标签:数据 expr 符号表 上下 字符串 现在 结果 前端 任务
9-5+2后缀形式是95-2+
count+1,标识符count被当做一个单元。
op是一个二目运算符,y和z是运算分量的地址,x是存放结果的地址。三地址指令最多一般只执行一个运算,通常是计算、比较或者分支跳转运算。
关键字if和括号这样的词法元素称为终结符号。像exor和stmt这样的变量表示终结符号的序列,他们被称为非终结符号
如果某个非终结符号是某个产生式的头部,我们就说该产生式时该非终结符号的产生式。一个终结符号串是由零个或者多个终结符号组成的序列。零个终结符号组成的串称为空串。
根据文法推导符号串时,首先从开始符号出发。不断将某个非终结符号替换为该非终结符号的某个产生式的体。可以冲开始符号推导得到的所有终结符号串的集合称为该文法定义的语言。
如果非终结符号A是某个内部节点的标号,并且他的子节点标号从左至右分别为x1、x2.那么必然存在产生式A->X1X2,其中x1、x2既可以是终结符号,也可以是非终结符号。作为一个特殊情况,如果A->E是一个产生式,那么一个标号为A的节点可以只有一个标号为e的子节点。

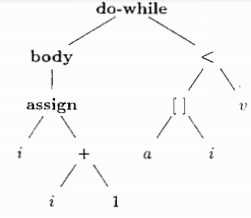
非终结符号stmts产生一个可能为空的语句列表。stmts第二个产生式生成一个空列表e。第一个产生式生成的是一个可能为空的列表再跟上一个语句。分号的放置方式很微妙,他们出现在所有不以stmt结尾的产生式的末尾。这种方法可以避免在if或者while这样的语句后面出现多余的分号。因为if和while语句的最后是一个嵌套的子语句。当嵌套子语句是一个赋值语句或do-while语句时,分号将作为这个子语句的一部分被生成。
将量和程序构造关联起来(比如吧数值类型和表达式相关联)可以基于文法来表示。将属性和文法的非终结符号相关联。文法的各个产生式附加上语义规则,对于语法分析书中的一个节点,如果他和她的子节点之间关系符合某个产生式,那么该产生式对应的规则就描述了如何计算这个节点上的属性。
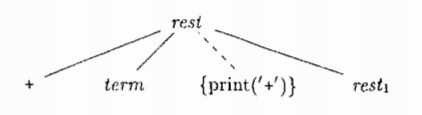
画出一个翻译方案的语法分析树,为每个语义动作构造一个额外的子节点,并使用虚线将他和该产生式头部对应的节点相连。表示上述产生式和语义动作的部分语法分析树。对应的语义动作没有子节点,因此在第一次访问该节点时就会执行这个动作。
语法分析决定如何使用一个文法生成一个终结符号串的过程。尽管在时间中编译器并没有真的构造出这颗树,然而,原则上语法分析器必须能够构造出语法分析树,否则将无法保证翻译的正确性。
对于非终结符号和向前看符号;,我们使用optexpr的产生式,因为;和optexpr仅有的另一个产生式不匹配,那个产生式的体是终结符号expr
这个过程模拟被选中产生式的体,也就是说,从左边开始逐个执行斥期间产生式体中的符号。“执行”一个非终结符号的放法是调用该非终结符号对应的过程,一个与向前看符号匹配的终结符号“执行”放法是读入下一个输入符号。如果在某个点上,产生式体中的终结符号和向前看符号不匹配,那么语法分析器就会报告一个语法错误。
非终结符号R和他的产生式R->aR是右递归的。因为这个产生式的右部,因为这个产生式的右部最后一个符号就是R本身。右递归的产生式会使树向右下方向生长。因为树是向右下生长的,对包含了左结合运算符的表达式就变得比较困难。
左递归消除工作必须小心的进行,以确保消除后的结果爆出语义动作的顺序。+和-都处于产生式的中间,9-5+2会被错误的处理为952+-,即(9-5)+2的表达式
一个词法分析从输入中读取字符,并将他们组成“词法单元对象”,除了用于语法分析的终结符号外,一个词法单元对象还包含一些附加信息。这些信息以属性值得形式出现。
标签:数据 expr 符号表 上下 字符串 现在 结果 前端 任务
原文地址:https://www.cnblogs.com/binarysystemloophole/p/10628299.html