标签:style blog http color 使用 strong sp 2014 on
1.信息熵
我们用一个生动的例子来说明这个概念:刚好这几天举行世界杯,我们都会猜谁会获得冠军。假设有32支球队,编号从1-32。然后问:“冠军是在1-16中吗?”,不是的话就是在6-32中,一次类推。我们最多需要猜测5次就能猜出谁是冠军(log32)。但事实上,我们可能不需要5次就能猜出来,因为像巴西,德国,意大利这样的强队获得冠军的可能性比其他的要高。然后分组的时候,把少数几支强队放在一组。,以此类推,就不需要5次就能算出来。香农不用次,而是用“比特”(Bit)这个概念来衡量信息量。他指出,以上的准确信息量是: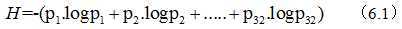
其中pi为各个球队夺冠的概率,H我们称为信息熵。当p相等的时候,H最大,等于5,其他情况下均小于5.
我们来正式定义下熵,给定随机输入向量X(比如球队夺冠的概率),则:
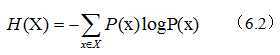
2.信息的作用
故事我们就不讲了,我们知道,一个事务(比如地方的一个战略决定)内部会存在着随机性,也就是不确定性,假定为U,而从外部消除这个不确定性唯一的方法是引入信息I,I的大小取决于U的大小,即I > U。当I < U时,这些信息可以消除一部分不确定性,产生新的不确定性:U’= U - I (6.3)
在网页搜索中,本质就是从大量(几十亿)网页中找到和用户输入相关的网页。几十亿个网页,不确定性U很大,我们的目的就是要减少U,也就是尽量消除不确定性。如果提供的信息不够多,网页量还是很大,这时,正确的做法是挖掘新的隐含信息,比如网页本身的质量信息,如果还不行,就问用户。不正确的做法是在关键词上玩数字和公式游戏,甚至引入人为假设,这和蒙没什么区别。
知道的信息越多,随机事件的不确定性就越小。这些信息可以是直接的,也可以是间接(相关)的。由于这些“相关”信息的存在,在此,我们引入条件熵的概念。
假设X、Y是两个随机变量,X是我们需要了解的。假定我们知道了X的分布P(X),那么就知道了X的熵(6.2),假定我们还知道Y的一些情况,包括X和Y一起出现的概率(即联合概率)以及Y取不同值的前提下X的概率分布(条件概率)。则X在Y下的条件熵为:
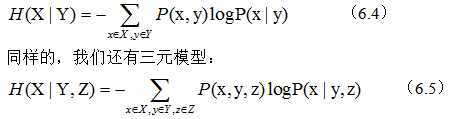
我们可以证明一元模型的信息熵最大,三元最小,即三元模型最好。
综上,其实我们就是讲了信息的作用在于消除不确定性,NLP的大量问题就是找相关的信息。
3.延伸阅读:信息论在信息处理中的应用
3.1 互信息
香农在信息论中,提出了“互信息”的概念,用来量化度量两个随机事件“相关性”。假定两个随机时间X和Y,则他们的互信息定义如下:
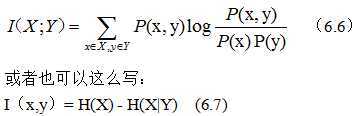
这个公式就比较清楚了,哦~其实就是在有了Y的前提下,对消除X的不确定性所提供的信息量。
在NLP中,我们很容易就能统计出p(x,y),P(x)和p(y)。进而算出互信息。
举个实际应用的例子。美国总统布什(Bush),也可以翻译成灌木丛。我们怎么去正确翻译Bush呢?有人说,加上总统做宾语时,主语就是个人名,但是这样的话,其他多意单词也要有相关的规则,总的下来就得有无数的规则来规范我们的机器翻译结果。而且主席(总统)未必是一个国家的,很多国际组织的都有一个国家作为轮值主席。那么,最好的办法,就是使用互信息了。一般作为总统布什的时候,他总是和总统,华盛顿,美国,白宫一起出现,同样的,作为灌木丛的时候,一般和土壤,植物,野生等一起出现。有了这样的两组词,我们就可以看上下文来判断Bush的意思。
3.2 相对熵
相对熵,又名“交叉熵”。它也用来衡量相关性,但不同的是,它用来衡量两个取值为正的函数的相似性,定义如下:
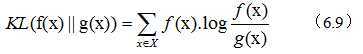
我们不用关心公式怎样,再复杂,也有电脑计算。我们只要记住下面三条结论就好:
1.对两个完全相同的函数,相对熵为0
2.相对熵越大,函数差异越大
3.对于概率分布或者概率密度函数,如果取值均大于0,相对熵可以度量两个随机分布的差异性。
相对熵应用很多,比如可以用来衡量两个常用词(在语法和语义上)在不同文本中的概率分布,以判断那他们是否同义;或者根据两篇文章中不同词的分布,看看他们的内容是否相近等。利用相对熵,可以得到信息检索中一个最重要的概念:TF-IDF。
信息熵是对不确定性的衡量,因此可以向向它能直接衡量统计语言模型的好坏。因为有了上下文关系,所以我们应该用条件熵。若再考虑从训练语料和真实应用的文本中得到的概率函数有偏差,就要引入相对熵。贾里尼克从条件熵和信息熵出发,定义了语言模型复杂度的概念。用于衡量语言模型的好坏。
标签:style blog http color 使用 strong sp 2014 on
原文地址:http://www.cnblogs.com/KingKou/p/4036197.html