标签:自定义 类型 info http 进制转化 network 解决问题 pyc token
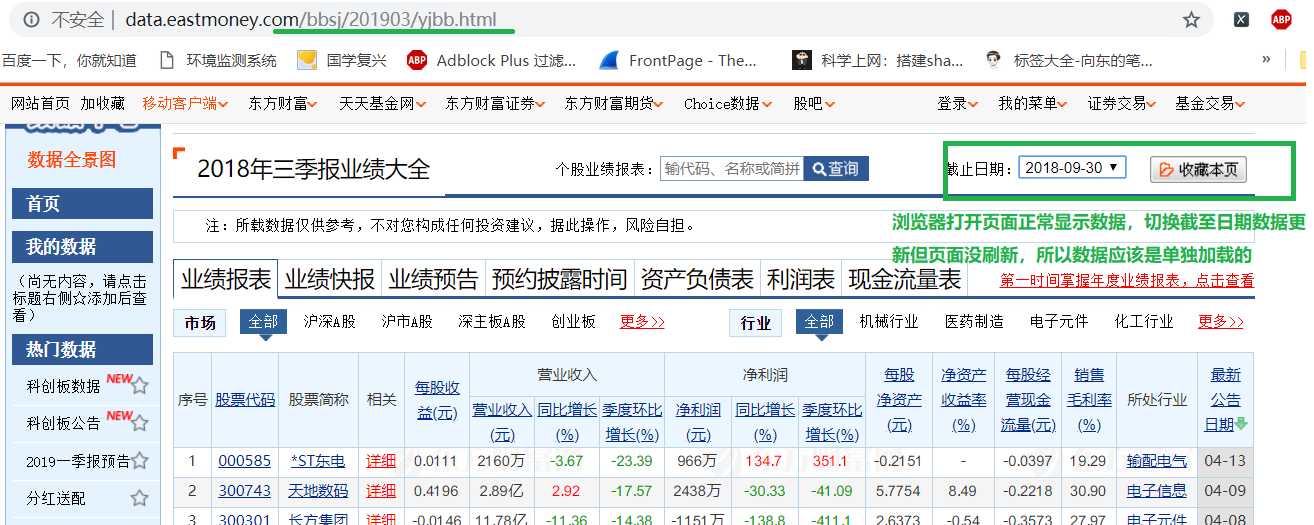
数据内容是方块,右边style的font-family是stonefont,ctrl-F搜索,发现字体文件。
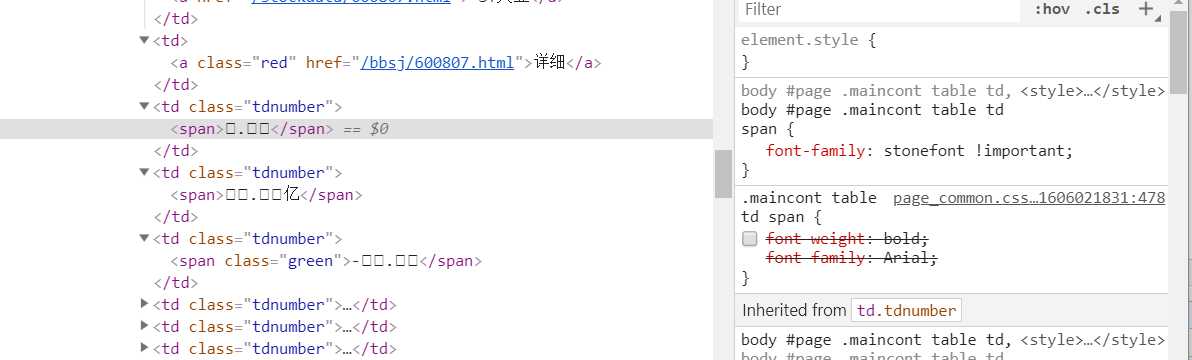
清除network记录,换一个截至日期,network里只有三条请求,第一条js里有页面上的加载数据和字体类型字体地址等,
第三条是字体文件。在源码ctrl-F搜索发现源码里同样有数据,内容和js里是一样的,感觉两种都可以爬。
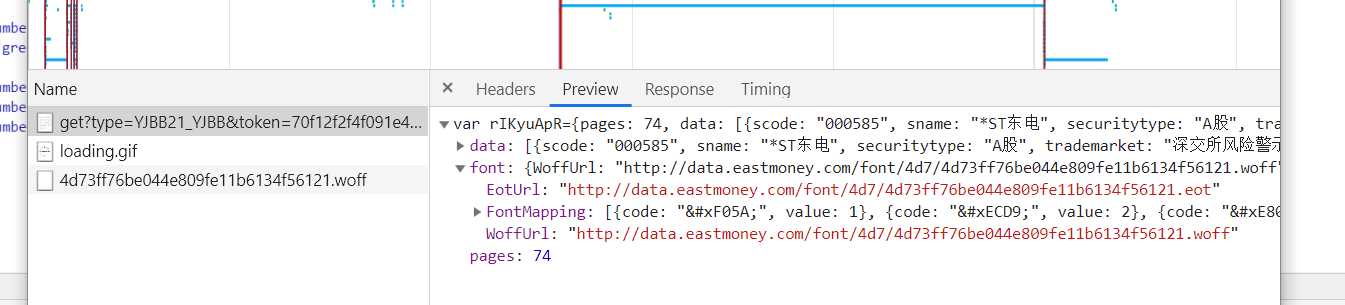
用requests请求数据,抄一遍headers用post发送拿到数据,数字内容还是乱码,所以接下来需要把乱码改成能显示的数字
#把headers里的querystring抄到dada里用post发送
url="http://dcfm.eastmoney.com/em_mutisvcexpandinterface/api/js"
headers={
"Referer": "http://data.eastmoney.com/bbsj/201903/yjbb.html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
}
data={
"type": "YJBB21_YJBB",
"token": "70f12f2f4f091e459a279469fe49eca5",
"st": "latestnoticedate",
"sr": "-1",
"p": "1",
"ps": "50",
"js": "var rIKyuApR={pages:(tp),data: (x),font:(font)}",
"filter": "(securitytypecode in (‘058001001‘,‘058001002‘))(reportdate=^2018-09-30^)",
"rt": "51838114"
}
r=requests.post(url=url,headers=headers,data=data)
r.encoding=r.apparent_encoding
print(r.text)
r.encoding=r.apparent_encoding
print(r.text)
#用jupyter打开比较方便
处理数据,把字符串变成python能处理的字典
org_data=r.text[r.text.index("{"):] json_str = or_data.replace(‘data:‘, ‘"data":‘).replace(‘pages:‘, ‘"pages":‘).replace(‘font:‘, ‘"font":‘) json_data = json.loads(json_str)
#拿到字体文件
font_url = json_data[‘font‘][‘WoffUrl‘]
处理结果:

字体文件里记录有字形索引和字形的映射关系,保存在字体的cmap表里,有关字体详细资料看下面链接:https://www.cnblogs.com/shenyiyangle/p/10700156.html
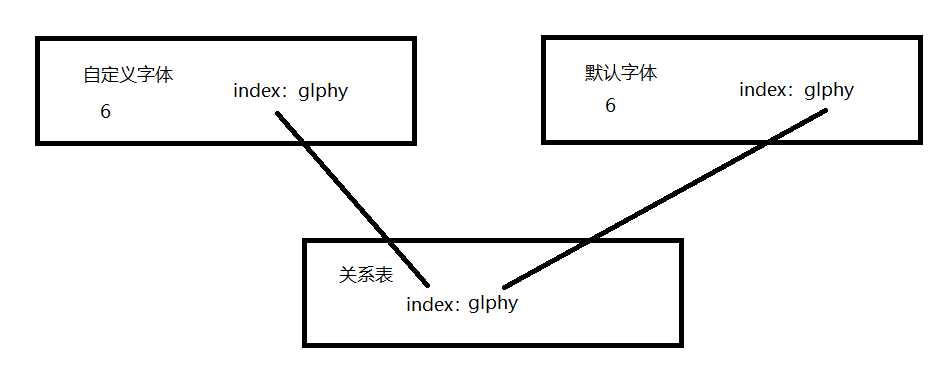
我们在浏览器看到乱码是因为网站加载了自定义字体,字体字形dindex和glphy映射关系和默认字体的映射不一样,网站按照自定义字体里的映射关系来表示数据,而我们抓到的数据用默认字体解析,因为映射关系不同,网站的unicode索引指向默认字体里的其他字形,所以我们看到的数据是错的。
解决问题需要建一张关系表,如果字形不变可以让自定义字体的unicode索引与默认字符对应,然后用默认字符替换自定义字体的unicode索引,这样就能在页面上显示正常数据。关系如下图:
用到了TTFont库,可以解析字体
font = requests.get(font_url, headers=header, timeout=30)
font_name = font_url.split("/")[-1]
with codecs.open(font_name, ‘wb‘) as f:
f.write(font.content)
font_map = TTFont(font_name).getBestCmap()#用getBestCmap()可以得到字体index和glphy的映射关系
“”“{120: ‘x‘,
57960: ‘bgldyy‘,
57971: ‘qqdwzl‘,
58817: ‘whyhyx‘,
59299: ‘wqqdzs‘,
60397: ‘zbxtdyc‘,
60633: ‘zwdxtdy‘,
60650: ‘zrwqqdl‘,
61125: ‘bdzypyc‘,
62069: ‘sxyzdxn‘,
62669: ‘nhpdjl‘}”“”
font_map里的就是自定义字体索引和字形的关系,key是index,value表示字形。
unicode代码就是字体index进行十六进制转化后将0X‘替换成 ‘&#x‘,font_map里的index转换成unicode如下:
font_index = [hex(key).upper().replace(‘0X‘, ‘&#x‘) +‘;‘ for key in font_map.keys()]
“”“[‘x‘,
‘‘,
‘‘,
‘‘,
‘‘,
‘‘,
‘‘,
‘‘,
‘‘,
‘‘,
‘‘]”“”
上面代码得到了自定义字体的关系,还需要unicode索引和和默认字符的关系,东方财富网直接写在页面上了。
font_mapping = json_data[‘font‘][‘FontMapping‘]
font_mapping = {i[‘code‘]: str(i[‘value‘]) for i in font_map}
”“”
{‘‘: ‘7‘,
‘‘: ‘1‘,
‘‘: ‘9‘,
‘‘: ‘3‘,
‘‘: ‘4‘,
‘‘: ‘8‘,
‘‘: ‘2‘,
‘‘: ‘0‘,
‘‘: ‘6‘,
‘‘: ‘5‘}
”“”
replace_dict= {hex(k).upper().replace(‘0X‘, ‘&#x‘) + ‘;‘: str(font_mapping[hex(k).upper().replace(‘0X‘, ‘&#x‘) + ‘;‘])for k in font_map.keys()}
“”“{‘x‘: ‘.‘,
‘‘: ‘7‘,
‘‘: ‘1‘,
‘‘: ‘9‘,
‘‘: ‘3‘,
‘‘: ‘4‘,
‘‘: ‘8‘,
‘‘: ‘2‘,
‘‘: ‘0‘,
‘‘: ‘6‘,
‘‘: ‘5‘}”“”
for k, v in replace_dict.items():
json_str = json_str.replace(k, v)
finall_data = json.loads(json_str)
结果:
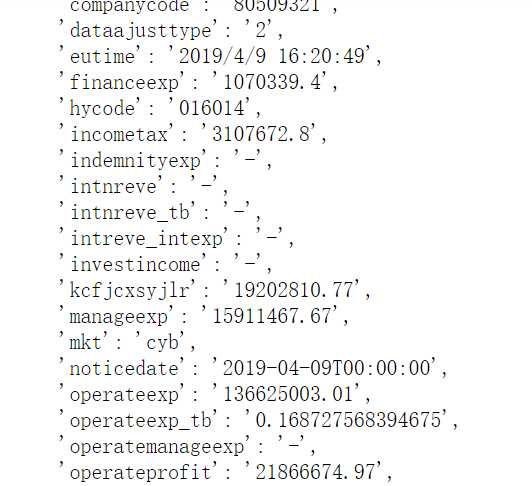
已得到正确数字了。
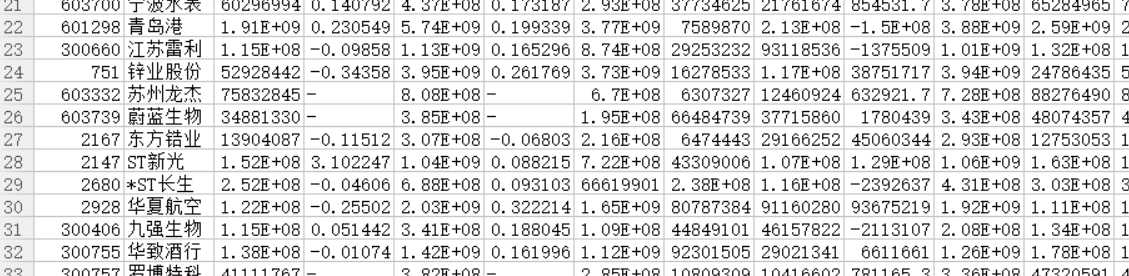
最后筛选需要的字段筛选数据并将数据存入数据库,导出数据保存成csv用excel打开结果。
标签:自定义 类型 info http 进制转化 network 解决问题 pyc token
原文地址:https://www.cnblogs.com/shenyiyangle/p/10702693.html