标签:cti [1] 地址 释放 filter 范围 访问 连接 mysql主从
目录
其实zk的应用场景都是针对zk可以监听某个节点,并且可以感知到节点的修改或者节点的数据的修改,这样就可以利用根据节点或者节点的数据变化这一特性而应用到很多的场景中,只要抓住这一个特性就可以了。
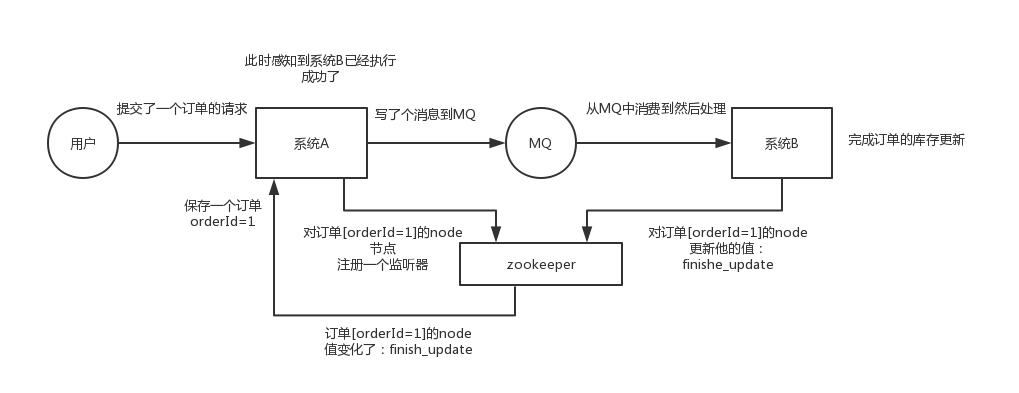
这个其实是zk很经典的一个用法,简单来说,就好比,你A系统发送个请求到mq,然后B消息消费之后处理了。那A系统如何知道B系统的处理结果?用zk就可以实现分布式系统之间的协调工作。A系统发送请求之后可以在zk上对某个节点的值注册个监听器,一旦B系统处理完了就修改zk那个节点的值,A立马就可以收到通知,完美解决。
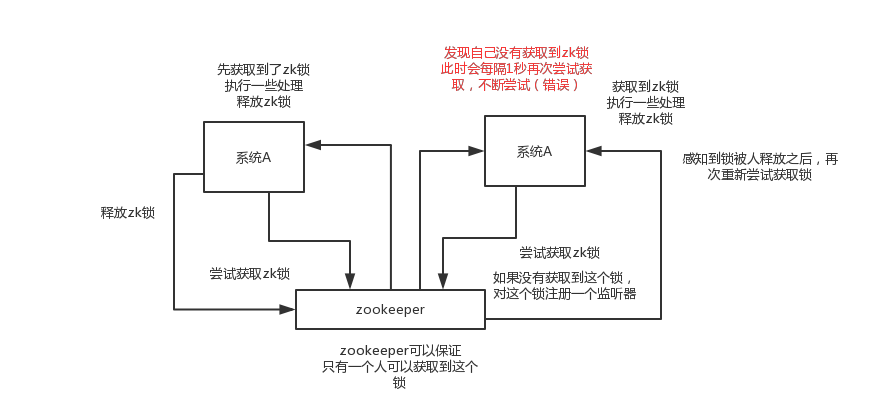
对某一个数据连续发出两个修改操作,两台机器同时收到了请求,但是只能一台机器先执行另外一个机器再执行。那么此时就可以使用zk分布式锁,一个机器接收到了请求之后先获取zk上的一把分布式锁,就是可以去创建一个znode,接着执行操作;然后另外一个机器也尝试去创建那个znode,结果发现自己创建不了,因为被别人创建了。。。。那只能等着,等第一个机器执行完了自己再执行。
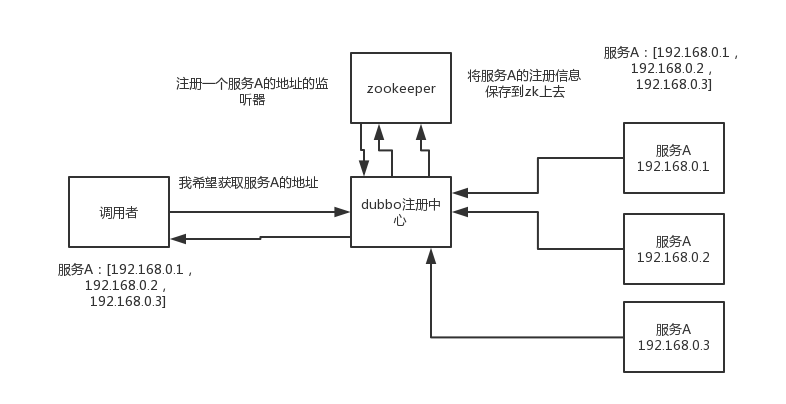
zk可以用作很多系统的配置信息的管理,比如kafka、storm等等很多分布式系统都会选用zk来做一些元数据、配置信息的管理,包括dubbo注册中心不也支持zk么。
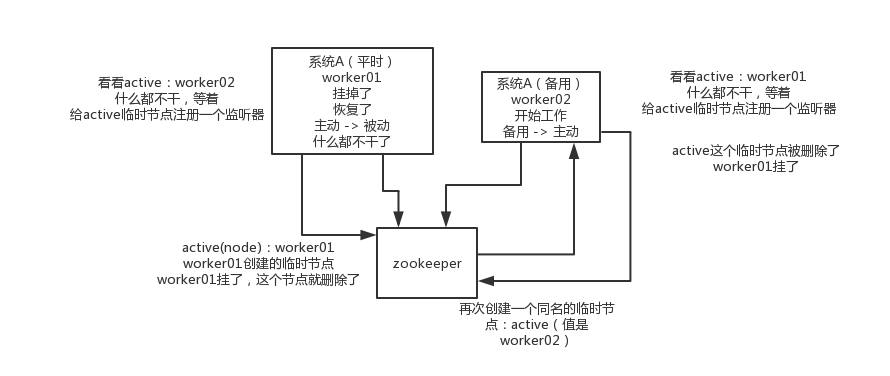
这个应该是很常见的,比如hadoop、hdfs、yarn等很多大数据系统,都选择基于zk来开发HA高可用机制,就是一个重要进程一般会做主备两个,主进程挂了立马通过zk感知到切换到备用进程。
SET my:lock 随机值 NX PX 30000,这个命令就ok,这个的NX的意思就是只有key不存在的时候才会设置成功,PX 30000的意思是30秒后锁自动释放。别人创建的时候如果发现已经有了就不能加锁了。
PX 30000避免一直占有锁,会自动释放锁。
释放锁就是删除key,但是一般可以用lua脚本删除,判断value一样才删除:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
为什么需要判断value的值呢?
因为如果某个客户端获取到了锁,但是阻塞了很长时间才执行完,此时可能已经自动释放锁了,此时可能别的客户端已经获取到了这个锁,要是你这个时候直接删除key的话会有问题,所以得用随机值加上面的lua脚本来释放锁。
但是此种还是存在一定的问题,因为如果是普通的redis单实例,那就是单点故障。或者是redis普通主从,那redis主从异步复制,如果主节点挂了,key还没同步到从节点,此时从节点切换为主节点,别人就会拿到锁。
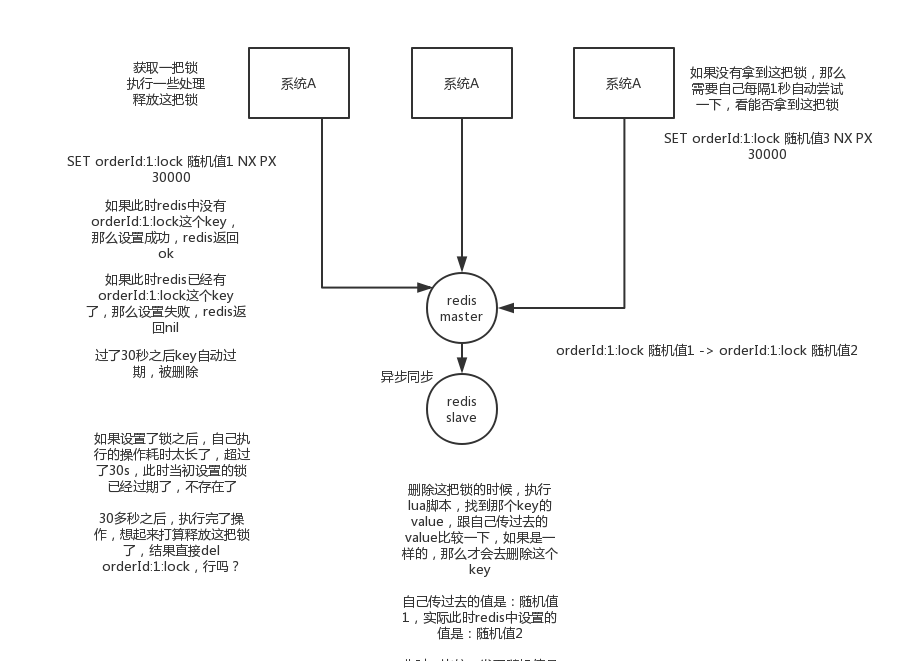
第二种,使用的是RedLock算法(有争议的算法)
这个场景是假设有一个redis cluster,有5个redis master实例。然后执行如下步骤获取一把锁:
1)获取当前时间戳,单位是毫秒
2)跟上面类似,轮流尝试在每个master节点上创建锁,过期时间较短,一般就几十毫秒
3)尝试在大多数节点上建立一个锁,比如5个节点就要求是3个节点(n / 2 +1)
4)客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了
5)要是锁建立失败了,那么就依次删除这个锁
6)只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁
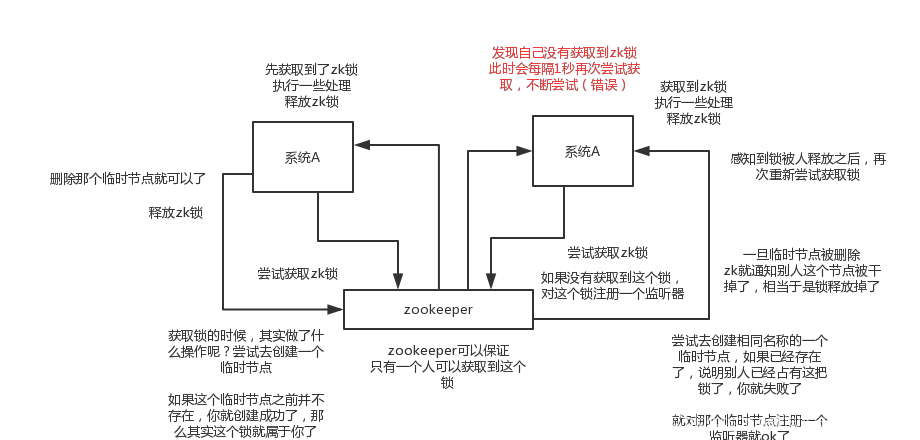
其实可以做的比较简单,就是某个节点尝试创建临时znode,此时创建成功了就获取了这个锁;这个时候别的客户端来创建锁会失败,只能注册个监听器监听这个锁。释放锁就是删除这个znode,一旦释放掉就会通知客户端,然后有一个等待着的客户端就可以再次重新枷锁。
当然也可以基于创建有序临时节点,这样的话,就可以实现公平锁。先创建锁的就可以先获取锁。
redis分布锁,需要字段不断去尝试获取锁,比较消耗性能
zk分布锁,获取不到锁,注册个监听器即可,不需要不断主动尝试获取锁,性能开销较小
并且,如果是redis获取锁的那个客户端bug了或者挂了,那么只能等待超时时间之后才能释放锁;而zk的话,因为创建的是临时znode,只要客户端挂了,znode就没了,此时就自动释放锁
浏览器有个cookie,在一段时间内这个cookie都存在,然后每次发请求过来都带上一个特殊的jsessionid cookie,就根据这个东西,在服务端可以维护一个对应的session域,里面可以放点儿数据。
一般只要你没关掉浏览器,cookie还在,那么对应的那个session就在,但是cookie没了,session就没了。常见于什么购物车之类的东西,还有登录状态保存之类的。
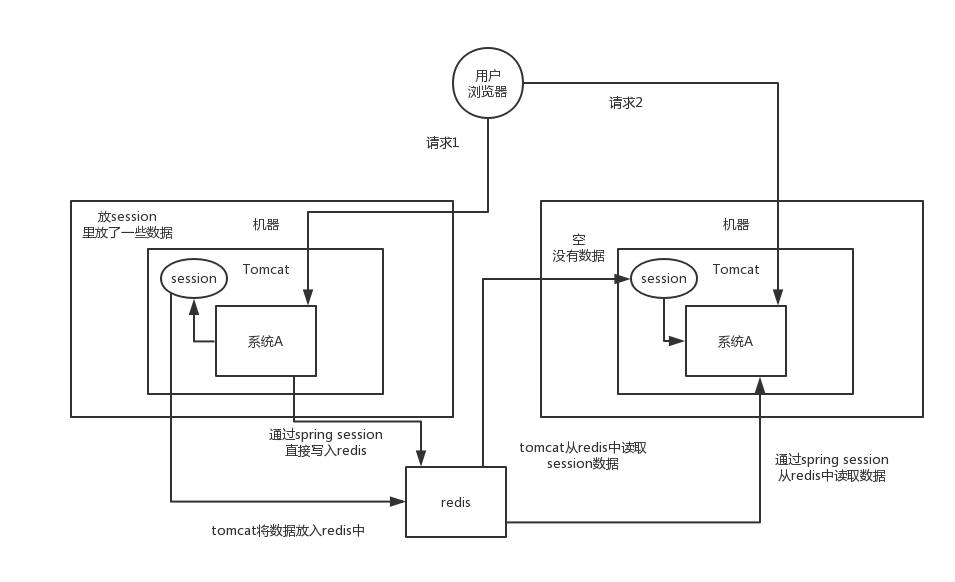
这个其实还挺方便的,就是使用session的代码跟以前一样,还是基于tomcat原生的session支持即可,然后就是用一个叫做Tomcat RedisSessionManager的东西,让所有我们部署的tomcat都将session数据存储到redis即可。
在tomcat的配置文件中,配置一下
<Valve className="com.orangefunction.tomcat.redissessions.RedisSessionHandlerValve" />
<Manager className="com.orangefunction.tomcat.redissessions.RedisSessionManager"
host="{redis.host}"
port="{redis.port}"
database="{redis.dbnum}"
maxInactiveInterval="60"/>搞一个类似上面的配置即可,你看是不是就是用了RedisSessionManager,然后指定了redis的host和 port就ok了。
<Valve className="com.orangefunction.tomcat.redissessions.RedisSessionHandlerValve" />
<Manager className="com.orangefunction.tomcat.redissessions.RedisSessionManager"
host="{redis.host}"
port="{redis.port}"
database="{redis.dbnum}"
maxInactiveInterval="60"/>还可以用上面这种方式基于redis哨兵支持的redis高可用集群来保存session数据,都是可以的的
分布式会话的这个东西重耦合在tomcat中,如果我要将web容器迁移成jetty,难道重新把jetty都配置一遍吗?
spring基本上是一站式解决方案了,spirng cloud做微服务了,spring boot做脚手架了,所以用sping session是一个很好的选择。
pom.xml
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
<version>1.2.1.RELEASE</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.1</version>
</dependency>spring配置文件种
<bean id="redisHttpSessionConfiguration"
class="org.springframework.session.data.redis.config.annotation.web.http.RedisHttpSessionConfiguration">
<property name="maxInactiveIntervalInSeconds" value="600"/>
</bean>
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<property name="maxTotal" value="100" />
<property name="maxIdle" value="10" />
</bean>
<bean id="jedisConnectionFactory"
class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory" destroy-method="destroy">
<property name="hostName" value="${redis_hostname}"/>
<property name="port" value="${redis_port}"/>
<property name="password" value="${redis_pwd}" />
<property name="timeout" value="3000"/>
<property name="usePool" value="true"/>
<property name="poolConfig" ref="jedisPoolConfig"/>
</bean>web.xml
<filter>
<filter-name>springSessionRepositoryFilter</filter-name>
<filter-class>org.springframework.web.filter.DelegatingFilterProxy</filter-class>
</filter>
<filter-mapping>
<filter-name>springSessionRepositoryFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>将一个系统拆分为多个子系统,用微服务dubbo,spring cloud来搞,然后每隔系统连一个数据库,这样原来是一个库,现在多个数据库,在一定程度上提高并发能力
对于应对高并发,一定得用缓存。大部分的高并发场景,都是读多写少你完全可以在数据库和缓存里都写一份,然后读的时候大量走缓存不就得了。毕竟redis轻轻松松单机几万的并发啊。没问题的。所以你可以考虑考虑你的项目里,那些承载主要请求的读场景,怎么用缓存来抗高并发。
可能还是会出现高并发写的场景,比如说一个业务操作里要频繁搞数据库几十次,增删改增删改,疯了。那高并发绝对搞挂系统,要是用redis来承载写那肯定不行,人家是缓存,数据随时就被LRU了,数据格式还无比简单,没有事务支持。所以该用mysql还得用mysql。这个时候可以使用MQ,大量的写请求灌入MQ里,排队慢慢玩儿,后边系统消费后慢慢写,控制在mysql承载范围之内。所以你得考虑考虑你的项目里,那些承载复杂写业务逻辑的场景里,如何用MQ来异步写,提升并发性。MQ单机抗几万并发也是可以的。
能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就将一个数据库拆分为多个库,多个库来抗更高的并发;然后将一个表拆分为多个表,每个表的数据量保持少一点,提高sql跑的性能。
这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都集中在一个库上吧,可以搞个主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库。
es是分布式的,可以随便扩容,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来抗更高的并发。那么一些比较简单的查询、统计类的操作,可以考虑用es来承载,还有一些全文搜索类的操作,也可以考虑用es来承载。
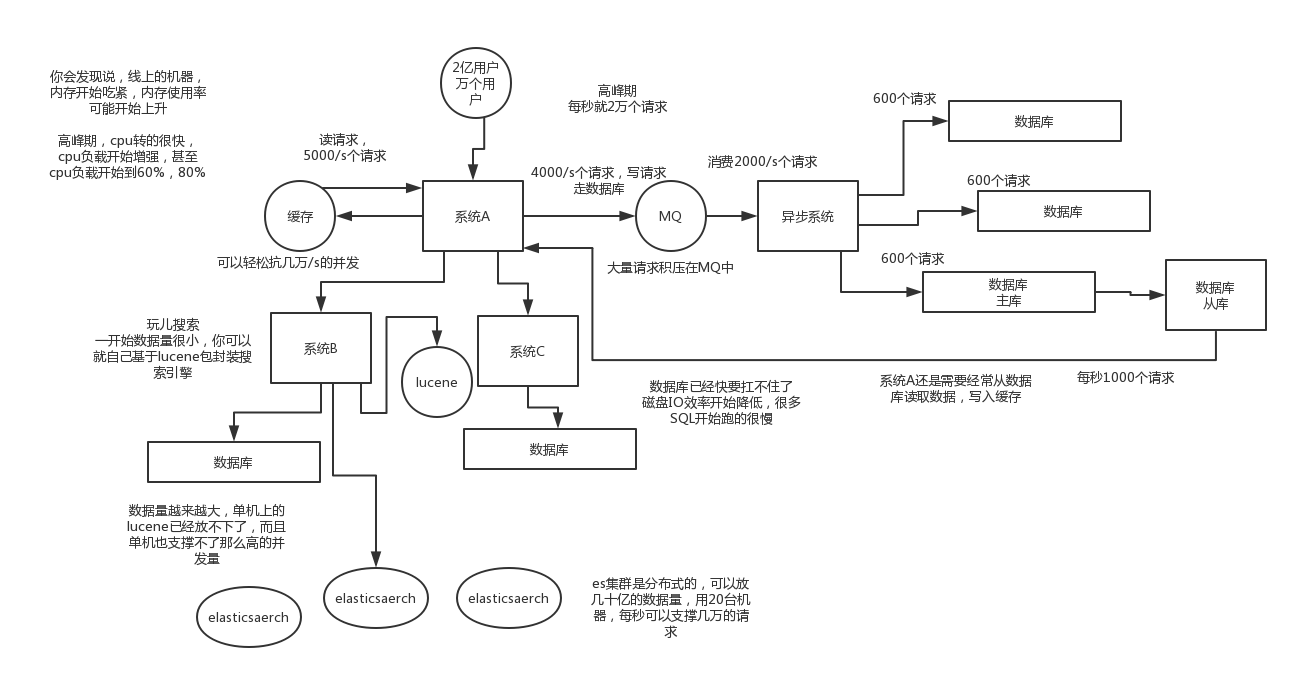
分库:就是一个库一般而言,最多支撑到并发2000,如果并发超过了2000,一般需要扩容了,而且一个健康的单库并发值最好保持在每秒1000左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
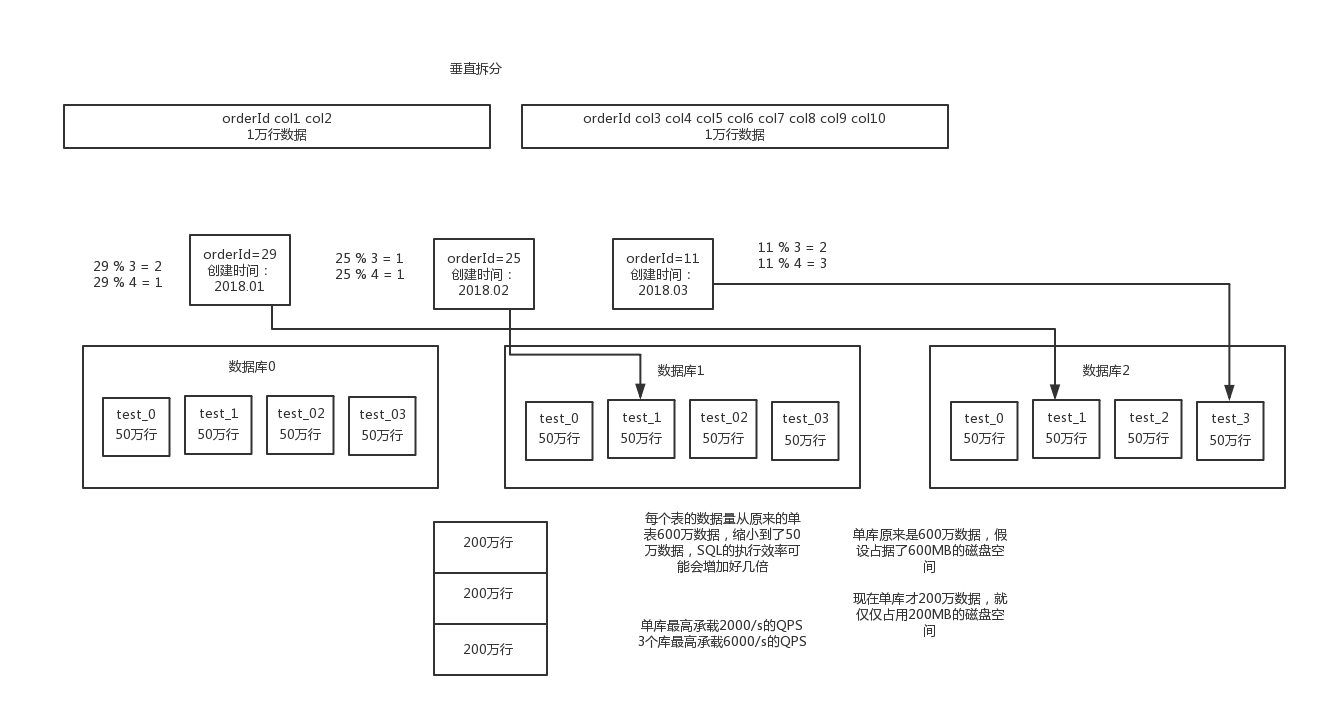
分表:是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户id来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在200万以内。
水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来抗更高的并发,还有就是用多个库的存储容量来进行扩容。
垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
可以是按照id得hash来分(扩容起来特别困难),也可以按照时间的range来分。
(1)停机迁移
系统停掉,然后将单库单表的数据读取出来,然后插入到数据库中间件种。修改系统的配置,
(2)双写迁移
就是在线上系统里面,之前所有写库的地方,增删改操作,都除了对老库增删改,都加上对新库的增删改,这就是所谓双写,同时写俩库,老库和新库。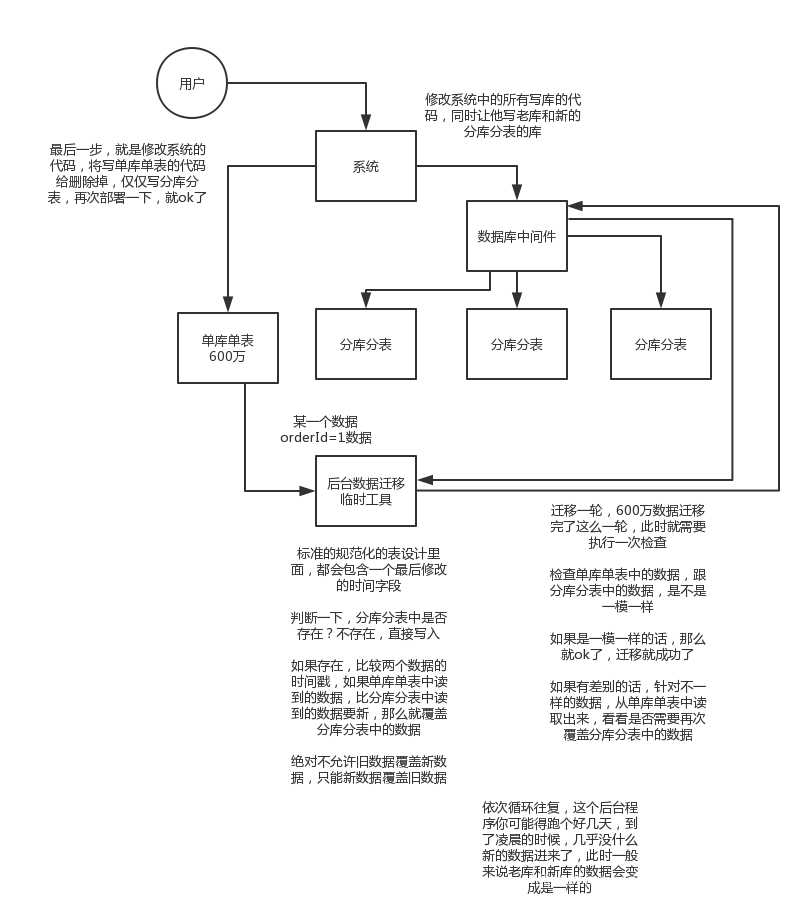
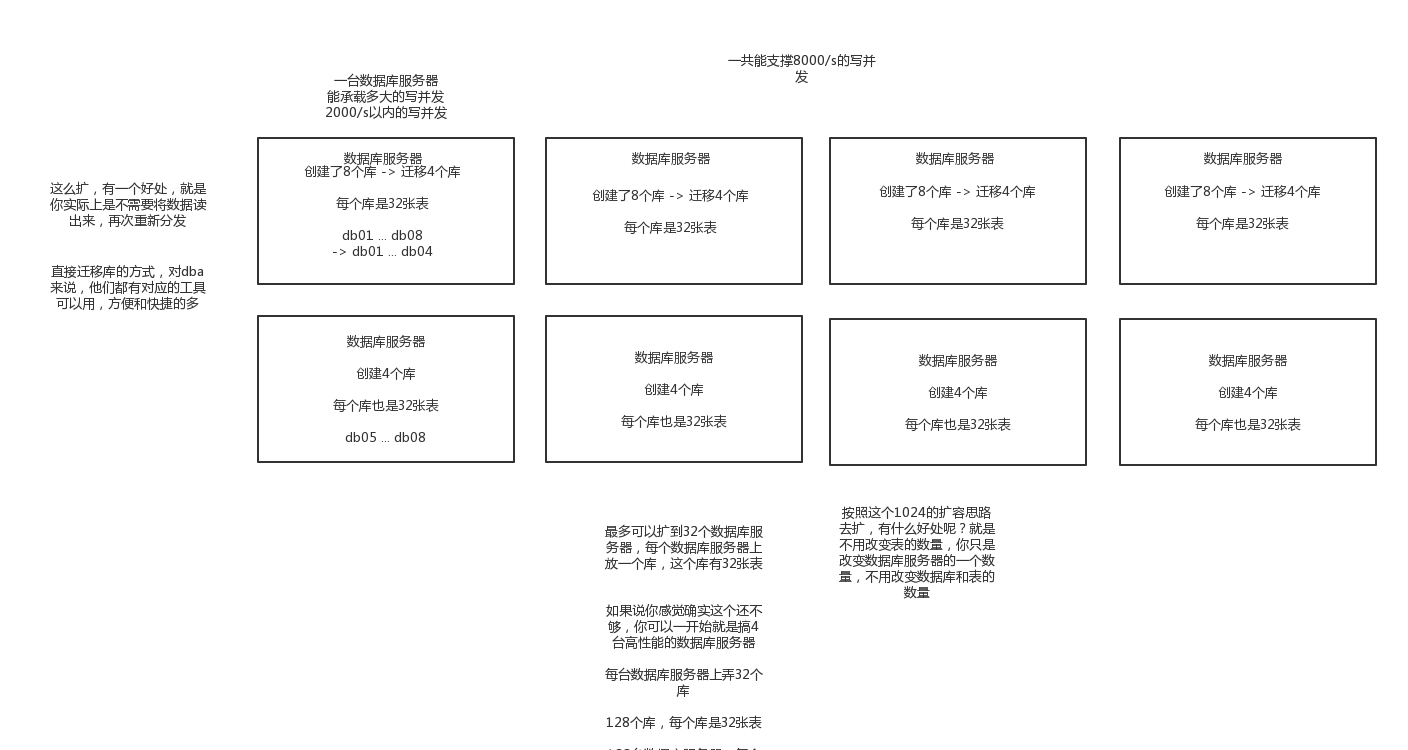
如果扩容了,原来扩容3个库,每个库4个表,现在需要扩容成6个库,每个库需要12个表。
(1)停机扩容(极度不靠谱)
因为既然分库分表就说明数据量实在是太大了,可能多达几亿条,甚至几十亿,你这么玩儿,可能会出问题。
(2)优化方案
扩容的时候,申请增加更多的数据库服务器,装好mysql,倍数扩容,4台服务器,扩到8台服务器,16台服务器。这样的话,路由规则是不需要修改的
由dba负责将原先数据库服务器的库,迁移到新的数据库服务器上去,很多工具,库迁移,比较便捷
然后修改一些配置即可,调整迁移的库所在数据库服务器地址
重新发布系统,上线,原先的路由规则变都不用变,直接可以基于2倍的数据库服务器的资源,继续进行线上系统的提供服务
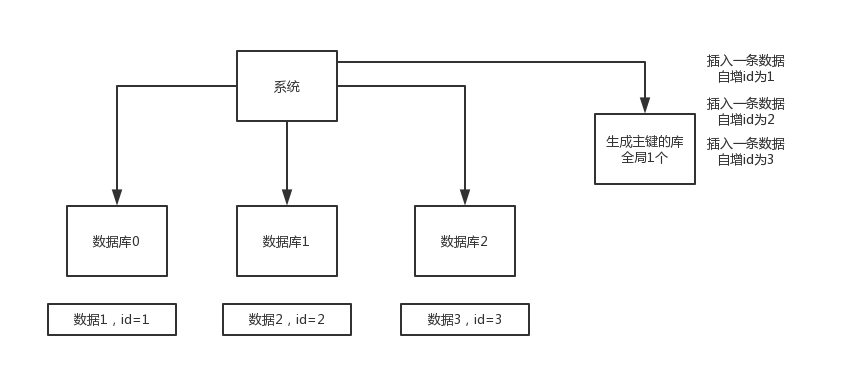
就是指在系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id。拿到这个id之后再往对应的分库分表里去写入。
这个方案的好处就是方便简单,谁都会用;缺点就是单库生成自增id,要是高并发的话,就会有瓶颈的;如果你硬是要改进一下,那么就专门开一个服务出来,这个服务每次就拿到当前id最大值,然后自己递增几个id,一次性返回一批id,然后再把当前最大id值修改成递增几个id之后的一个值;但是无论怎么说都是基于单个数据库。
适合的场景:你分库分表就俩原因,要不就是单库并发太高,要不就是单库数据量太大;除非是你并发不高,但是数据量太大导致的分库分表扩容,你可以用这个方案,因为可能每秒最高并发最多就几百,那么就走单独的一个库和表生成自增主键即可。
并发很低,几百/s,但是数据量大,几十亿的数据,所以需要靠分库分表来存放海量的数据
好处就是本地生成,不要基于数据库来了;不好之处就是,uuid太长了,作为主键性能太差了,不适合用于主键。
适合的场景:如果你是要随机生成个什么文件名了,编号之类的,你可以用uuid,但是作为主键是不能用uuid的。
获取当前时间即可,但是问题是,并发很高的时候,比如一秒并发几千,会有重复的情况,这个是肯定不合适的。基本就不用考虑了。
适合的场景:一般如果用这个方案,是将当前时间跟很多其他的业务字段拼接起来,作为一个id,如果业务上你觉得可以接受,那么也是可以的。你可以将别的业务字段值跟当前时间拼接起来,组成一个全局唯一的编号,订单编号,时间戳 + 用户id + 业务含义编码
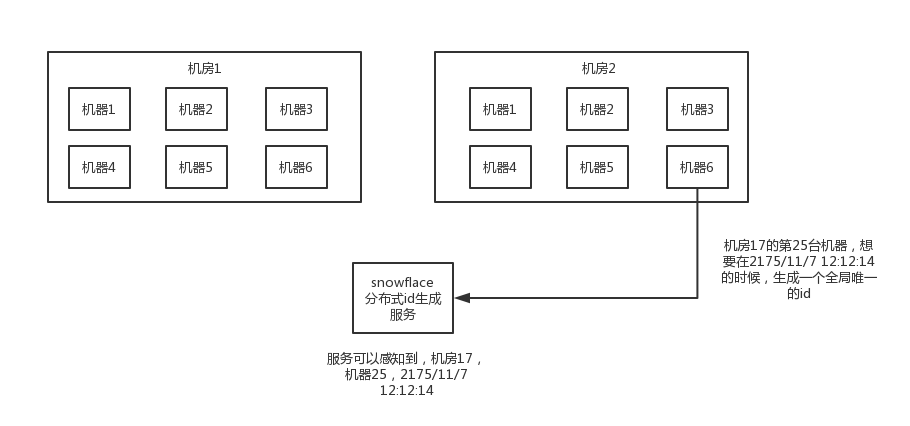
twitter开源的分布式id生成算法,就是把一个64位的long型的id,1个bit是不用的,用其中的41 bit作为毫秒数,用10 bit作为工作机器id,12 bit作为序列号
主库将变更写binlog日志,然后从库连接到主库之后,从库有一个IO线程,将主库的binlog日志拷贝到自己本地,写入一个中继日志中。接着从库中有一个SQL线程会从中继日志读取binlog,然后执行binlog日志中的内容,也就是在自己本地再次执行一遍SQL,这样就可以保证自己跟主库的数据是一样的。
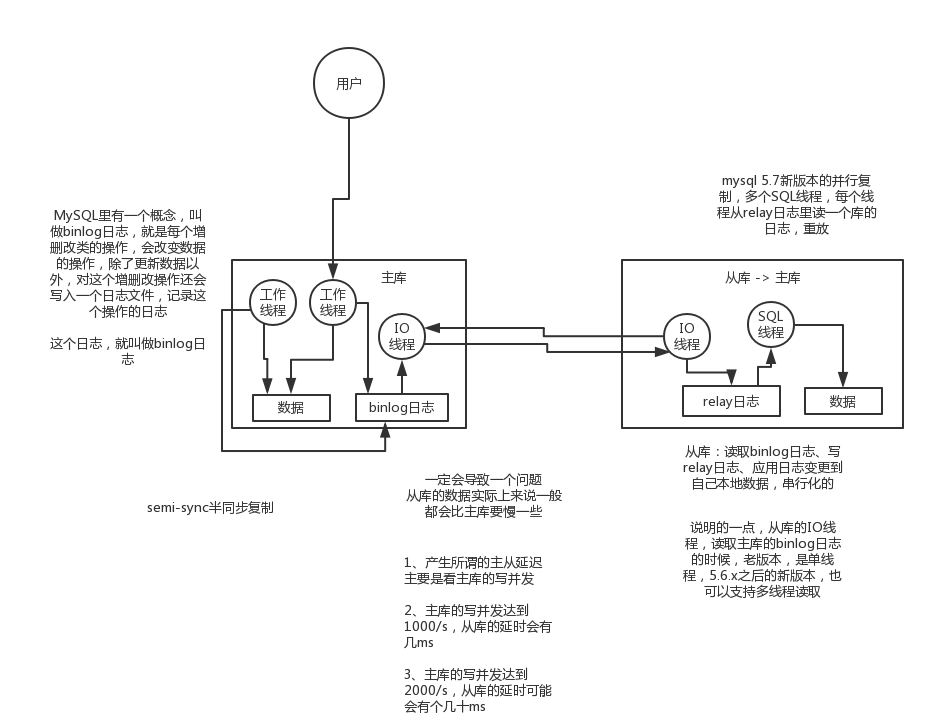
从库同步主库数据的过程是串行化(单线程)的,也就是说主库上并行的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以及串行执行SQL的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
而且这里还有另外一个问题,就是如果主库突然宕机,然后恰好数据还没同步到从库,那么有些数据可能在从库上是没有的,有些数据可能就丢失了。
半同步复:指的就是主库写入binlog日志之后,就会将强制此时立即将数据同步到从库,从库将日志写入自己本地的relay log之后,接着会返回一个ack给主库,主库接收到至少一个从库的ack之后才会认为写操作完成了
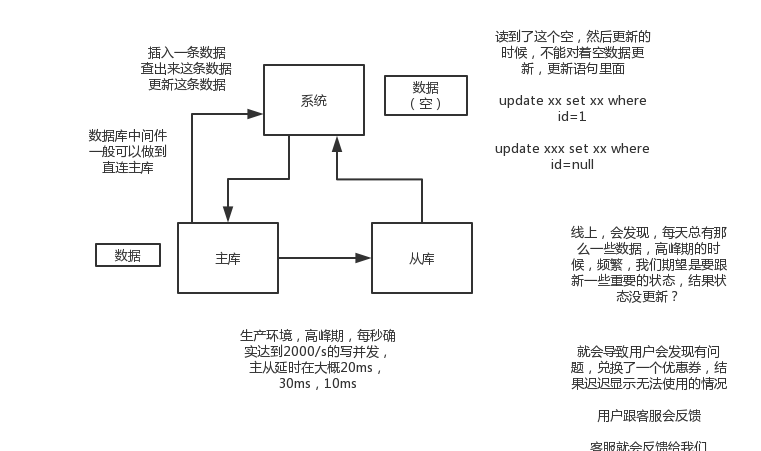
一般来说,如果主从延迟较为严重
(1)、分库,将一个主库拆分为4个主库,每个主库的写并发就500/s,此时主从延迟可以忽略不计
(2)、打开mysql支持的并行复制,多个库并行复制,如果说某个库的写入并发就是特别高,单库写并发达到了2000/s,并行复制还是没意义。28法则,很多时候比如说,就是少数的几个订单表,写入了2000/s,其他几十个表10/s。
(3)、如果确实是存在必须先插入,立马要求就查询到,然后立马就要反过来执行一些操作,对这个查询设置直连主库。不推荐这种方法,你这么搞导致读写分离的意义就丧失了
标签:cti [1] 地址 释放 filter 范围 访问 连接 mysql主从
原文地址:https://www.cnblogs.com/liuligang/p/10631912.html