标签:style http color io os ar 使用 java for
Twitter列举了Storm的三大类应用:
1. 信息流处理{Stream processing}
Storm可用来实时处理新数据和更新数据库,兼具容错性和可扩展性。
2. 连续计算{Continuous computation}
Storm可进行连续查询并把结果即时反馈给客户端。比如把Twitter上的热门话题发送到浏览器中。
3. 分布式远程程序调用{Distributed RPC}
Storm可用来并行处理密集查询。Storm的拓扑结构是一个等待调用信息的分布函数,当它收到一条调用信息后,会对查询进行计算,并返回查询结果。
举个例子Distributed RPC可以做并行搜索或者处理大集合的数据。
storm是什么
| Hadoop | Storm | |
| 系统角色 | JobTracker | Nimbus |
| TaskTracker | Supervisor | |
| Child | Worker | |
| 应用名称 | Job | Topology |
| 组件接口 | Mapper/Reducer | Spout/Bolt |
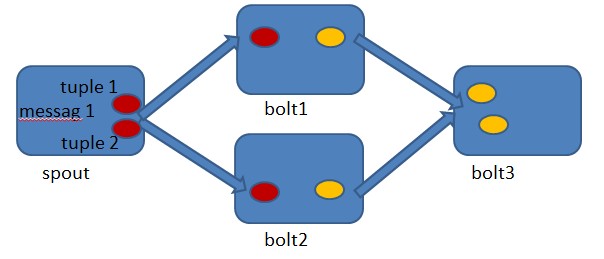
由于storm的内核是clojure编写的(不过大部分的拓展工作都是java编写的),为我们理解它的实现带来了一定的困难,
好在大部分情况下storm都比较稳定,当然我们也在尽力熟悉clojure的世界。我们在使用storm时通常都是选择java语言开发应用程序。
在淘宝,storm被广泛用来进行实时日志处理,出现在实时统计、实时风控、实时推荐等场景中。
一般来说,我们从类kafka的metaQ或者基于hbase的timetunnel中读取实时日志消息,经过一系列处理,最终将处理结果写入到一个分布式存储中,提供给应用程序访问。
我们每天的实时消息量从几百万到几十亿不等,数据总量达到TB级。对于我们来说,storm往往会配合分布式存储服务一起使用。
在我们正在进行的个性化搜索实时分析项目中,就使用了timetunnel + hbase + storm + ups的架构,每天处理几十亿的用户日志信息,从用户行为发生到完成分析延迟在秒级。
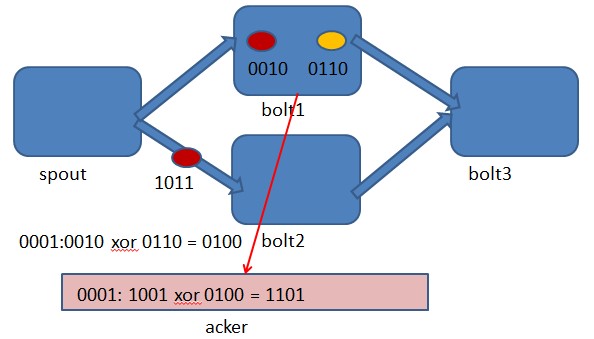
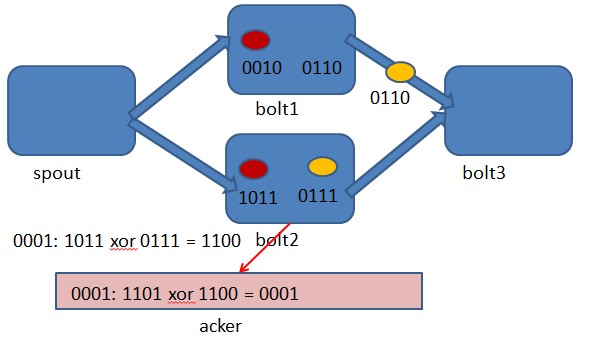
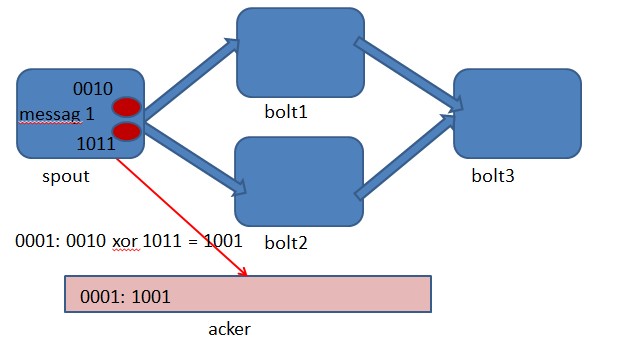
1. 目前的开源版本中只是单节点Nimbus,挂掉只能自动重启,可以考虑实现一个双nimbus的布局。
2. Clojure是一个在JVM平台运行的动态函数式编程语言,优势在于流程计算, Storm的部分核心内容由Clojure编写,虽然性能上提高不少但同时也提升了维护成本。
Storm集群由一个主节点和多个工作节点组成。主节点运行了一个名为“Nimbus”的守护进程,用于分配代码、布置任务及故障检测。每个工作节点都运行了一个名为“Supervisor”的守护进程,用于监听工作,开始并终止工作进程。Nimbus和Supervisor都能快速失败,而且是无状态的,这样一来它们就变得十分健壮,两者的协调工作是由Zookeeper来完成的。ZooKeeper用于管理集群中的不同组件,ZeroMQ是内部消息系统,JZMQ是ZeroMQMQ的Java Binding。
Storm的术语包括Stream、Spout、Bolt、Task、Worker、Stream Grouping和Topology。Stream是被处理的数据。Sprout是数据源。Bolt处理数据。Task是运行于Spout或Bolt中的 线程。Worker是运行这些线程的进程。Stream Grouping规定了Bolt接收什么东西作为输入数据。数据可以随机分配(术语为Shuffle),或者根据字段值分配(术语为Fields),或者 广播(术语为All),或者总是发给一个Task(术语为Global),也可以不关心该数据(术语为None),或者由自定义逻辑来决定(术语为Direct)。Topology是由Stream Grouping连接起来的Spout和Bolt节点网络.下面进行详细介绍:
stream grouping分类
1. Shuffle Grouping: 随机分组, 随机派发stream里面的tuple, 保证每个bolt接收到的tuple数目相同.
2. Fields Grouping:按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts, 而不同的userid则会被分配到不同的Bolts.
3. All Grouping: 广播发送, 对于每一个tuple, 所有的Bolts都会收到.
4. Global Grouping: 全局分组,这个tuple被分配到storm中的一个bolt的其中一个task.再具体一点就是分配给id值最低的那个task.
5. Non Grouping: 不分组,意思是说stream不关心到底谁会收到它的tuple.目前他和Shuffle grouping是一样的效果,有点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程去执行.
6. Direct Grouping: 直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者举鼎由消息接收者的哪个task处理这个消息.只有被声明为Direct Stream的消息流可以声明这种分组方法.而且这种消息tuple必须使用emitDirect方法来发射.消息处理者可以通过TopologyContext来或者处理它的消息的taskid (OutputCollector.emit方法也会返回taskid)
Storm如何保证消息被处理
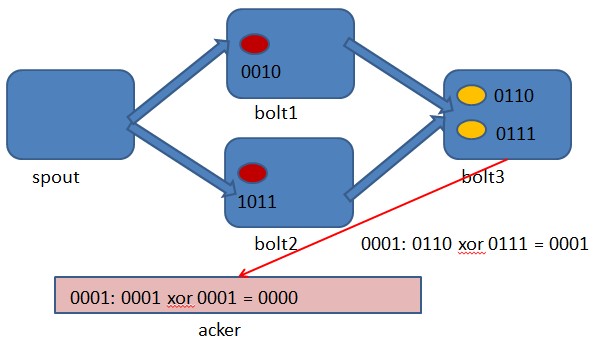
storm保证每个tuple会被topology完整的执行。storm会追踪由每个spout tuple所产生的tuple树(一个bolt处理一个tuple之后可能会发射别的tuple从而可以形成树状结构), 并且跟踪这棵tuple树什么时候成功处理完。每个topology都有一个消息超时的设置, 如果storm在这个超时的时间内检测不到某个tuple树到底有没有执行成功, 那么topology会把这个tuple标记为执行失败,并且过一会会重新发射这个tuple。
一个tuple能根据新获取到的spout而触发创建基于此的上千个tuple
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(1, new KestrelSpout("kestrel.backtype.com",
22133,
"sentence_queue",
new StringScheme()));
builder.setBolt(2, new SplitSentence(), 10)
.shuffleGrouping(1);
builder.setBolt(3, new WordCount(), 20)
.fieldsGrouping(2, new Fields("word"));
这个topology从kestrel queue读取句子,并把句子划分成单词,然后汇总每个单词出现的次数,一个tuple负责读取句子,每一个tuple分别对应计算每一个单词出现的次数,大概样子如下所示:
一个tuple的生命周期:
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}
首先storm通过调用spout的nextTuple方法来获取下一个tuple, Spout通过open方法参数里面提供的SpoutOutputCollector来发射新tuple到它的其中一个输出消息流, 发射tuple的时候spout会提供一个message-id, 后面我们通过这个tuple-id来追踪这个tuple。举例来说, KestrelSpout从kestrel队列里面读取一个消息,并且把kestrel提供的消息id作为message-id, 看例子:
collector.emit(new Values("field1", "field2", 3) , msgId);
接下来, 这个发射的tuple被传送到消息处理者bolt那里, storm会跟踪这个消息的树形结构是否创建,根据messageid调用Spout里面的ack函数以确认tuple是否被完全处理。如果tuple超时就会调用spout的fail方法。由此看出同一个tuple不管是acked还是fail都是由创建他的那个spout发出的,所以即使spout在集群环境中执行了很多的task,这个tule也不会被不同的task去acked或failed.
当kestrelspout从kestrel队列中得到一个消息后会打开这个他,这意味着他并不会把此消息拿走,消息的状态会显示为pending,直到等待确认此消息已经处理完成,处于pending状态直到ack或者fail被调用,处于"Pending"的消息不会再被其他队列消费者使用.如果在这过程中spout中处理此消息的task断开连接或失去响应则此pending的消息会回到"等待处理"状态.
1.流聚合
流聚合把两个或者多个数据流聚合成一个数据流 — 基于一些共同的tuple字段。
builder.setBolt(5, new MyJoiner(), parallelism)
.fieldsGrouping(1, new Fields("joinfield1", "joinfield2"))
.fieldsGrouping(2, new Fields("joinfield1", "joinfield2"))
.fieldsGrouping(3, new Fields("joinfield1", "joinfield2"))
2.批处理
有时候为了性能或者一些别的原因, 你可能想把一组tuple一起处理, 而不是一个个单独处理。
3.BasicBolt
1. 读一个输入tuple
2. 根据这个输入tuple发射一个或者多个tuple
3. 在execute的方法的最后ack那个输入tuple
遵循这类模式的bolt一般是函数或者是过滤器, 这种模式太常见,storm为这类模式单独封装了一个接口: IbasicBolt
4.内存内缓存+Fields grouping组合
在bolt的内存里面缓存一些东西非常常见。缓存在和fields grouping结合起来之后就更有用了。比如,你有一个bolt把短链接变成长链接(bit.ly, t.co之类的)。你可以把短链接到长链接的对应关系利用LRU算法缓存在内存里面以避免重复计算。比如组件一发射短链接,组件二把短链接转化成长链接并缓存在内存里面。看一下下面两段代码有什么不一样:
builder.setBolt(2, new ExpandUrl(), parallelism)
.shuffleGrouping(1);
builder.setBolt(2, new ExpandUrl(), parallelism)
.fieldsGrouping(1, new Fields("url"));
5.计算top N
比如你有一个bolt发射这样的tuple: "value", "count"并且你想一个bolt基于这些信息算出top N的tuple。最简单的办法是有一个bolt可以做一个全局的grouping的动作并且在内存里面保持这top N的值。
这个方式对于大数据量的流显然是没有扩展性的, 因为所有的数据会被发到同一台机器。一个更好的方法是在多台机器上面并行的计算这个流每一部分的top N, 然后再有一个bolt合并这些机器上面所算出来的top N以算出最后的top N, 代码大概是这样的:
builder.setBolt(2, new RankObjects(), parallellism)
.fieldsGrouping(1, new Fields("value"));
builder.setBolt(3, new MergeObjects())
.globalGrouping(2);
这个模式之所以可以成功是因为第一个bolt的fields grouping使得这种并行算法在语义上是正确的。
用TimeCacheMap来高效地保存一个最近被更新的对象的缓存
6.用TimeCacheMap来高效地保存一个最近被更新的对象的缓存
有时候你想在内存里面保存一些最近活跃的对象,以及那些不再活跃的对象。 TimeCacheMap 是一个非常高效的数据结构,它提供了一些callback函数使得我们在对象不再活跃的时候我们可以做一些事情.
7.分布式RPC:CoordinatedBolt和KeyedFairBolt
用storm做分布式RPC应用的时候有两种比较常见的模式:它们被封装在CoordinatedBolt和KeyedFairBolt里面. CoordinatedBolt包装你的bolt,并且确定什么时候你的bolt已经接收到所有的tuple,它主要使用Direct Stream来做这个.
KeyedFairBolt同样包装你的bolt并且保证你的topology同时处理多个DRPC调用,而不是串行地一次只执行一个。
标签:style http color io os ar 使用 java for
原文地址:http://www.cnblogs.com/muzhongjiang/p/4004820.html