标签:image boa appdata font 合并 流程 表单 集合 计算
1. 把文档A分词形成分词向量L 2. 使用K个hash函数,然后每个hash将L里面的分词分别进行hash,然后得到K个被hash过的集合 3. 分别得到K个集合中的最小hash,然后组成一个长度为K的hash集合 4. 最后用Jaccard index求出两篇文档的相似度
1. 把文档A分词形成分词向量L,L中的每一个元素都包涵一个分词C以及一个分词的权重W 2. 对L中的每一个元素的分词C进行hash,得到C1,然后组成一个新的向量L1 3. 初始化一个长度大于C1长度的向量V,所有元素初始化为0 4. 分别判断L1中的每一个元素C1的第i位,如果C1i是1,那么Vi加上w,否则Vi减去w 5. 最后判断V中的每一项,如果第i项大于0,那么第i项变成1,否则变成0 6. 两篇文档a,b分别得到aV,bV 6. 最后求出aV和bV的海明距离,一般距离不大于3的情况下说明两篇文档是相似的


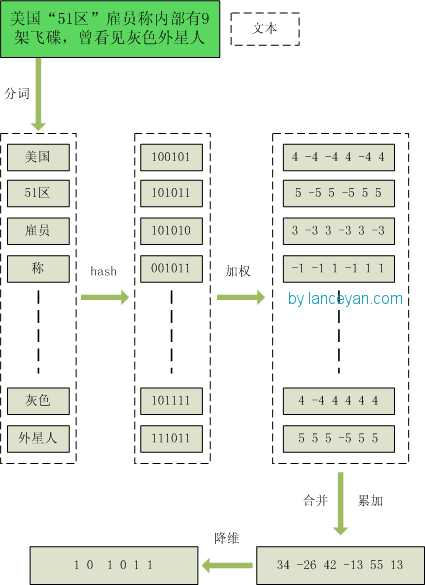
1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
整个过程图为:


标签:image boa appdata font 合并 流程 表单 集合 计算
原文地址:https://www.cnblogs.com/jingsupo/p/10607764.html