标签:就是 序列化 指定 cal 因此 over 信息 orm 不难
学习Storm已经有两周左右的时间,但是认真来说学习过程确实是零零散散,遇到问题去百度一下,找到新概念再次学习,在这样的一个循环又不成体系的过程中不断学习Storm。
前人栽树,后人乘凉,也正是因为网上有这样多热心的人,分享自己的见解,才能够让开发变得更简单。也正是基于这个目的,同时公司恰好是做大数据的,预计还有相当长的时间需要深入Storm,决定写一下Storm系列相关知识。
在大数据处理中,目前来看,有这样三种主要的数据处理方式,以hadoop为主的大数据批处理框架, 以Storm为主的实时计算流处理框架, 还有以Spark为主的微型批处理流框架。
解释可能不太到位, 但是Storm最重要的特点也就是, 实时, 流处理。
在这里通过一个网络上比较常见的案例来作为开始吧, 假设我们需要对一篇文章,一本书中的所有单词按照首字母进行统计,统计每种首字母的单词按照长度划分进行统计,也就是等首字母,等长度的单词,究竟出现了多少次,应该怎样做呢?
无论是以怎样的开发框架,模式来进行思考,我们很容易想到这样一个处理步骤:
用IO流从文章中不断读取内容作为输入,然后提取每个单词的首字母,判断单词的首字母,先按照首字母分组,再将分组过后的数据一个个统计其长度,对应的数值即可。
那么一点点来进行拆分。
首先需要提到的一个概念就是拓扑。不难将上述概念转换成如下流程图:
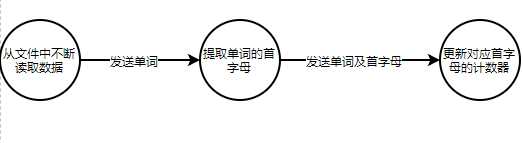
这样的每一个圆都代表一个简单的处理或计算过程,每条边就代表将上一个节点处理结束的数据发送到下一个节点,这样一个数据流向。
而拓扑正是这样一个计算图,结点代表一些计算,数据处理逻辑,边代表在结点之间数据的传递,由结点和边所构建出来的这个整体,完成一个完整功能的整体,就被称作是拓扑。
元组是拓扑之间传输数据的形式,它本身是一个有序的数值序列。因为是有序的数值序列,就意味着在特定的index有着特定的含义,而这个含义又或者字段名称(field)就是由使用者自己定义的。
任何一个节点都可以创造元组,并发送给任意其他一个或多个节点,而这个过程就被称作是发射(emit)一个元组。
那么就会有这样一个问题,在元组中并没有对数据类型做出强制限定,对于处在不同机器,或不同进程的节点,一般是需要通过网络发送,或是socket在本机间发送,是如何发送java中的对象呢?答案是通过序列化的方式。而在这一点,我们在后续的篇章再提。
流就是一个“无边界的元组序列”, 元组是基本的传输单位,当元组在两个节点之间源源不断的发送,就是所谓的流。
而除了根节点是从数据源不断读取数据之外,其他的节点都可以从任意多个节点接收数据,而每一个节点都可以向任意多个节点发送数据。
Spout的主要功能是从数据源中读取数据,并向其他节点发送数据,数据源可以有多种,文件,消息队列,数据库。
Spout中并不包含对数据的处理逻辑,所需要做的是,从数据源读取,发送。但也并非完全意义上的什么都不做,一般来说,在这一步会选择完成反序列化这一工作,甚至更近一步的,将接收到的数据转换成相应的基本Java对象发射出去,之所以说是基本的,也意味着仅仅是将字符串或其他形式的数据,转换成对象,并不做任何特殊处理。
为什么Spout不做任何的数据处理功能呢?在这里是不是连对象转换也不要有比较好呢?
个人理解,由于Spout是整个数据处理的第一环,大批量的数据流入并从当前节点分发,在nextTuple中不能有阻塞是基本要求。在这一环节做出的操作越多,对性能的影响越大。至于对象转换, 由于这是对数据的基本操作,也就是放在任何节点都需要执行的东西,更何况,如果是自己设计, 如果数据被原样发出,会在下一节点做出数据转换后,进一步发送。相当于做了一次无效的发送操作。
所以,仍需考量。
不同于spout只监听数据源,bolt可以完成从输入流的元组接收, 转换, 处理, 发射功能。是我们的topology中真正的数据处理节点。
在我们的例子中有这样两个bolt:
提取单词首字母:所做的工作是,接收单词,获取单词首字母,并发送到下一节点。
数据更新节点:接收单词,判断首字母标识字段, 判断长度, 更新计数器。
我们会注意到, 接收, 处理, 或许发送, 是bolt的所有功能。
就接收来说,我们的数据来源可能并不止一个,可能是Spout,也可能是其他bolt。 对于发送来说, 我们的目的地也可能不止一个,既可以是bolt, 也有可能是其他拓扑的Spout。 bolt 可以是多入多出的。
就现在而言,我们知道了:
一个拓扑包含大量的节点和边
节点有Spout或bolt
边代表节点间的元组流
一个元祖是一个有序的数值列表,每个数组都被赋予一个命名
一个数据流失一个在spout 和 bolt 或两个bolt之间的无边界元组序列。
spout是拓扑的数据源
bolt接收输入流,做出数据处理,可能会发送数据给下一节点。
在实际中,每个spout可能会同时运行一个或多个独立的实例,并行的进行相应的数据处理。
我们还需要关注一下下其中的一个策略性问题, 即流分组, 当数据从一个节点发送到另一个节点是以流的形式进行发送。
我们已经知道处在当前节点的下游,可能存在多个不同种类的bolt, 也可能存在同一bolt的多个实例。数据流是怎样分配的呢?
对待第一种情况, 不同种类的bolt,比较好处理, 我们为每一种类型的流,就案例而言,如果我们设计了多种bolt, 分别处理相应字母开头的单词, 那么在spout发送时, 就可以指定流的名字, bolt接收时,不同的bolt实例去接收不同的流即可。
而第二种情况即是流分组, 最常见的是随机分组, 它可以保证每个bolt接收到的数据量基本一致,负载均衡。但是,并不是绝对均衡,因为采取的是随机的方式,并不是轮询策略。
第二种比较常见的方式是, 字段分组, 它可以保证特定字段上的值相同的元组发射到同一个bolt实例。
流分组策略有多种,在后续会有章节提到。
相应代码已经上传至:
git@github.com:zyzdisciple/storm_study.git
需要提到的一点是:在运行topology时,可能会打印的东西过多,即使加了debug false也不能够改变这一问题,需要在当前项目的 resources中加入, log4j2.xml 更改打印Level;
log4j2.xml 在 storm-core jar包中自带。
<?xml version="1.0" encoding="UTF-8"?>
<configuration monitorInterval="60">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%-4r [%t] %-5p %c{1.} - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<!--<Logger name="org.apache.zookeeper" level="WARN"/>-->
<Root level="WARN">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</configuration>获取Storm的最简单方式是通过Maven:
<!-- https://mvnrepository.com/artifact/org.apache.storm/storm-core -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.2.1</version>
<!--在真实项目中一般需要定义为provided,暂时注释 -->
<!--<scope>provided</scope>-->
</dependency>在开始你的代码之前,最好对整个拓扑有一个较为清晰的了解,也就是我们之前所做的工作, 需要知道数据源的数据输出格式, 拥有几个节点,每个节点是做什么的,数据在各个节点之间如何分发,数据输入节点之前应该是怎样的,流出节点之后又应该是怎样的?
在弄清楚上述问题之前,一般最好不要开始进行代码。
而我们的输入呢?是读取一个文件, 读取文件中的每一行数据即可,然后分发到下一个节点去:
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.Map;
/**
* @author zyzdisciple
* @date 2019/4/3
*/
public class FileReaderSpout extends BaseRichSpout {
private static final long serialVersionUID = -1379474443608375554L;
private SpoutOutputCollector collector;
private BufferedReader br;
/**
* 方法是用来初始化一些资源类,具体的参数需要待对storm有了更深入的了解之后再度来看。
* 这些资源类不仅仅是参数提供的资源, 包括读取文件, 读取数据库,等等其他任何方式,
* 打开数据资源都是在这个方法中实现。
* 原因则是可以理解为,当对象被初始化时执行的方法,并不准确,但可以这样理解。
* @param conf
* @param topologyContext
* @param spoutOutputCollector
*/
public void open(Map conf, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.collector = spoutOutputCollector;
try {
br = new BufferedReader(new FileReader("E:\\IdeaProjects\\storm_demo\\src\\main\\resources\\data.txt"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
/**
* 流的核心,不断调用这个方法,读取数据,发送数据。
* 在这里采取的方式是每次读取一行,当然也可以在一次中读取所有数据,然后在循环中
* emit发射数据。
* 需要特别注意的是,这个方法一定是不能够被阻塞的, 也不能够抛出异常,
* 抛出异常会让当然程序停止,阻塞严重影响性能。
*/
public void nextTuple() {
try {
//向外发射数据
String line = br.readLine();
if (line == null) {
return;
}
collector.emit(new Values(line));
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 定义输出格式,在collector.emit时,new values可接受数组, 如发送 a b c,
* 则此时会与declare field中的名称一一对应,且顺序一致,并且必须保证数量一致。
* 通过这种配置的方式,就无需以map形式输出数据, 我们可以仅输出值即可。
*
* 当然declare不止这一种重载方法,其余的暂时不用理会。
* @param declarer
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
/*Fields名称这里,一般使用中会拆出来,定义为常量,而不是直接字符串,
* 包括Stream等其他属性也是,因为很有可能在其他地方会被用到,所以一般拆分成常量
* */
declarer.declare(new Fields("line"));
//declarer.declare(new Fields(DemoConstants.FIELD_LINE)); //应该采取这种方式
}
/**
* 在fileReader结束之后关闭对应的流
* 可以暂时忽略
*/
@Override
public void close() {
if (br != null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}在bolt的代码中, 并没有太多值得提到的地方, 因为它的操作大都与Spout保持一致。
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Map;
/**
* @author zyzdisciple
* @date 2019/4/3
*/
public class WordsBolt extends BaseRichBolt {
private static final long serialVersionUID = 520139031105355867L;
private OutputCollector collector;
/**
* 与spout中的open方法功能基本一致。
* @param stormConf
* @param context
* @param collector
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/**
* 类比于Spout中的nextTuple
* @param input 接收的数据,存有数据以及其相关信息。
*/
public void execute(Tuple input) {
String line = input.getStringByField("line").trim();
//input.getStringByField(DemoConstants.FIELD_LINE);
if (!line.isEmpty()) {
String[] words = line.split(" ");
for (String word : words) {
if (!word.trim().isEmpty()) {
collector.emit(new Values(word.charAt(0), word.length(), word));
}
}
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("headWord", "wordLength", "word"));
//declarer.declare(new Fields(DemoConstants.FIELD_HEAD_WORD, DemoConstants.FIELD_WORD_LENGTH, DemoConstants.FIELD_WORD));
}
}
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.util.HashMap;
import java.util.Map;
/**
* @author zyzdisciple
* @date 2019/4/3
*/
public class CountBolt extends BaseRichBolt {
private static final long serialVersionUID = 3693291291362580453L;
//这里存的时候取巧,用 a1 a2 表示首字母为1,长度为1,2 的单词
private Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
/*为什么hashMap也要放在这里进行初始化以后再提,这里暂时忽略。
*在storm中, bolt和 spout的初始化一般都不会放在构造器中进行,
* 而都是放在prepare中。
*/
counterMap = new HashMap<>();
}
@Override
public void execute(Tuple input) {
String key = input.getValueByField("headWord").toString().toLowerCase() + input.getIntegerByField("wordLength");
counterMap.put(key, countFor(key) + 1);
counterMap.forEach((k, v) -> {
System.out.println(k + " : " + v);
});
}
/**
* 在这里因为不需要向下一个节点下发数据, 因此不需要定义。
* @param declarer
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
/**
* 统计当前key已经出现多少次。
* @param key
* @return
*/
private int countFor(String key) {
Integer count = counterMap.get(key);
return count == null ? 0 : count;
}
/**
* 与Spout的close方法类似
*/
@Override
public void cleanup() {
}
}在countBolt中存在一个属性, map, 这是私有属性, 而storm在执行的时候可能会创建多个bolt实例,他们之间的变量并不共享, 这必然会导致一些问题, 这就是我们为什么在流分组策略中选择 fieldGroup分组的方式, 它能够保证, field相同的数据, 最终必然会流向同一个bolt实例。
但不能够保证 key: a key: b,的两个tuple流向不同的bolt。
import com.storm.demo.rudiments.bolt.CountBolt;
import com.storm.demo.rudiments.bolt.WordsBolt;
import com.storm.demo.rudiments.spout.FileReaderSpout;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import org.apache.storm.utils.Utils;
/**
* @author zyzdisciple
* @date 2019/4/3
*/
public class WordCountTopology {
private static final String STREAM_SPOUT = "spoutStream";
private static final String STREAM_WORD_BOLT = "wordBoltStream";
private static final String STREAM_COUNT_BOLT = "countBoltStream";
private static final String TOPOLOGY_NAME = "rudimentsTopology";
private static final Long TEN_SECONDS = 1000L * 10;
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
//设置Spout,第一个参数为节点名称, 第二个为对应的Spout实例
builder.setSpout(STREAM_SPOUT, new FileReaderSpout());
//设置bolt,在这里采用随机分组即可,在shuffleGrouping,中第一个参数为接收的节点名称,表示从哪个节点接收数据
//这里并不能等同于流名称,这个概念还有其他用处。
builder.setBolt(STREAM_WORD_BOLT, new WordsBolt()).shuffleGrouping(STREAM_SPOUT);
//在这里采取的是fieldsGrouping,原因则是因为在CountBolt中存在自有Map,必须保证属性一致的分到同一个bolt实例中
builder.setBolt(STREAM_COUNT_BOLT, new CountBolt()).fieldsGrouping(STREAM_WORD_BOLT, new Fields("headWord", "wordLength"));
//相关配置
Config config = new Config();
config.setDebug(true);
//本地集群
LocalCluster cluster = new LocalCluster();
//通过builder创建拓扑
StormTopology topology = builder.createTopology();
//提交拓扑
cluster.submitTopology(TOPOLOGY_NAME, config, topology);
//停留几秒后关闭拓扑,否则会永久运行下去
Utils.sleep(TEN_SECONDS);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
}
}在这个topology中,虽然功能简单,但事实已经完整的展示了一个topology的设计流程, 同时在 main方法中也蕴藏了整个 topology的执行流程,生命周期等等。 这部分在后续会提到。
标签:就是 序列化 指定 cal 因此 over 信息 orm 不难
原文地址:https://www.cnblogs.com/zyzdisciple/p/10652740.html