标签:reduce pre 结合 控制 合并 ack mic 决定 切割
Hadoop是分布式文件系统
并行处理系统:高效存储和高效处理组件
Mapreduce,函数式编程机制,分Map阶段和reduce阶段,他不但是一个编程方式,同时也是个运行框架,它分两个阶段
Map阶段:抽取各个键值对生成键值对结果集(一般存在本地),这些键值对存储下来并进行排序
reduce阶段:将Map的结果合并成处理结果的机制
所有Map完成才能启动reduce处理
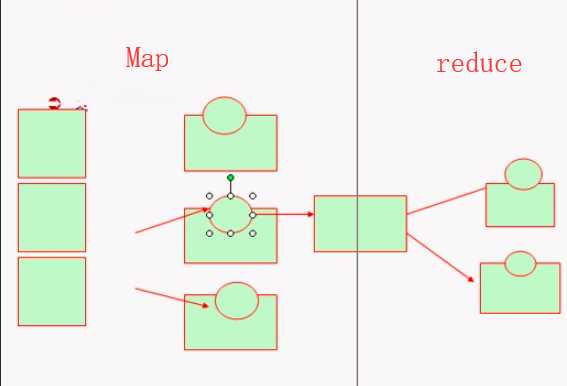
MapReduce是一个批处理作业系统(运行一段无法预估的时间)而不是实时系统。
GFS(The Google File System)谷歌文件系统是一种分布式文件系统,即将数据分布存储在多个数据节点上
一个重要思想是:Google的FileSystem和MapReduce结合起来以后,使得程序往数据上跑而不是数据往程序上跑。
Hadoop:为DFS文件系统或HDFS文件系统
HDFS+Mapreduce=Hadoop
Hadoop是如何工作的?
它把两个集群合到一块了(Hadoop集群和Mapreduce集群)
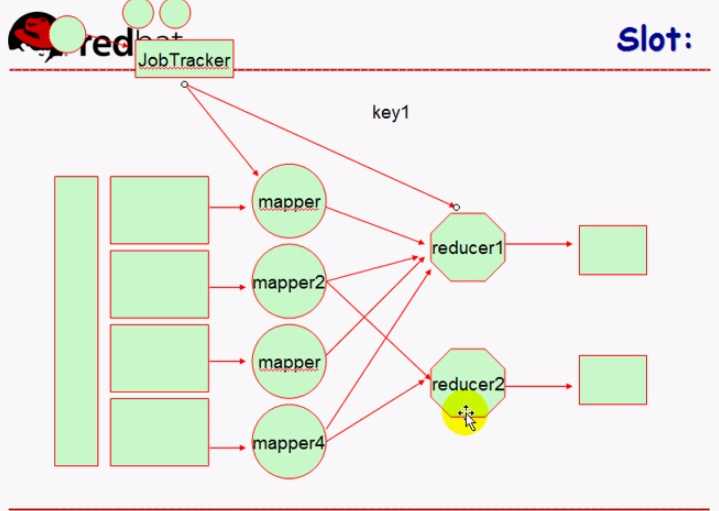
对于Hadoop Map节点启动几个程序员无法控制,由MapReduce自行决定的,但是reduce启动几个程序员可以控制(如果程序员不指定JobTracker自行决定)
JobTracker是MapReduce的控制节点,它能够决定在哪个节点上启动Map任务,并且能决定一共启动多少个Map任务
数据怎么切割,由Map决定
标签:reduce pre 结合 控制 合并 ack mic 决定 切割
原文地址:https://www.cnblogs.com/jialanshun/p/10617047.html