标签:运行 ttf enc pre create lse pyplot name 输入
一、准备
1.首先 先用cmd 安装 jieba库,输入 pip install jieba
2.其次 本次要用到wordcloud库和 matplotlib库,也在cmd输入pip install matplotlib和pip install wordcloud
二、安装完之后,输入如下代码
1 from wordcloud import WordCloud 2 import matplotlib.pyplot as plt 3 import jieba 4 def create_word_cloud(filename): 5 text = open("[轻之国度][川原砾][刀剑神域][01][艾恩葛朗特 上].txt","r",encoding=‘GBK‘).read() #打开自己想要的文本 6 wordlist = jieba.cut(text, cut_all=True) # 结巴分词 7 wl = " ".join(wordlist) 8 wc = WordCloud( #设置词云 9 background_color="white", # 设置背景颜色 10 max_words=20, # 设置最大显示的词云数 11 font_path=‘C:/Windows/Fonts/simfang.ttf‘, # 索引在C盘上的字体库 12 height=500, 13 width=500, 14 max_font_size=150, # 设置字体最大值 15 random_state=150, # 设置有多少种随机生成状态,即有多少种配色方案 16 ) 17 myword = wc.generate(wl) # 生成词云 18 plt.imshow(myword) # 展示词云图 19 plt.axis("off") 20 plt.show() 21 wc.to_file(‘img_book.png‘) # 把词云保存下 22 txt=open("[轻之国度][川原砾][刀剑神域][01][艾恩葛朗特 上].txt","r",encoding=‘GBK‘).read() #打开自己想要的文本 23 words=jieba.lcut(txt) 24 counts={} 25 for word in words: 26 if len(word)==1: #排除单个字符的分词结果 27 continue 28 else : 29 counts[word]=counts.get(word,0)+1 30 items=list(counts.items()) 31 items.sort(key=lambda x:x[1],reverse=True) 32 for i in range(20): 33 word,count=items[i] 34 print ("{0:<20}{1:>5}".format(word,count)) 35 if __name__ == ‘__main__‘: 36 create_word_cloud(‘[轻之国度][川原砾][刀剑神域][01][艾恩葛朗特 上]‘)
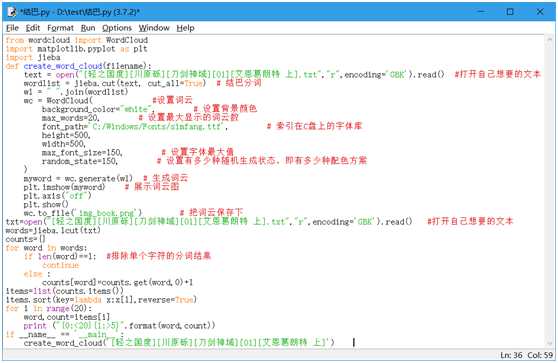
输入之后的界面按下F5
三、运行完毕出现的效果图
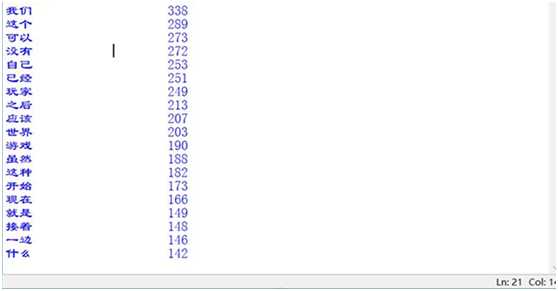
这里是搜索全文的前20个高频词
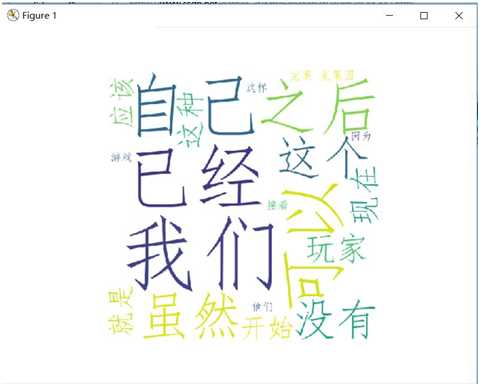
云词展示 完毕
标签:运行 ttf enc pre create lse pyplot name 输入
原文地址:https://www.cnblogs.com/qq1079179226/p/10652404.html