标签:path str 支持 路径 time 监控服务 应用 工作原理 exception
一.zookeeper介绍ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现。分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、配置维护,名字服务、分布式同步、分布式锁和分布式队列等功能。
数据模型:ZooKeeper 允许分布式进程通过共享的层次结构命名空间进行相互协调,这与标准文件系统类似。名称空间由 ZooKeeper 中的数据寄存器组成,称为 Znode,这些类似于文件和目录。与典型文件系统不同,ZooKeeper 数据保存在内存中,这意味着 ZooKeeper 可以实现高吞吐量和低延迟。
顺序访问:对于来自客户端的每个更新请求,ZooKeeper 都会分配一个全局唯一的递增编号。这个编号反应了所有事务操作的先后顺序,应用程序可以使用 ZooKeeper 这个特性来实现更高层次的同步原语。这个编号也叫做时间戳—zxid(ZooKeeper Transaction Id)。
可构建集群:为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。客户端在使用 ZooKeeper 时,需要知道集群机器列表,通过与集群中的某一台机器建立 TCP 连接来使用服务。客户端使用这个 TCP 链接来发送请求、获取结果、获取监听事件以及发送心跳包。如果这个连接异常断开了,客户端可以连接到另外的机器上。
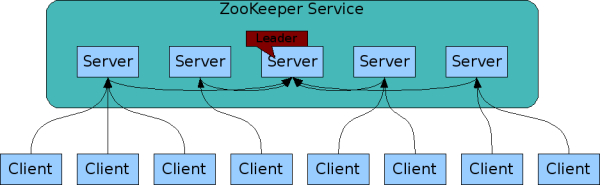
工作原理:
Leader选举:
1 //客户端连接zookeeper服务器
2 ZooKeeper zkClient = new ZooKeeper(CONNECT_STR, 50000, new Watcher() {
3 @Override
4 public void process(WatchedEvent watchedEvent) {
5 //监控服务节点变化
6 System.out.println("sssss");
7 }
8 });
9
10 //获取根节点下的所有节点
11 List<String> nodeList= zkClient.getChildren("/",null);
12
13 System.out.println(nodeList.toString());
14
15 //Stat isExists= zkClient.exists(LOCK_ROOT_PATH,null);
16 //在test父节点下创建子节点
17 String lockPath = zkClient.create("/test/why","why".getBytes(),
18 ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL);代码中需要注意的是如果父节点不存在,会报异常,同时父节点不能是临时节点。
Znode:
Session:
Watcher:是 ZooKeeper 中的一个很重要的特性。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
Version: Zookeeper 的每个 ZNode 上都会存储数据,对应于每个 ZNode,Zookeeper 都会为其维护一个叫作 Stat 的数据结构。Stat 中记录了这个 ZNode 的三个数据版本,分别是:version(当前节点版本)、cversion(当前节点的子节点版本)、aversion(当前节点的ACL版本)
ACL:ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。ZooKeeper 定义了 5 种权限:CREATE/READ/WRITE/DELETE/ADMIN
package com.why;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
/*
* 分布式锁
* */
public class DistributeLock {
private static final String LOCK_ROOT_PATH = "/test";
//private static final String LOCK_NODE_NAME = "Lock";
private static ZooKeeper _zkClient;
static {
try {
_zkClient = new ZooKeeper("192.168.6.132:2181", 500000, null);
} catch (IOException e) {
e.printStackTrace();
}
}
public static String getLock() {
try {
//System.out.println(_zkClient.getChildren("/",false));
String lockPath = _zkClient.create( "/test/why", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
//System.out.println(lockPath);
//System.out.println(_zkClient.getChildren(LOCK_ROOT_PATH,false));
if (tryLock(lockPath))
return lockPath;
else
return null;
} catch (Exception ex) {
ex.printStackTrace();
return null;
}
}
private static boolean tryLock(String lockPath) throws KeeperException, InterruptedException {
List<String> lockPaths = _zkClient.getChildren(LOCK_ROOT_PATH, false);
Collections.sort(lockPaths);
int index=lockPaths.indexOf(lockPath.substring(LOCK_ROOT_PATH.length()+1));
if(index==0){
//获得锁
return true;
}
else{
String preLockPath="/"+lockPaths.get(index-1);
Watcher watcher=new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
synchronized (this){
//唤醒线程
notifyAll();
}
}
};
Stat stat=_zkClient.exists(preLockPath,watcher);
if(stat==null){
return tryLock(lockPath);
}else{
synchronized (watcher){
watcher.wait();
}
return tryLock(lockPath);
}
}
}
public static void closeZkClient() throws InterruptedException {
_zkClient.close();
}
public static void releaseLock(String lockPath) throws KeeperException, InterruptedException {
_zkClient.delete(lockPath,-1);
}
}测试:
package com.why;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class MultiThreadDemo {
private static int counter = 0;
public static void plus() throws InterruptedException {
Thread.sleep(500);
counter++;
//System.out.println(counter);
}
public static int Count(){
return counter;
}
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
ExecutorService executor= Executors.newCachedThreadPool();
final int num=10;
for(int i=0;i<num;i++){
executor.submit(new Runnable() {
@Override
public void run() {
try {
String path = DistributeLock.getLock();
System.out.println(path);
plus();
DistributeLock.releaseLock(path);
System.out.println(Count());
} catch (InterruptedException | KeeperException e) {
e.printStackTrace();
}
}
});
}
executor.shutdown();
}
}标签:path str 支持 路径 time 监控服务 应用 工作原理 exception
原文地址:https://blog.51cto.com/14230003/2374617