标签:自动 tar 开始 code play 过程 根据 大小 url
一、浏览器简介
浏览器是指可以显示网页服务器或者文件系统的HTML文件(标准通用标记语言的一个应用)内容,并让用户与这些文件交流互动的一种软件。
浏览器的主要功能是向服务器发出请求,在浏览器窗口中展示你选择的网络资源。这里所说的资源一般指HTML文档、PDF、图片或其他的类型。资源的位置由用户使用的URL(统一资源标符)指定。
URL是统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
二、浏览器的主要构成
浏览器的主要组件包括:
三、浏览器内核工作原理简介
浏览器最重要或者说核心的部分是“Rendering Engine”,可大概译为“渲染引擎”,不过我们一般习惯将之称为“浏览器内核”。负责对网页语法的解释(如标准通用标记语言下的一个应用HTML、JavaScript)并渲染(显示)网页。 所以,通常所谓的浏览器内核也就是浏览器所采用的渲染引擎,渲染引擎决定了浏览器如何显示网页的内容以及页面的格式信息。.
渲染引擎
渲染引擎在浏览器窗口中显示所请求的内容,渲染引擎一开始会从网络层获取请求文档的内容,通常以8K分块的方式完成。 获取了文档内容之后,渲染引擎开始正式工作,其基本流程如图所示:解析HTML以构造DOM树→构建渲染树结构→渲染树的布局 →绘制渲染树。
注意:这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的html都解析完成之后再去构建和布局渲染树。 它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
解析HTML以构造DOM树
浏览器为HTML定制了专属的解析器。HTML解析器的任务是将HTML标记解析成DOM树。Html5规范中描述了这个解析算法,算法包括两个阶段——符号化和构建树,符号化是词法分析的过程,将输入解析为符号,HTML的符号包括开始标签、 结束标签、 属性名及属性值。符号识别器识别出符号后,将其传递给树构建器,并读取下一个字符,以识别下一个符号,这样直到处理完所有输入。
HTML解析流程
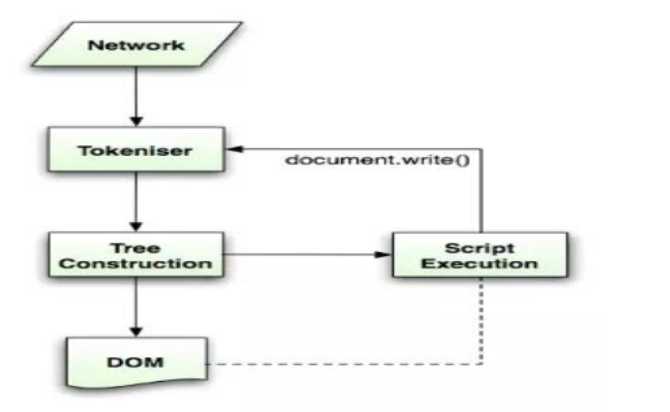
浏览器会遵守一套步骤将HTML文件转换为 DOM 树。宏观上,可以分为几个步骤:

浏览器从磁盘或网络读取HTML的原始字节,并根据文件的指定编码(例如 UTF-8)将它们转换成字符串。在网络中传输的内容其实都是 0 和 1 这些字节数据。当浏览器接收到这些字节数据以后,它会将这些字节数据转换为字符串,也就是我们写的代码。
事实上,构建DOM的过程中,不是等所有Token都转换完成后再去生成节点对象,而是一边生成Token一边消耗Token来生成节点对象。换句话说,每个Token被生成后,会立刻消耗这个Token创建出节点对象。注意:带有结束标签标识的Token不会创建节点对象。
构建渲染树结构
DOM会捕获页面的内容,但浏览器还需要知道页面如何展示,所以需要构建CSSOM。构建CSSOM的过程与构建DOM的过程非常相似,当浏览器接收到一段CSS,浏览器首先要做的是识别出Token,然后构建节点并生成CSSOM。

当我们生成 DOM 树和 CSSOM 树以后,就需要将这两棵树组合为渲染树。在这一过程中,不是简单的将两者合并就行了。渲染树只会包括需要显示的节点和这些节点的样式信息,如果某个节点是 display: none的,那么就不会在渲染树中显示。
渲染树的布局与绘制
当浏览器生成渲染树以后,就会根据渲染树来进行布局(也可以叫做回流)。这一阶段浏览器要做的事情是要弄清楚各个节点在页面中的确切位置和大小。通常这一行为也被称为“自动重排”。布局流程的输出是一个“盒模型”,它会精确地捕获每个元素在视口内的确切位置和尺寸,所有相对测量值都将转换为屏幕上的绝对像素。布局完成后,浏览器会立即发出“Paint Setup”和“Paint”事件,将渲染树转换成屏幕上的像素。
标签:自动 tar 开始 code play 过程 根据 大小 url
原文地址:https://www.cnblogs.com/m223z/p/10617026.html