标签:mem back 分析 syn color strong 内存 访问 point
一、什么是逃逸
逃逸是指在某个方法之内创建的对象,除了在方法体之内被引用之外,还在方法体之外被其它变量引用到;这样带来的后果是在该方法执行完毕之后,该方法中创建的对象将无法被GC回收,由于其被其它变量引用。正常的方法调用中,方法体中创建的对象将在执行完毕之后,将回收其中创建的对象;故由于无法回收,即成为逃逸。
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,称为方法逃逸。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
方法逃逸的几种方式如下:
public class EscapeTest { public static Object obj; public void globalVariableEscape() { // 给全局变量赋值,发生逃逸 obj = new Object(); } public static StringBuffer craeteStringBuffer(String s1, String s2) { StringBuffer sb = new StringBuffer(); sb.append(s1); sb.append(s2); return sb; //方法返回值,发生逃逸 } public void instanceEscape() { // 实例引用发生逃逸 test(this); } }
如果开启逃逸分析,那么即时编译器(Just-in-time Compilation,JIT)就可以对代码做如下优化:
(1)同步省略(锁消除)。如果确定一个对象不会逃逸出线程,即对象被发现只能从一个线程被访问到,无法被其它线程访问到,那该对象的读写就不会存在竞争,对这个变量的同步措施就可以消除掉。
(2)将堆分配转化为栈分配。栈上分配就是把方法中的变量和对象分配到栈上,方法执行完后自动销毁,而不需要垃圾回收的介入,从而提高系统性能。。
(3)分离对象或标量替换。Java虚拟机中的原始数据类型(int,long等数值类型以及reference类型等)都不能再进一步分解,它们就可以称为标量。相对的,如果一个数据可以继续分解,那它称为聚合量,Java中最典型的聚合量是对象。如果逃逸分析证明一个对象不会被外部访问,并且这个对象是可分解的,那程序真正执行的时候将可能不创建这个对象,而改为直接创建它的若干个被这个方法使用到的成员变量来代替。拆散后的变量便可以被单独分析与优化, 可以各自分别在栈帧或寄存器上分配空间,原本的对象就无需整体分配空间了。
在Java代码运行时,通过JVM参数可指定是否开启逃逸分析,
-XX:+DoEscapeAnalysis : 表示开启逃逸分析
-XX:-DoEscapeAnalysis : 表示关闭逃逸分析 从jdk 1.7开始已经默认开始逃逸分析,如需关闭,需要指定-XX:-DoEscapeAnalysis
二、同步省略(锁消除)
在动态编译同步块的时候,即时编译器(Just-in-time Compilation,JIT)可以借助逃逸分析来判断同步块所使用的锁对象是否只能够被一个线程访问而没有被发布到其他线程。如果同步块所使用的锁对象通过这种分析被证实只能够被一个线程访问,那么JIT编译器在编译这个同步块的时候就会取消对这部分代码的同步。这个取消同步的过程就叫同步省略,也叫锁消除。
如以下代码:
public void f() { Object hollis = new Object(); synchronized(hollis) { System.out.println(hollis); } }
代码中对hollis这个对象进行加锁,但是hollis对象的生命周期只在f()方法中,并不会被其他线程所访问到,所以在JIT编译阶段就会被优化掉。优化成:
public void f() { Object hollis = new Object(); System.out.println(hollis); }
所以,在使用synchronized的时候,如果JIT经过逃逸分析之后发现并无线程安全问题的话,就会做锁消除。
-XX:+EliminateLocks开启锁消除(jdk1.8默认开启,其它版本未测试) -XX:-EliminateLocks 关闭锁消除 锁消除基于分析逃逸基础之上,开启锁消除必须开启逃逸分析
三、标量替换
标量(Scalar)是指一个无法再分解成更小的数据的数据。Java中的原始数据类型就是标量。相对的,那些还可以分解的数据叫做聚合量(Aggregate),Java中的对象就是聚合量,因为他可以分解成其他聚合量和标量。
在JIT阶段,如果经过逃逸分析,发现一个对象不会被外界访问的话,那么经过JIT优化,就会把这个对象拆解成若干个其中包含的若干个成员变量来代替。这个过程就是标量替换。
public static void main(String[] args) { alloc(); } private static void alloc() { Point point = new Point(1,2); System.out.println("point.x="+point.x+"; point.y="+point.y); } class Point{ private int x; private int y; }
以上代码中,point对象并没有逃逸出alloc方法,并且point对象是可以拆解成标量的。那么,JIT就会不会直接创建Point对象,而是直接使用两个标量int x ,int y来替代Point对象。
以上代码,经过标量替换后,就会变成:
private static void alloc() { int x = 1; int y = 2; System.out.println("point.x="+x+"; point.y="+y); }
可以看到,Point这个聚合量经过逃逸分析后,发现他并没有逃逸,就被替换成两个聚合量了。那么标量替换有什么好处呢?就是可以大大减少堆内存的占用。因为一旦不需要创建对象了,那么就不再需要分配堆内存了。
标量替换为栈上分配提供了很好的基础。
四、栈上分配
在Java虚拟机中,对象是在Java堆中分配内存的,这是一个普遍的常识。但是,有一种特殊情况,那就是如果经过逃逸分析后发现,一个对象并没有逃逸出方法的话,那么就可能被优化成栈上分配。这样就无需在堆上分配内存,也无须进行垃圾回收了。
public class OnStackTest { public static void alloc(){ byte[] b=new byte[2]; b[0]=1; } public static void main(String[] args) { long b=System.currentTimeMillis(); for(int i=0;i<100000000;i++){ alloc(); } long e=System.currentTimeMillis(); System.out.println(e-b); } }
开启逃逸分析,执行的时间为4毫秒。如下图:

关闭逃逸分析,执行的时间为618毫秒,并且伴随的大量的GC日志信息。如下图:
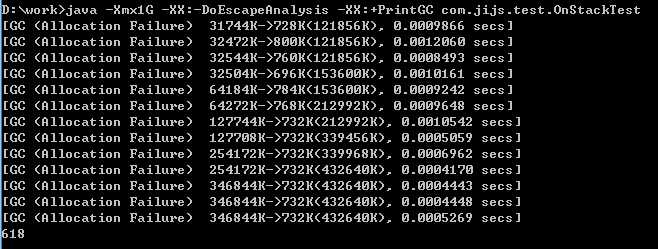
开启逃逸分析,对象没有分配在堆上,没有进行GC,而是把对象分配在栈上。
关闭逃逸分析,对象全部分配在堆上,当堆中对象存满后,进行多次GC,导致执行时间大大延长。堆上分配比栈上分配慢上百倍。
参考:
1、深入分析JVM逃逸分析对性能的影响 https://blog.csdn.net/w372426096/article/details/80938788
2、深入分析JVM逃逸分析对性能的影响 https://blog.csdn.net/jijianshuai/article/details/73740024
标签:mem back 分析 syn color strong 内存 访问 point
原文地址:https://www.cnblogs.com/aiqiqi/p/10650394.html