标签:false web must find return table get ext either
起点作为主流的小说网站,在防止数据采集反面还是做了准备的,其对主要的数字采用了自定义的编码映射取值,想直接通过页面来实现数据的获取,是无法实现的。
单独获取数字还是可以实现的,通过requests发送请求,用正则去匹配字符元素,并再次匹配其映射关系的url,获取到的数据通过font包工具解析成字典格式,再做编码匹配,起点返回的编码匹配英文数字,英文数字匹配阿拉伯数字,最后拼接,得到实际的数字字符串,但这样多次发送请求,爬取效率会大大降低。本次集中爬取舍弃了爬取数字,选择了较容易获取的评分数字。评分值默认为0 ,是从后台推送的js数据里取值更新的。
实现的主要代码:
items部分:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
from scrapy import Field
class QdItem(scrapy.Item):
# define the fields for your item here like:
book_name = scrapy.Field() #书名
author=scrapy.Field() #作者
state=scrapy.Field() #状态
type=scrapy.Field() #类型
about=scrapy.Field() #简介
# number=scrapy.Field() #字数
score=scrapy.Field() #评分
story=scrapy.Field() #故事
news=scrapy.Field() #最新章节
photo=scrapy.Field() #封面
spider部分:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from qd.items import QdItem
import re,requests
from fontTools.ttLib import TTFont
from io import BytesIO
import time
class ReadSpider(CrawlSpider):
name = ‘read‘
# allowed_domains = [‘qidian.com‘]
start_urls = [‘https://www.qidian.com/all?orderId=&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0&page=1‘]
rules = (
#匹配全部主页面的url规则 深度爬取子页面
Rule(LinkExtractor(allow=(r‘https://www.qidian.com/all\?orderId=\&style=1\&pageSize=20\&siteid=1\&pubflag=0\&hiddenField=0\&page=(\d+)‘)),follow=True),
#匹配详情页面 不作深度爬取
Rule(LinkExtractor(allow=r‘https://book.qidian.com/info/(\d+)‘), callback=‘parse_item‘, follow=False),
)
def parse_item(self, response):
item=QdItem()
item[‘book_name‘]=self.get_book_name(response)
item[‘author‘]=self.get_author(response)
item[‘state‘]=self.get_state(response)
item[‘type‘]=self.get_type(response)
item[‘about‘]=self.get_about(response)
# item[‘number‘]=self.get_number(response)
item[‘score‘]=self.get_score(response)
item[‘story‘]=self.get_story(response)
item[‘news‘]=self.get_news(response)
item[‘photo‘]=self.get_photo(response)
yield item
def get_book_name(self,response):
book_name=response.xpath(‘//h1/em/text()‘).extract()[0]
if len(book_name)>0:
book_name=book_name.strip()
else:
book_name=‘NULL‘
return book_name
def get_author(self,response):
author=response.xpath(‘//h1/span/a/text()‘).extract()[0]
if len(author)>0:
author=author.strip()
else:
author=‘NULL‘
return author
def get_state(self,response):
state=response.xpath(‘//p[@class="tag"]/span/text()‘).extract()[0]
if len(state)>0:
state=state.strip()
else:
st=‘NULL‘
return state
def get_type(self,response):
type=response.xpath(‘//p[@class="tag"]/a/text()‘).extract()
if len(type)>0:
t=""
for i in type:
t+=‘ ‘+i
type=t
else:
type=‘NULL‘
return type
def get_about(self,response):
about=response.xpath(‘//p[@class="intro"]/text()‘).extract()[0]
if len(about)>0:
about=about.strip()
else:
about=‘NULL‘
return about
# def get_number(self,response):
#
# def get_font(url): #获取字体对应的字典编码
# time.sleep(2)
# resp=requests.get(url)
# font=TTFont(BytesIO(resp.content))
# cmap=font.getBestCmap()
# font.close()
# return cmap
#
# def get_encode(cmap,values):
# #values的值 ‘𘛖𘛘𘛕𘛔𘛎𘛎‘
# #中英数字编码表
# WORD_MAP = {‘zero‘: ‘0‘, ‘one‘: ‘1‘, ‘two‘: ‘2‘, ‘three‘: ‘3‘, ‘four‘: ‘4‘, ‘five‘: ‘5‘, ‘six‘: ‘6‘,
# ‘seven‘: ‘7‘,‘eight‘: ‘8‘, ‘nine‘: ‘9‘, ‘period‘: ‘.‘}
# list=values.split(‘;‘)
# list.pop(-1)
# new_num=‘‘
# #移除最后的分号;
# for num in list:
# value=num[2:]
# key=cmap[int(value)]
# new_num+=WORD_MAP[key]
# return new_num
#
# # pattern=re.compile(‘</style><span.*?>(.*?)</span>‘,re.S) #数字字符匹配规则
# # # 𘛖𘛘𘛕𘛔𘛎𘛎
# # number_list=re.findall(pattern,response)
# # #匹配所有数字字符列表
# # reg=re.compile(‘<style.*?>(.*?)\s*</style>‘,re.S) #包含字体链接的文本
# # font_url=re.findall(reg,response)[0]
# # url=re.search(‘woff.*?url.*?\‘(.+?)\‘.*?truetype‘,font_url).group(1) #获取当前数字库的链接地址
# # # https://qidian.gtimg.com/qd_anti_spider/xxxxx.ttf
# #
# # cmap=get_font(url) #获取字典对应编码
# # # {100046: ‘seven‘, 100048: ‘three‘, 100049: ‘five‘, 100050: ‘six‘, 100051: ‘one‘, 100052: ‘period‘, 100053: ‘nine‘, 100054: ‘four‘, 100055: ‘eight‘, 100056: ‘two‘, 100057: ‘zero‘}
# #
# #
# # d_num=[] #解码后的所有数字追加进去
# # for num in number_list: #遍历列表中的元素
# # d_num.append(get_encode(cmap,num))
# # if len(d_num)>0:
# # return d_num[0]+‘万字‘
# # else:
# return ‘NULL‘
def get_score(self,response):
def get_sc(id):
urll = ‘https://book.qidian.com/ajax/comment/index?_csrfToken=ziKrBzt4NggZbkfyUMDwZvGH0X0wtrO5RdEGbI9w&bookId=‘ + id + ‘&pageSize=15‘
rr = requests.get(urll)
# print(rr)
score = rr.text[16:19]
return score
bid=response.xpath(‘//a[@id="bookImg"]/@data-bid‘).extract()[0] #获取书的id
if len(bid)>0:
score=get_sc(bid) #调用方法获取评分 若是整数 可能返回 9,"
if score[1]==‘,‘:
score=score.replace(‘,"‘,".0")
else:
score=score
else:
score=‘NULL‘
return score
def get_story(self,response):
story=response.xpath(‘//div[@class="book-intro"]/p/text()‘).extract()[0]
if len(story)>0:
story=story.strip()
else:
story=‘NULL‘
return story
def get_news(self,response):
news=response.xpath(‘//div[@class="detail"]/p[@class="cf"]/a/text()‘).extract()[0]
if len(news)>0:
news=news.strip()
else:
news=‘NULL‘
return news
def get_photo(self,response):
photo=response.xpath(‘//div[@class="book-img"]/a[@class="J-getJumpUrl"]/img/@src‘).extract()[0]
if len(photo)>0:
photo=photo.strip()
else:
photo=‘NULL‘
return photo
middlewaver 中间件部分:
# # -*- coding: utf-8 -*-
#
# # Define here the models for your spider middleware
# #
# # See documentation in:
# # https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#
# from scrapy import signals
#
#
# class QdSpiderMiddleware(object):
# # Not all methods need to be defined. If a method is not defined,
# # scrapy acts as if the spider middleware does not modify the
# # passed objects.
#
# @classmethod
# def from_crawler(cls, crawler):
# # This method is used by Scrapy to create your spiders.
# s = cls()
# crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
# return s
#
# def process_spider_input(self, response, spider):
# # Called for each response that goes through the spider
# # middleware and into the spider.
#
# # Should return None or raise an exception.
# return None
#
# def process_spider_output(self, response, result, spider):
# # Called with the results returned from the Spider, after
# # it has processed the response.
#
# # Must return an iterable of Request, dict or Item objects.
# for i in result:
# yield i
#
# def process_spider_exception(self, response, exception, spider):
# # Called when a spider or process_spider_input() method
# # (from other spider middleware) raises an exception.
#
# # Should return either None or an iterable of Response, dict
# # or Item objects.
# pass
#
# def process_start_requests(self, start_requests, spider):
# # Called with the start requests of the spider, and works
# # similarly to the process_spider_output() method, except
# # that it doesn’t have a response associated.
#
# # Must return only requests (not items).
# for r in start_requests:
# yield r
#
# def spider_opened(self, spider):
# spider.logger.info(‘Spider opened: %s‘ % spider.name)
#
#
# class QdDownloaderMiddleware(object):
# # Not all methods need to be defined. If a method is not defined,
# # scrapy acts as if the downloader middleware does not modify the
# # passed objects.
#
# @classmethod
# def from_crawler(cls, crawler):
# # This method is used by Scrapy to create your spiders.
# s = cls()
# crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
# return s
#
# def process_request(self, request, spider):
# # Called for each request that goes through the downloader
# # middleware.
#
# # Must either:
# # - return None: continue processing this request
# # - or return a Response object
# # - or return a Request object
# # - or raise IgnoreRequest: process_exception() methods of
# # installed downloader middleware will be called
# return None
#
# def process_response(self, request, response, spider):
# # Called with the response returned from the downloader.
#
# # Must either;
# # - return a Response object
# # - return a Request object
# # - or raise IgnoreRequest
# return response
#
# def process_exception(self, request, exception, spider):
# # Called when a download handler or a process_request()
# # (from other downloader middleware) raises an exception.
#
# # Must either:
# # - return None: continue processing this exception
# # - return a Response object: stops process_exception() chain
# # - return a Request object: stops process_exception() chain
# pass
#
# def spider_opened(self, spider):
# spider.logger.info(‘Spider opened: %s‘ % spider.name)
import random,base64
from qd.settings import USER_AGENT,PROXIES
class RandomUserAgent(object):
def process_request(self,request,spider):
user_agent=random.choice(USER_AGENT)
if user_agent:
request.headers.setdefault("User-Agent",user_agent)
class RandomProxy(object):
def process_request(self,request,spider):
proxy=random.choice(PROXIES)
if proxy[‘user_psd‘]is None: #没有用户名和密码则不需要认证
request.meta[‘proxy‘]=‘http://‘+proxy[‘ip_port‘]
else:
bs64_user_psd=base64.b64encode(proxy[‘user_psd‘])
request.meta[‘proxy‘]=‘http://‘+proxy[‘ip_port‘]
request.headers[‘Proxy-Authorization‘]=‘Basic ‘+bs64_user_psd
pipeline管道部分:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don‘t forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql,re
from scrapy.exceptions import DropItem
class QdPipeline(object):
def __init__(self):
self.connect = pymysql.connect(
user=‘root‘, # 用户名
password=‘1234‘, # 密码
db=‘lgweb‘, # 数据库名
host=‘127.0.0.1‘, # 地址
port=3306,
charset=‘utf8‘
)
def table_exists(self, con, table_name):
# 判断数据表是否已经创建
sql = ‘show tables;‘
con.execute(sql)
tables = [con.fetchall()]
table_list = re.findall(‘(\‘.*?\‘)‘, str(tables))
table_list = [re.sub("‘", ‘‘, each) for each in table_list] # 遍历并获得数据库表
if table_name in table_list:
return 1 # 创建了返回1
else:
return 0 # 不创建返回0
def process_item(self, item, spider):
conn = self.connect.cursor() # 创建该链接的游标
conn.execute(‘use lgweb‘) # 指定数据库
table_name = ‘db_read‘ # 数据库表
valid = True
for data in item:
if not data:
valid = False
raise DropItem(‘Missing %s of blogpost from %s‘ % (data, item[‘url‘]))
if valid: # 如果item里面有数据则取出来
book_name = item[‘book_name‘]
author = item[‘author‘]
state = item[‘state‘]
type = item[‘type‘]
about = item[‘about‘]
# number = item[‘number‘]
score = item[‘score‘]
story = item[‘story‘]
news = item[‘news‘]
photo = item[‘photo‘]
# 没有对应数据库表则创建
if (self.table_exists(conn, table_name) != 1):
sql = ‘create table db_read(书名 VARCHAR (30),作者 VARCHAR (30),评分 VARCHAR (10),类型 VARCHAR (30),状态 VARCHAR (30),简介 VARCHAR (50),详情 VARCHAR (1000),最新章节 VARCHAR (50),封面 VARCHAR (100))‘
conn.execute(sql) # 不存在则创建数据库表
try:
# 有数据则插入数据表
sql = "insert into db_read(书名,作者,评分,类型,状态,简介,详情,最新章节,封面)VALUES (‘%s‘,‘%s‘,‘%s‘,‘%s‘,‘%s‘,‘%s‘,‘%s‘,‘%s‘,‘%s‘)" % (
book_name,author,score,type,state,about,story,news, photo)
conn.execute(sql) # 执行插入数据操作
self.connect.commit() # 提交保存
finally:
conn.close()
return item
settings进行简单配置,就可以运行程序了。
为了方便调试程序,可以在项目外编写一个main.py入口文件,和命令行执行 scrapy crawl read 效果是一样的。
main代码如下:
from scrapy import cmdline
cmdline.execute(‘scrapy crawl read‘.split())
爬取数据效果图: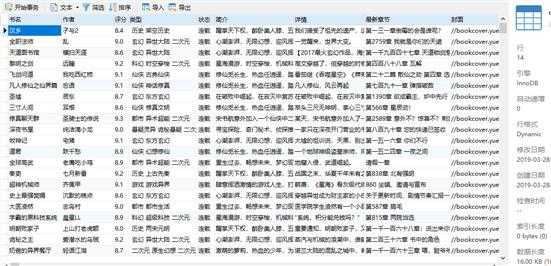
标签:false web must find return table get ext either
原文地址:https://www.cnblogs.com/wen-kang/p/10614263.html