标签:标题 开始菜单 fir 接口 示例 导出数据 避免 特殊 下载安装
一.八爪鱼介绍 二.安装八爪鱼 三.采集原理 四.快速入门 五.登陆 六.基本排错 七.提取、导出数据
八爪鱼是一款通用的网页数据采集器,能够采集98%的网页。 可简单快速地将网页数据转化为结构化数据,存储为EXCEL或数据库等多种形式,并且提供基于云计算的大数据云采集解决方案。 八爪鱼作为一款通用的网页数据采集器,并不针对于某一网站某一行业的数据进行采集,而是网页上所能看到或网页源码中有的文本信息,几乎都能采集。
官网:https://www.bazhuayu.com/
1.进入官网注册,因为下载使用要登录才能使用各项功能。 2.请双击OctopusSetup.exe开始安装。 3.安装完成后在开始菜单或者桌面均可以找到八爪鱼采集器快捷方式。 4.启动八爪鱼采集器并登陆。
安装提示:
本软件需要.NET3.5 SP1支持,Win 7已经内置支持,XP系统需要安装,部分Win10系统可能也需要安装。 软件会在安装时自动检测是否安装了.NET 3.5 SP1,如果没有安装则会自动从微软官方在线安装, 国内在线安装速度很慢,建议先从:http://pan.baidu.com/s/1nu5VbTJ 下载安装.NET 3.5 SP1,然后再安装八爪鱼采集器。
八爪鱼采集器的核心原理是:基于Firefox内核浏览器,通过模拟人浏览网页的行为(如打开网页,点击网页中的某个按钮等操作),对网页内容进行全自动提取。 内置火狐内核浏览器,模拟人浏览网页、复制数据的行为, 通过设计工作流程,自动化采集数据。
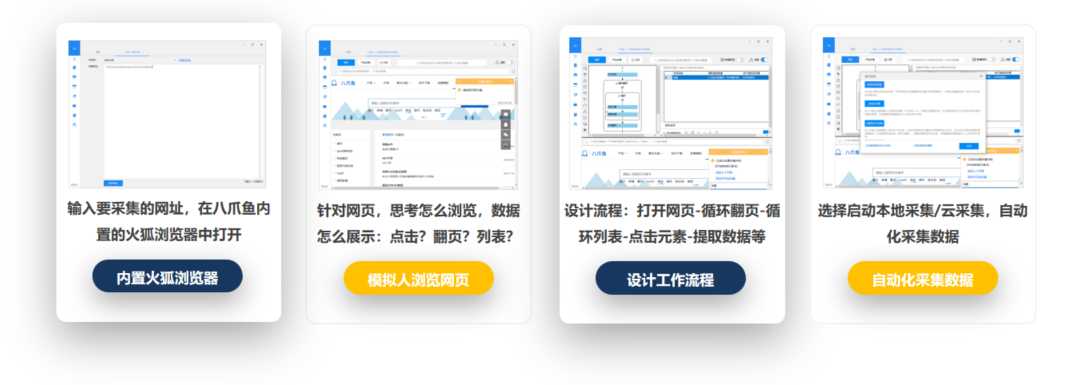
在八爪鱼客户端中,采集和导出数据主要经过以下3个步骤:
1、选择采集模式
2、配置任务
3、配置完成后,选择采集方式,本地采集或云采集
4、采集完成,导出数据

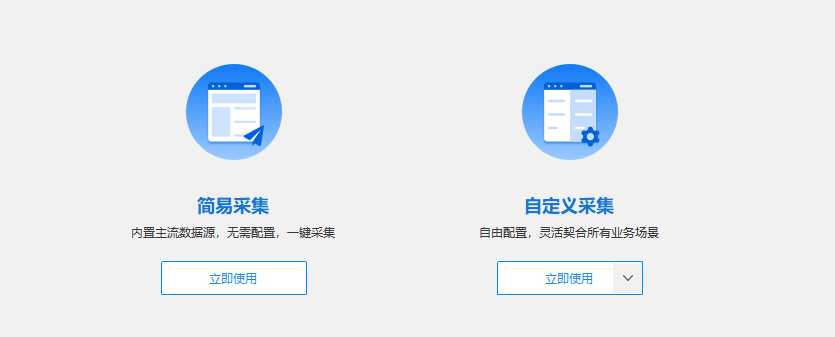
简易模式下内置了国内一些主流网站的采集规则。如果要采集的网站和字段在简易模式的模板中,可直接调用。
注意:可自定义修改参数,以采集所需数据。
建议:
如果不能确定需要多少页数据,建议打开网站看一看每页数据量做简单计算后设置,如果还是不能确定,建议稍微多设置一点翻页,因为多采集的数据可以在Excel当中进行删减,如果少采集了数据,简易模式下只能从头开始重新采集。
智能模式下,只需要输入网址,点击搜索,八爪鱼便会自动采集网页数据并以表格形式呈现出来。可以进行删除或修改字段、翻页、数据导出等操作,以excel格式导出。
试用情况:网页中数据以表格或列表形式呈现的网页。例如电商网站商品列表的商品信息、一些生活服务类的网站等等。
此外,智能模式还可以输入关键词搜索数据。比如搜索“天气”,点击查询后,可以跳转到数多多规则市场。在数多多上可以直接查找到相关的数据或规则。用户可以通过下载,获取数据或规则,规则可以放到八爪鱼中运行,以获取想要的数据。
向导模式,通过简单易懂的语言,指引用户熟悉网页结构,认识八爪鱼采集流程。通过向导模式,可明白规则配置的方法和八爪鱼采集器的采集思路 在智能模式、简易模式不能满足需求的时候,建议优先使用向导模式,使用熟练后可以使用自定义模式进行采集,采集更自由、更效率。 示例网址: https://coll.jd.com/list.html?sub=13321 https://coll.jd.com/list.html?sub=13322
自定义模式是八爪鱼用户使用最多的一种模式,需要自行配置规则,可以实现全网98%以上网页数据的采集。经过采集原理讲解与向导模式试炼,我们大致理解了八爪鱼采集数据的逻辑,接下来需使用自定义采集模式,自行配置规则,抓取网页数据。
使用自定义模式配置规则,抓取数据,涉及打开网页、建立循环列表、建立翻页循环、配置字段、启动采集等多个基础操作。
流程步骤:在八爪鱼采集器中,一共有11个流程设计操作
其中分为常用步骤和进阶步骤
常用步骤:1)打开网页
2)循环翻页
3)循环列表
4)点击元素
5)提取元素
进阶步骤:1)输入文字 2)识别验证码
3)切换下拉选项 4)判断条件
5)移动鼠标到元素上 6)结束循环
7)结束流程
本地采集(单机采集),即使用自己的电脑进行采集。 可以实现绝大多数网页数据的爬取,可以在采集过程中对数据进行初步的清洗。如使用八爪鱼自带的正则工具,利用正则表达式将数据格式化,可在数据源头实现去除空格、筛选日期等多种操作。 其次八爪鱼还提供分支判断功能,可对网页中信息进行是与否的逻辑判断,实现用户筛选需求。
云采集,是使用八爪鱼提供的云服务集群进行数据采集,不占用本地电脑资源。当规则配置好之后,启动云采集,可关掉自己的电脑,实现无人值守。 功能:定时采集,实时监控,数据自动去重并入库,增量采集,自动识别验证码,API接口多元化导出数据。 速度:利用云端多节点并发运行,采集速度将远超于本地采集(单机采集)。 防封:具有多节点,多IP,可避免网站的IP封锁,实现采集数据的最大化。
单网页数据采集 ?单网页 示例网址:http://www.skieer.com/guide/demo/simplemovies2.html ?单网页列表 示例网址:http://www.skieer.com/guide/demo/genremovies2.html ?单网页列表详情 示例网址:http://www.skieer.com/guide/demo/navmovies2.html 分页数据采集 ?分页列表 示例网址:http://www.skieer.com/guide/demo/genremoviespage1.html ?分页列表详情 示例网址:http://www.skieer.com/guide/demo/moviespage1.html
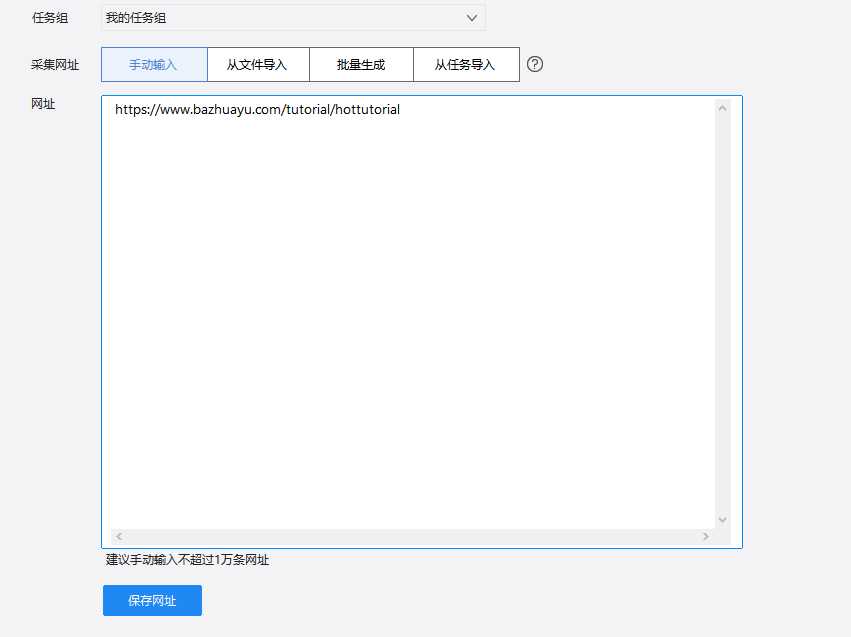
1.点击自定义采集
2.输入网址:https://www.bazhuayu.com/tutorial/hottutorial
3.构建分页,点击分页的下一页,循环点击单个链接
4.构建列表,连续点击两个标题,然后点击循环点击每个元素
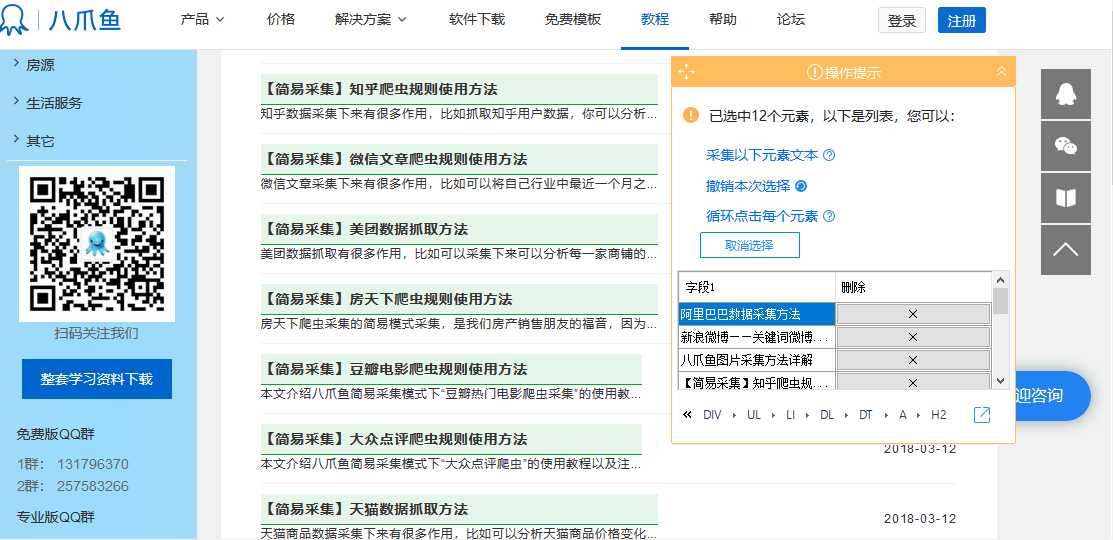
4.设置采集数据字段,点击标题,时间和阅读量,获取标签内容
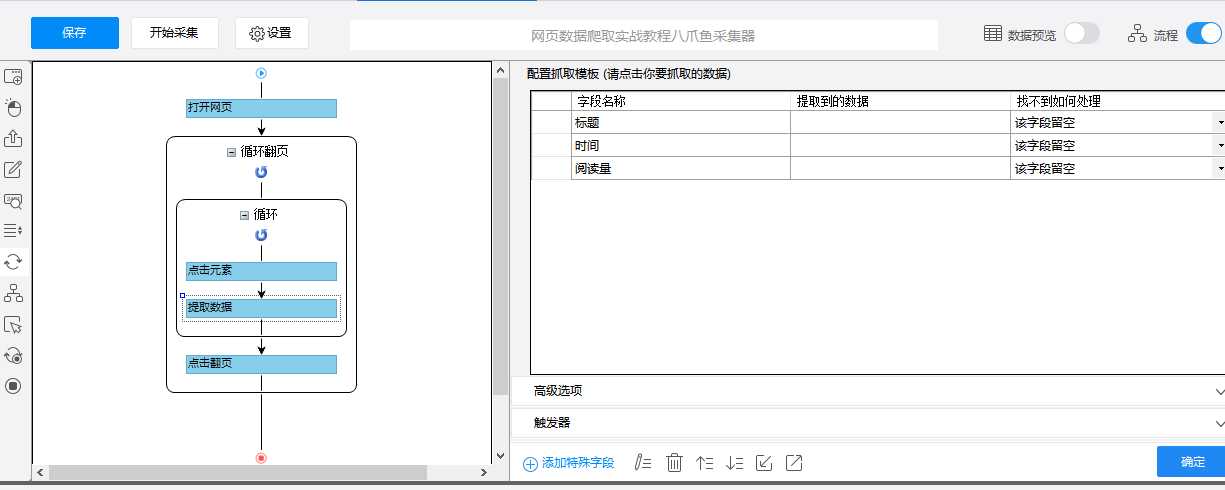
5.查看流程
6.最后点击开始采集,选择本地采集,导出数据
在不同网页中,同一步骤,操作提示框中出现的提示可能不同 因网页源码不同,同一个步骤中,操作提示框中出现的提示可能稍有不同,但逻辑是一样的,请大家灵活处理 例:以循环翻页为例,“循环点击下一页”、“循环点击单个元素”、“循环点击单个链接”从本质上是一样的,都是不断点击翻页按钮进行翻页,但因网页结构不同,提示稍有不同 创建循环的两种方式,具有特殊情况 ?常见情况 列表采集:选中一个元素-选中子元素-选中全部-采集数据 列表及详情采集:选中一个链接-选中全部-循环点击每个链接 ?特殊情况 但有些网页会有特殊情况,需要我们灵活处理,具体请看此视频教程: 分页采集和创建循环的两种方式 http://www.bazhuayu.com/tutorial/fenyecaiji 八爪鱼支持嵌套循环,不支持并列循环 ?针对同一页面只能建立1个循环列表 存在想要采集列表数据,也想要采集详情页数据的情况,错误做法:建立2个循环循环列表 正确做法:建立1个循环列表,循环中包括“提取列表页数据”和“点击元素”步骤
标签:标题 开始菜单 fir 接口 示例 导出数据 避免 特殊 下载安装
原文地址:https://www.cnblogs.com/-wenli/p/10624757.html
