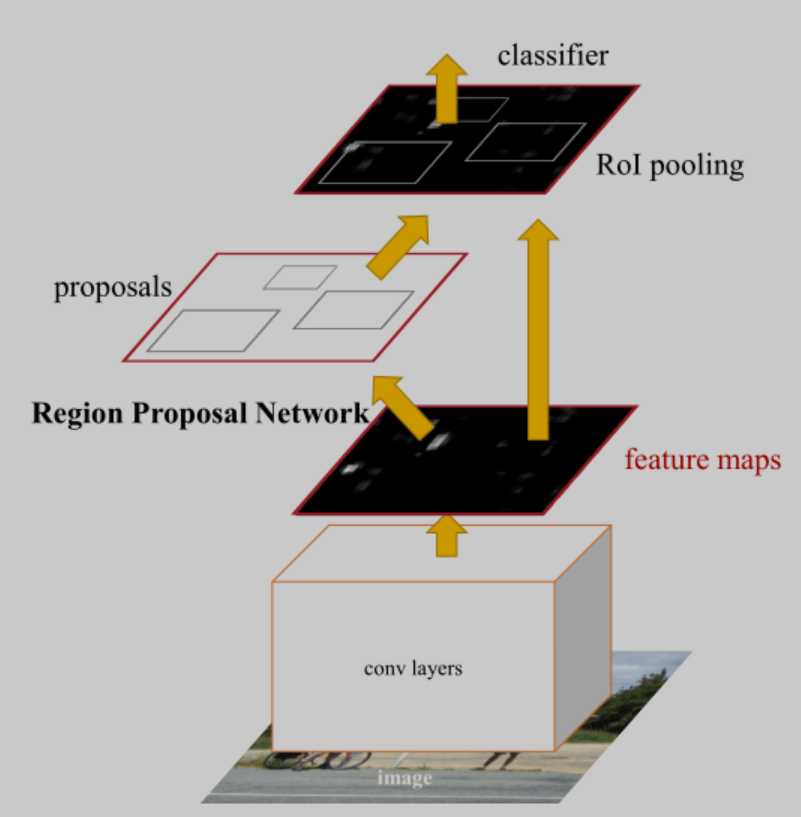
Faster R-CNN架构图
更加细节的图如下
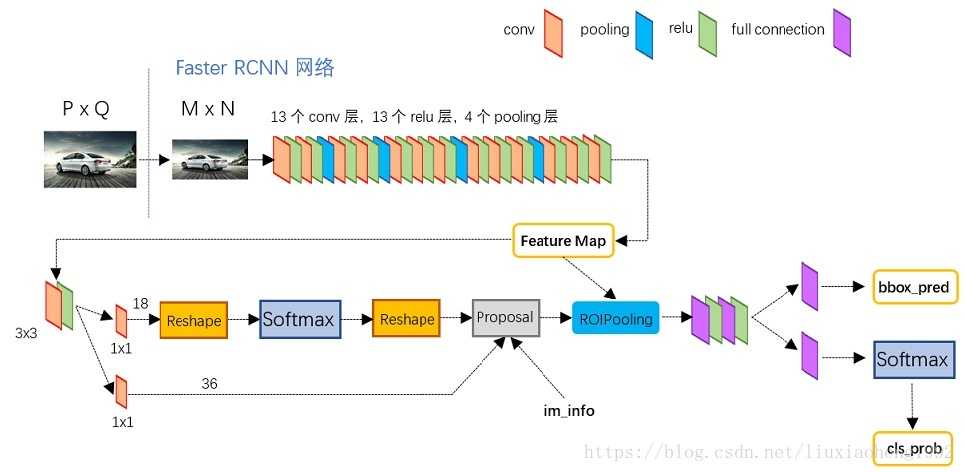
1)通过Conv layers提取n个feature map,这些feature map被RPN网络和Rol pooling层共享使用
Faster RCNN首先是支持输入任意大小的图片的,比如上图中输入的P*Q,进入网络之前对图片进行了规整化尺度的设定,如可设定图像短边不超过600,图像长边不超过1000,我们可以假定M*N=1000*600(如果图片少于该尺寸,可以边缘补0,即图像会有黑色边缘)
因此经过Conv layers,图片大小变成(M/16)*(N/16),即:60*40(1000/16≈60,600/16≈40);则Feature Map就是60*40*512-d(注:VGG16是512-d,ZF是256-d),表示特征图的大小为60*40,数量为512
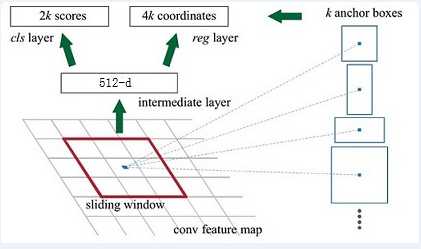
2)RPN网络以feature map为输入,输出候选区域框
RPN网络
输入RPN网络的60*40*512-d的feature map,首先使用kernel_size=3,pad=1,stride=1卷积,卷积完feature map尺寸不变,这样做的目的应该是进一步集中特征信息,原文中这个卷积核叫sliding window;一个sliding window的Receptive Field是228pixels ,各层feature map Receive Field
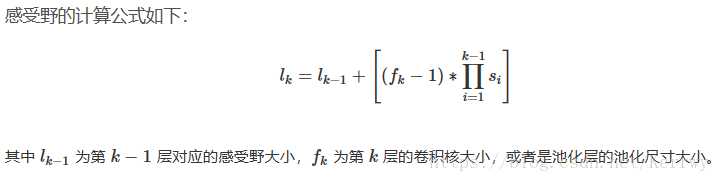 $s_i$是stride
$s_i$是stride
知道了一个sliding window能看多大的区域后,就可以对sliding window里边的区域进行分类和边框回归了。
在分类和回归之前,首先要先在sliding window上生成一些框,用来框住其中的物体,这个框叫Anchor。

这些anchor的面积分别为128*128,256*256,512*512
然后保持面积不变,改变长宽的比为1:1,1:2,2:1,最后生成9个anchor
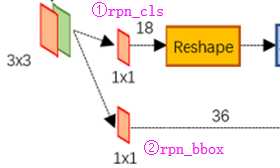
如上图中标识:
① rpn_cls:60*40*512-d ⊕ 1*1*512*18 ==> 60*40*9*2
逐像素对其9个Anchor box进行二分类(foreground、background)
② rpn_bbox:60*40*512-d ⊕ 1*1*512*36==>60*40*9*4
逐像素得到其9个Anchor box四个坐标信息
如下图所示:
3)Rol Pooling层接收RPN网络输出的候选区域框和特征图,输出相同维度的特征给FC层
4)Rols通过FC后,用softmax分类,并进行边框回归
标签:不同 现在 ati sof Alexnet size 原理 简化 span
原文地址:https://www.cnblogs.com/vshen999/p/10567578.html