标签:而且 内存 com 线性 变量 比赛 nbsp max 基本
cnn发展史
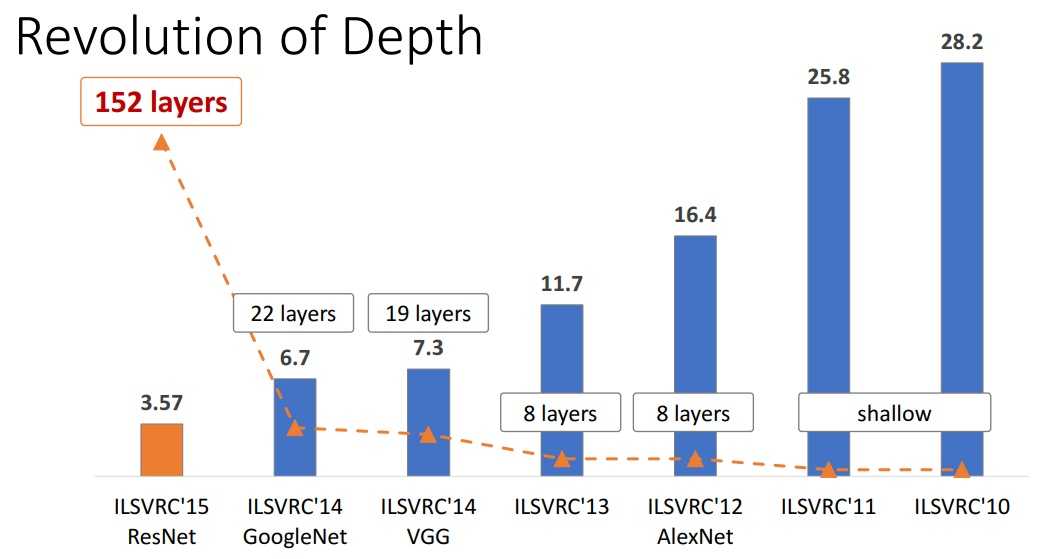
这是imageNet比赛的历史成绩
可以看到准确率越来越高,网络越来越深。
加深网络比加宽网络有效的多,这已是公认的结论。
cnn结构演化图
AlexNet
诞生于2012年,因为当时用了两个GPU(硬件设备差),所以结构图是2组并行
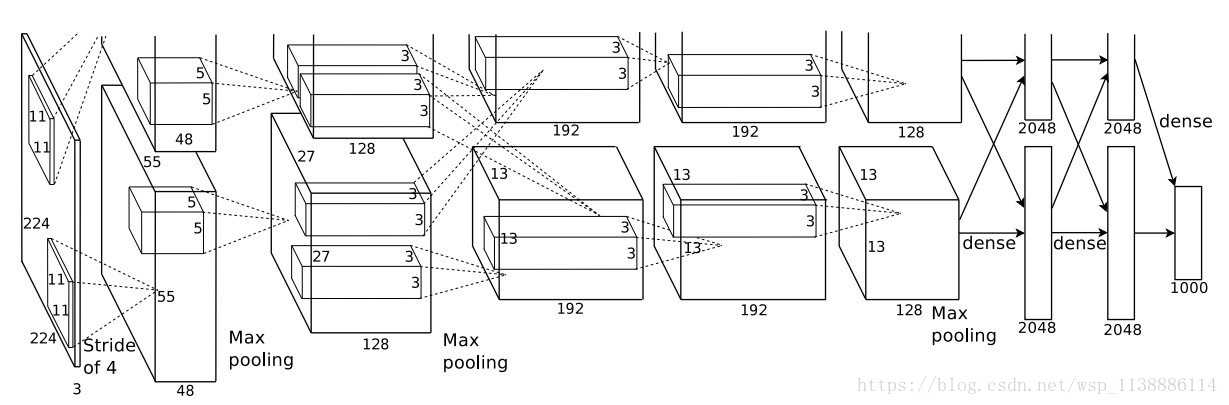
网络结构总共8层,5个卷积层,3个全连接层,最后输出1000个分类
分层结构图
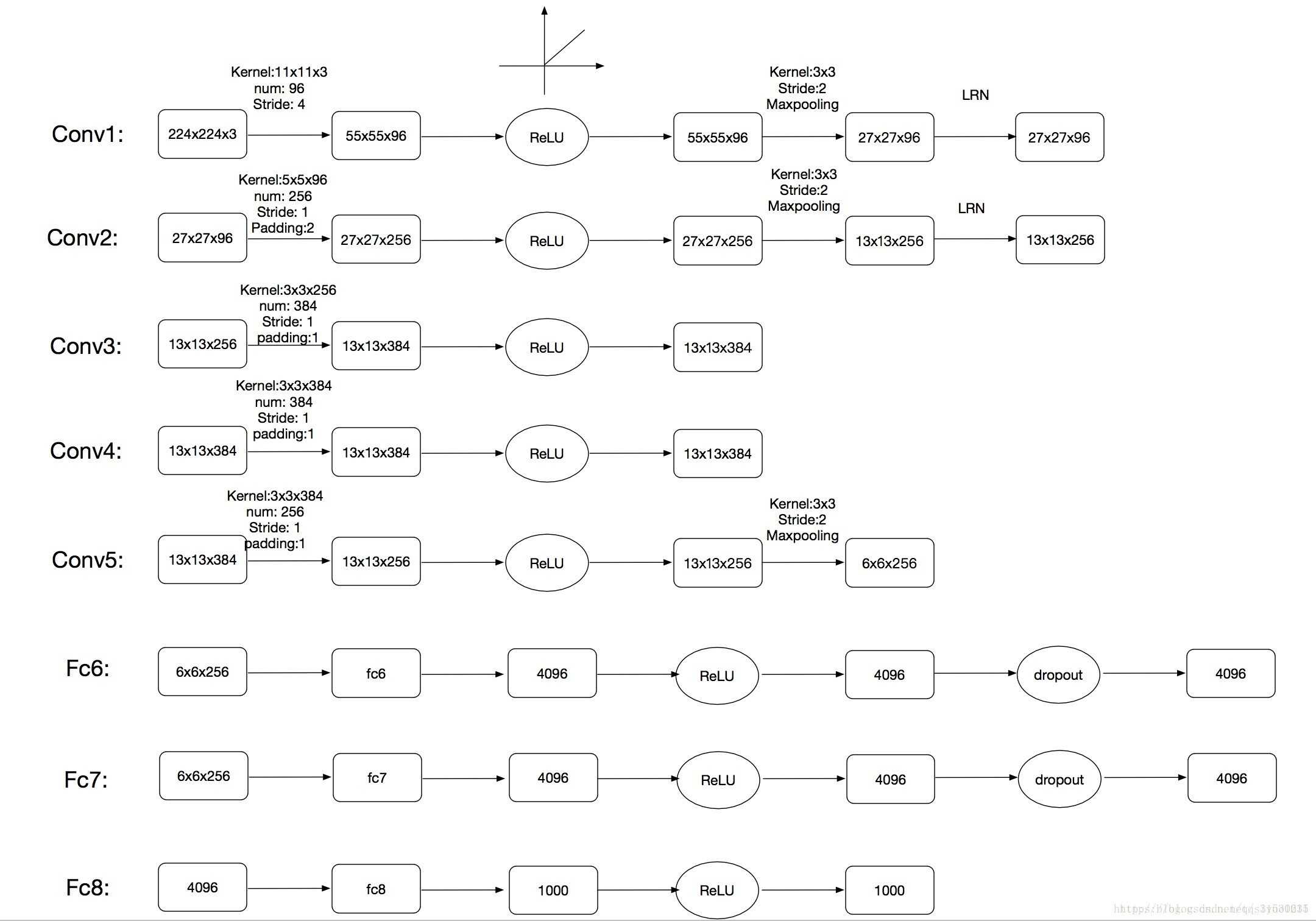
简单解释如下:
conv1:输入为224x224x3,96个shape为11x11x3的卷积核,步长为4,输出55x55x96的特征图,(224-11)/4+1,paddig为valid,故等于55,relu,池化,池化视野3x3,步长为2,这个池化稍有不同,后面解释,然后,lrn,局部归一化,后面解释,输出27x27x96 (这里输入的224在卷积时计算不方便,后来改成了227)
conv2 conv3 conv4 conv5基本类似
fc6:将输出6x6x256展开成一维9216,接4096个神经元,输出4096个值,dropout,还是4096个值
fc7:写的有些问题,第一个框内应该是4096,不打紧
fc8:输出1000个类别
注意几点
1. 重叠池化:一般情况下,我们的池化视野和步长是一样的,但是这里池化视野大于步长,这样就有重叠,故称为重叠池化
2. 局部响应归一化:虽然relu不会梯度饱和,但是笔者认为lrn可以提高模型的泛化能力
AlexNet较之前网络的改进
1. 网络变深
2. relu激活函数
3. 数据增强
通俗理解就是准备更多更全的数据
// 法1:平移图像和水平翻转图像,从原始的256x256的图像中随机提取227x227的块,并且水平翻转,作为训练数据
// 法2:改变训练图像的RGB通道的强度。特别的,本文对整个ImageNet训练集的RGB像素值进行了PCA。对每一幅训练图像,本文加上多倍的主成分,倍数的值为相应的特征值乘以一个均值为0标准差为0.1的高斯函数产生的随机变量。
4. dropout
// 以一定的概率将神经元的输出置为0,就是忽略该神经元的存在,既不前向传递,也不反向传播,这是AlexNet很大的一个创新。
数据增强和dropout都是防止过拟合的。
VGG
诞生于2014年
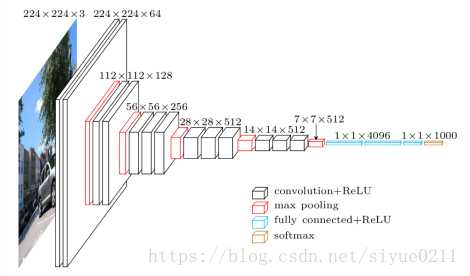
上图是VGG16--黑色框+蓝色框=16
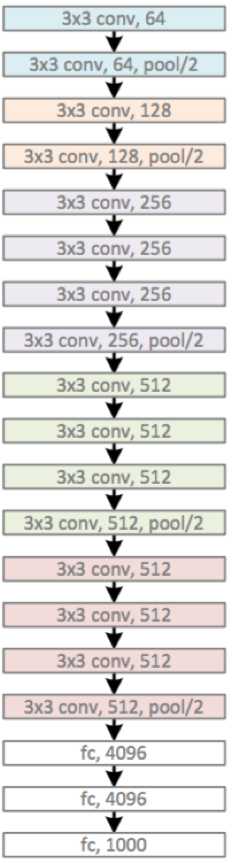
上图为VGG19
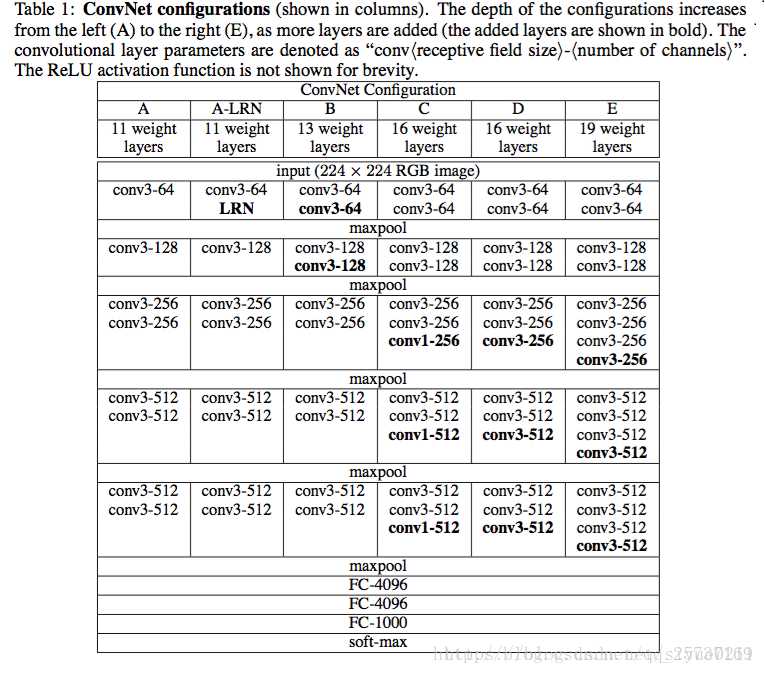
VGG共有6种结构,常用的是D和E,即VGG16和VGG19
VGG网络结构非常规则,共分为5组卷积,每组卷积都使用3x3的卷积核,卷积后都使用2x2的max池化,最后接3个全连接
可以看到C网络的最后3个卷积使用了1x1的卷积,这是什么意思呢?
1x1的卷积其实是对特征的线性变换,主要用来综合特征,这个方法后来被推广解决多种问题。
VGG的优点
1. 使用较小的卷积核,使得参数更少,网络更深
2. 卷积层的堆叠,这样做一可以保证感受视野,即2个3x3的感受野堆叠相当于一个5x5,二是经过多个非线性转换,提取特征的能力更强
3. VGG在训练时,先训练简单的如A网络,然后用A网络的参数(卷积和全连接)初始化后面的复杂网络,更快收敛
4. VGG认为lrn作用不大,去掉了lrn
VGG虽然网络更深,但比AlexNet收敛更快
缺点是占用内存较大
VGG的数据处理
1. 数据标准化
2. 数据增强采用Multi-Scale方法。将原始图像缩放到不同尺寸S,然后再随机裁切224′224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。实践中,作者令S在[256,512]这个区间内取值,使用Multi-Scale获得多个版本的数据,并将多个版本的数据合在一起进行训练。
VGG16的卷积代码
conv1_1 = self._conv_layer(x, 3, 64, "conv1_1") conv1_2 = self._conv_layer(conv1_1, 64, 64, "conv1_2") pool1 = self._max_pool(conv1_2, "pool1") conv2_1 = self._conv_layer(pool1, 64, 128, "conv2_1") conv2_2 = self._conv_layer(conv2_1, 128, 128, "conv2_2") pool2 = self._max_pool(conv2_2, "pool2") conv3_1 = self._conv_layer(pool2, 128, 256, "conv3_1") conv3_2 = self._conv_layer(conv3_1, 256, 256, "conv3_2") conv3_3 = self._conv_layer(conv3_2, 256, 256, "conv3_3") pool3 = self._max_pool(conv3_3, "pool3") conv4_1 = self._conv_layer(pool3, 256, 512, "conv4_1") conv4_2 = self._conv_layer(conv4_1, 512, 512, "conv4_2") conv4_3 = self._conv_layer(conv4_2, 512, 512, "conv4_3") pool4 = self._max_pool(conv4_3, "pool4") conv5_1 = self._conv_layer(pool4, 512, 512, "conv5_1") conv5_2 = self._conv_layer(conv5_1, 512, 512, "conv5_2") conv5_3 = self._conv_layer(conv5_2, 512, 512, "conv5_3") pool5 = self._max_pool(conv5_3, "pool5")
GoogleNet
诞生于2014年,和VGG一同出道,当时是第一名,VGG是第二名,但因其结构复杂,所以没有VGG更常用。
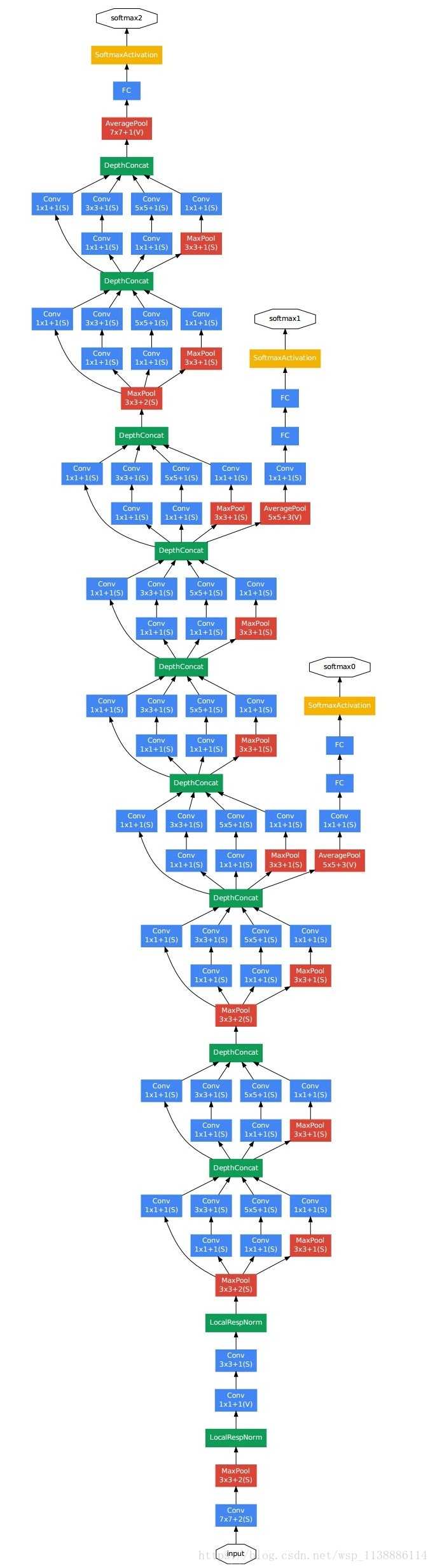
网络太过复杂,不多解释了,这个网络估计也很少被用到。
但是 googlenet 有个很大的创新点,并且被后来很多网络借鉴,就是 global average pooling
global average pooling 一般放在网络最后,替代全连接层。
因为全连接层参数太多,占整个模型参数的比例可以高达90%左右,很难训练,而且参数太多,没有合适的正则化方法,很容易过拟合
global average pooling 做法很简单,就是对每个feature map取全局average,然后每个feature变成了一个数,然后最后接了一个 输出层fc网络
为什么这样,我以后会讲
ResNet
ResNet就借鉴了上面的global average pooling
详见我的博客 https://www.cnblogs.com/yanshw/p/10576354.html
参考资料:
https://blog.csdn.net/Sakura55/article/details/81559881
https://blog.csdn.net/siyue0211/article/details/80092531
https://blog.csdn.net/xbinworld/article/details/61210499
https://blog.csdn.net/ziyouyi111/article/details/80546500 vgg16结构图
https://blog.csdn.net/loveliuzz/article/details/79080194 cnn结构详细教程
https://blog.csdn.net/dcrmg/article/details/79254654 vgg网络结构
标签:而且 内存 com 线性 变量 比赛 nbsp max 基本
原文地址:https://www.cnblogs.com/yanshw/p/10609615.html