标签:bottom 学习曲线 dataset star ati mini sel dev rem
Diagnostic is a test you can run, to get insight into what is or isn‘t working with an algorithm, and which will often give you insight as to what are promising things to try to improve a learning algorithm‘s performance. Anddiagnostics can taketake quite a lot of time to implement and understand but doing so can be a very good use of your time when you are developing learning algorithms because they can often save you from spending many months pursuing an avenue that you could have found out much earlier just was not going to be fruitful.time to implement and can sometimes,翻译:诊断是一项可以运行的测试,可以深入了解使用算法做什么或不做什么,并且通常可以让您深入了解尝试提高学习算法性能的方法。 诊断可能需要一段时间代价实现,即有时可能会花费大量时间运行,但这样做仍是可以很好地利用开发学习算法的时间,因为它们通常可以帮助避免花费数月时间来尝试一条并不会有多大成效的方法。
Given a dataset of training examples, we can split up the data into two sets: a training set and a test set. Typically, the training set consists of 70 % of your data and the test set is the remaining 30 %.(将训练集分成两部分,70%用作训练,30%用作测试)
方法一:
方法二:
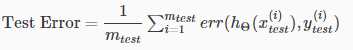
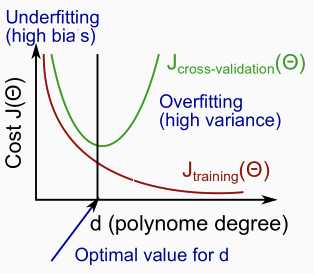
Given many models with different polynomial degrees, we can use a systematic approach to identify the ‘best‘ function.(从多个不同阶的多项式中选出预测性最好的多项式回归模型)
将训练数据分成三个不同的数据集,分别为训练集、交叉验证集与测试集
The training error will tend to decrease as we increase the degree d of the polynomial. At the same time, the cross validation error will tend to decrease as we increase d up to a point, and then it will increase as d is increased, forming a convex curve.(训练误差不断减小,验证与测试误差减小到某点后剧烈增大)
High bias (underfitting): both Jtrain(Θ) and JCV(Θ) will be high. Also, JCV(Θ)≈Jtrain(Θ).
High variance (overfitting): Jtrain(Θ) will be low and JCV(Θ) will be much greater than Jtrain(Θ).
问题:
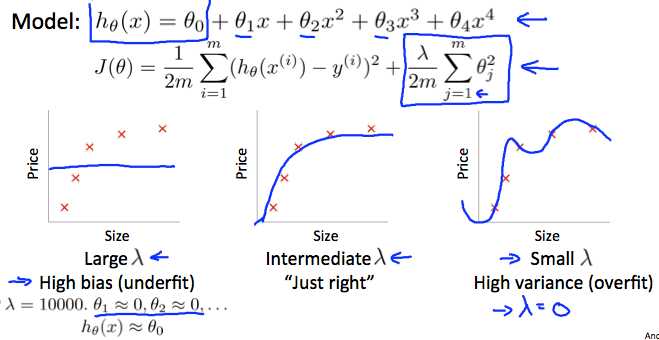
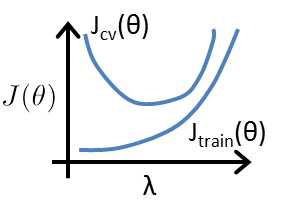
In the figure above, we see that as λ increases, our fit becomes more rigid. On the other hand, as λ approaches 0, we tend to over overfit the data.(对于过拟合模型,λ偏小表现过拟合,λ 偏大,表现欠拟合)
选择合适的λ的方法:
Low training set size: causes Jtrain(Θ) to be low and JCV(Θ) to be high.(小训练数据:训练集误差小,验证集误差大)
Large training set size: causes both Jtrain(Θ) and JCV(Θ) to be high with Jtrain(Θ)≈JCV(Θ).(大训练数据:训练集误差增大,验证误差减小,二者同一水平)
If a learning algorithm is suffering from high bias, getting more training data will not (by itself) help much.高偏差情况,增大训练数据不能有效改善线训练结果)
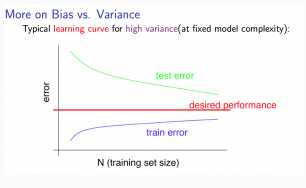
Low training set size: Jtrain(Θ) will be low and JCV(Θ) will be high.(小训练数据:训练误差小,验证误差大)
Large training set size: Jtrain(Θ) increases with training set size and JCV(Θ) continues to decrease without leveling off. Also, Jtrain(Θ) < JCV(Θ) but the difference between them remains significant.(大训练数据:训练集误差增大,验证误差减小,二者具有一个明显gap)
If a learning algorithm is suffering from high variance, getting more training data is likely to help..高方差情况,增大训练数据可以有效改善线训练结果)
Using a single hidden layer is a good starting default. You can train your neural network on a number of hidden layers using your cross validation set. You can then select the one that performs best.(默认使用一个隐藏层是好的开始,可以使用通过不同的验证集选择合适的隐藏层层数)
机器学习---吴恩达---Week6_1(机器学习改进方法)
标签:bottom 学习曲线 dataset star ati mini sel dev rem
原文地址:https://www.cnblogs.com/zouhq/p/10677620.html