标签:bsp 导数 变换 方法 出现 激励 运算 img 均值
卷积神经网络结构:

1、
数据输入层:
去均值:将平均值变为0
归一化:将不同的特征,取值范围变为一致的
PCA降维、白化
2、
卷积计算层:
每个神经元看做是一个过滤器(一个带权重的矩阵),过滤器对原数据进行卷积相关操作(内积),不同过滤器关注的特征不同
局部连接:过滤器提取局部特征,然后再与后面的网络相连。
参数共享:一个卷积核包含多个神经元,不同神经元的权重参数不同,但是一个神经元在原始数据上进行滑动提取局部特征,在这个工程中,参数是不变的。
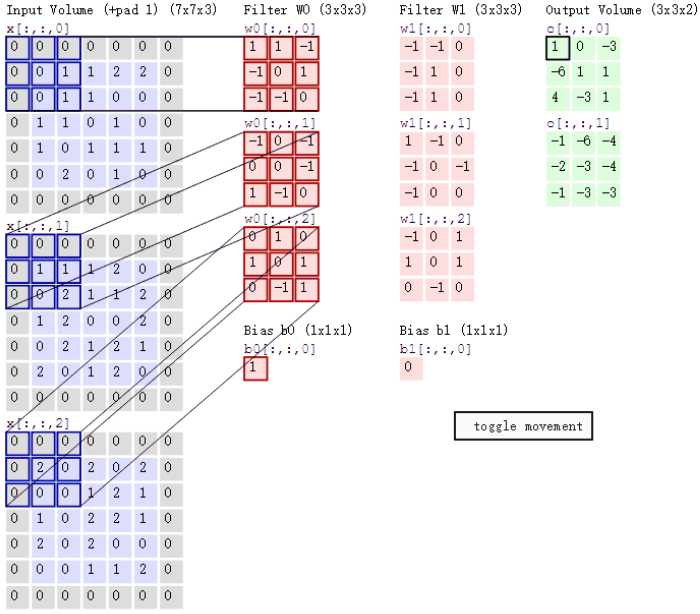
3、
激励层:
上面的图中output是由input和filter由线性关系得到的。
激励层的作用就是对output做一个非线性的变换、映射。
激活函数一般采用relu函数或者tanh,尽量不要用sigmod。
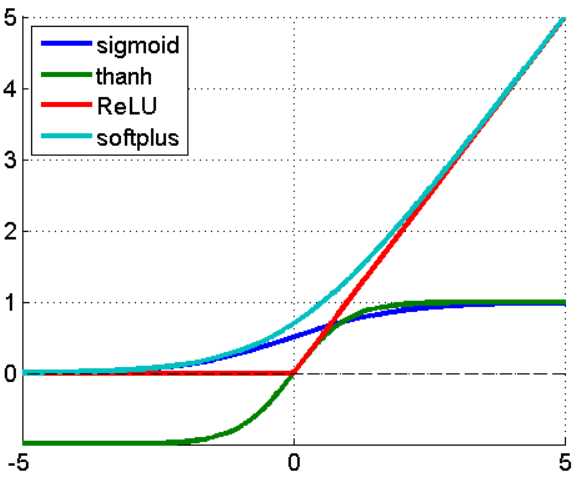
采用ReLu的原因
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现 梯度消失 的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
第三,ReLu会使一部分神经元的输出为0,这样就造成了 网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
4、
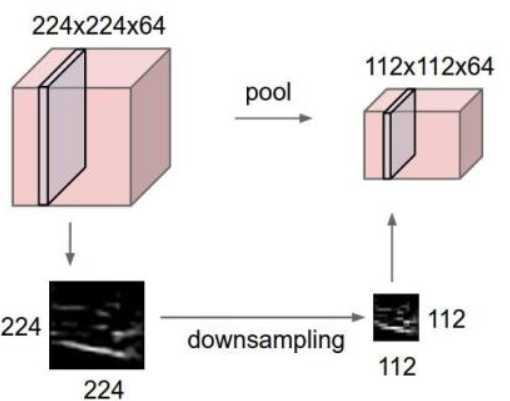
池化层:
用来压缩图像,提取局部主要特征,减小过拟合。
特征不变性:一个狗的图片,压缩为一半之后仍能看出是一条狗,保留了主要特征。
特征降维:提取主要特征,去除冗杂信息。
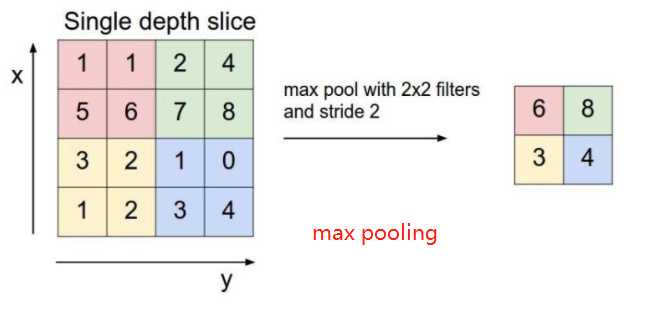
最常用max polling,其次average polling。
5、
全连接层:
和最后的输出层相连的,和传统神经网络一致。
CNN训练方法;
定义损失函数,采用随机梯度下降(每次训练只采用部分训练样本来求取梯度),来求解过滤器的权重以及偏置bias。
标签:bsp 导数 变换 方法 出现 激励 运算 img 均值
原文地址:https://www.cnblogs.com/liqiniuniu/p/10600705.html