标签:就是 index 而不是 很多 平滑 spl set ash 9.png
1. 文本向量化特征的不足
在将文本分词并向量化后,我们可以得到词汇表中每个词在各个文本中形成的词向量,比如在文本挖掘预处理之向量化与Hash Trick这篇文章中,我们将下面4个短文本做了词频统计:
corpus=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
不考虑停用词,处理后得到的词向量如下:
[[0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 2 1 0 0]
[0 0 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0]
[1 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1]]
如果我们直接将统计词频后的19维特征做为文本分类的输入,会发现有一些问题。比如第一个文本,我们发现"come","China"和“Travel”各出现1次,而“to“出现了两次。似乎看起来这个文本与”to“这个特征更关系紧密。但是实际上”to“是一个非常普遍的词,几乎所有的文本都会用到,因此虽然它的词频为2,但是重要性却比词频为1的"China"和“Travel”要低的多。如果我们的向量化特征仅仅用词频表示就无法反应这一点。因此我们需要进一步的预处理来反应文本的这个特征,而这个预处理就是TF-IDF。
2.TF-IDF概述
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由两部分组成,TF和IDF。
前面的TF也就是我们前面说到的词频,我们之前做的向量化也就是做了文本中各个词的出现频率统计,并作为文本特征,这个很好理解。关键是后面的这个IDF,即“逆文本频率”如何理解。在上一节中,我们讲到几乎所有文本都会出现的"to"其词频虽然高,但是重要性却应该比词频低的"China"和“Travel”要低。我们的IDF就是来帮助我们来反应这个词的重要性的,进而修正仅仅用词频表示的词特征值。
概括来讲, IDF反应了一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低,比如上文中的“to”。而反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高。比如一些专业的名词如“Machine Learning”。这样的词IDF值应该高。一个极端的情况,如果一个词在所有的文本中都出现,那么它的IDF值应该为0。
上面是从定性上说明的IDF的作用,那么如何对一个词的IDF进行定量分析呢?这里直接给出一个词xx的IDF的基本公式如下:
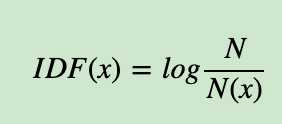
其中,NN代表语料库中文本的总数,而N(x)N(x)代表语料库中包含词xx的文本总数。为什么IDF的基本公式应该是是上面这样的而不是像N/N(x)N/N(x)这样的形式呢?这就涉及到信息论相关的一些知识了。感兴趣的朋友建议阅读吴军博士的《数学之美》第11章。
上面的IDF公式已经可以使用了,但是在一些特殊的情况会有一些小问题,比如某一个生僻词在语料库中没有,这样我们的分母为0, IDF没有意义了。所以常用的IDF我们需要做一些平滑,使语料库中没有出现的词也可以得到一个合适的IDF值。平滑的方法有很多种,最常见的IDF平滑后的公式之一为:
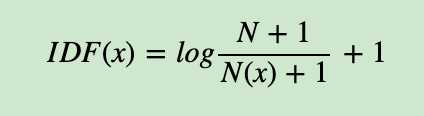
有了IDF的定义,我们就可以计算某一个词的TF-IDF值了:
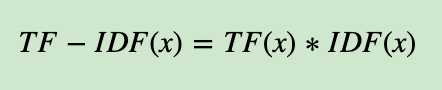
其中TF(x)TF(x)指词xx在当前文本中的词频。
代码实现:
import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer train = pd.read_csv(‘./data/train_set.csv‘, nrows=1000, index_col=None) tfidf_model = TfidfVectorizer(max_features=10, min_df=1).fit_transform(train[‘article‘]) print(tfidf_model.todense())
标签:就是 index 而不是 很多 平滑 spl set ash 9.png
原文地址:https://www.cnblogs.com/yankang/p/10666214.html
{kind=link}