标签:永久代 超时 object 提高 created har method 信息 ef6
GC 优化的两个目标:
GC 优化的基本原则是:将不同的 GC 参数应用到两个及以上的服务器上然后比较它们的性能,然后将那些被证明可以提高性能或减少 GC 执行时间的参数应用于最终的工作服务器上。
除了可以在 JDK7 及更高版本中使用的 G1 收集器以外,其他分代 GC 都是由 Oracle JVM 提供的。关于分代 GC,就是对象在 Eden 区被创建,随后被转移到 Survivor 区,在此之后剩余的对象会被转入老年代。也有一些对象由于占用内存过大,在 Eden 区被创建后会直接被传入老年代。老年代 GC 相对来说会比新生代 GC 更耗时,因此,减少进入老年代的对象数量可以显著降低 Full GC 的频率。你可能会以为减少进入老年代的对象数量意味着把它们留在新生代,事实正好相反,新生代内存的大小是可以调节的。
Full GC 的执行时间比 Minor GC 要长很多,因此,如果在 Full GC 上花费过多的时间(超过 1s),将可能出现超时错误。
因此,你需要把老年代的大小设置成一个“合适”的值。
GC 优化需要考虑的 JVM 参数
类型参数描述堆内存大小-Xms启动 JVM 时堆内存的大小-Xmx堆内存最大限制新生代空间大小-XX:NewRatio新生代和老年代的内存比-XX:NewSize新生代内存大小-XX:SurvivorRatioEden 区和 Survivor 区的内存比
GC 优化时最常用的参数是-Xms,-Xmx和-XX:NewRatio。-Xms和-Xmx参数通常是必须的,所以NewRatio的值将对 GC 性能产生重要的影响。
有些人可能会问如何设置永久代内存大小,你可以用-XX:PermSize和-XX:MaxPermSize参数来进行设置,但是要记住,只有当出现OutOfMemoryError错误时你才需要去设置永久代内存。
GC 优化的过程和大多数常见的提升性能的过程相似,下面是笔者使用的流程:
你需要监控 GC 从而检查系统中运行的 GC 的各种状态。
在检查 GC 状态后,你需要分析监控结构并决定是否需要进行 GC 优化。如果分析结果显示运行 GC 的时间只有 0.1-0.3 秒,那么就不需要把时间浪费在 GC 优化上,但如果运行 GC 的时间达到 1-3 秒,甚至大于 10 秒,那么 GC 优化将是很有必要的。
但是,如果你已经分配了大约 10GB 内存给 Java,并且这些内存无法省下,那么就无法进行 GC 优化了。在进行 GC 优化之前,你需要考虑为什么你需要分配这么大的内存空间,如果你分配了 1GB 或 2GB 大小的内存并且出现了OutOfMemoryError,那你就应该执行**堆快照(heap dump)**来消除导致异常的原因。
注意:
**堆快照(heap dump)**是一个用来检查 Java 内存中的对象和数据的内存文件。该文件可以通过执行 JDK 中的jmap命令来创建。在创建文件的过程中,所有 Java 程序都将暂停,因此,不要在系统执行过程中创建该文件。
你可以在互联网上搜索 heap dump 的详细说明。
如果你决定要进行 GC 优化,那么你需要选择一个 GC 类型并且为它设置内存大小。此时如果你有多个服务器,请如上文提到的那样,在每台机器上设置不同的 GC 参数并分析它们的区别。
在设置完 GC 参数后就可以开始收集数据,请在收集至少 24 小时后再进行结果分析。如果你足够幸运,你可能会找到系统的最佳 GC 参数。如若不然,你还需要分析输出日志并检查分配的内存,然后需要通过不断调整 GC 类型/内存大小来找到系统的最佳参数。
如果 GC 优化的结果令人满意,就可以将参数应用到所有服务器上,并停止 GC 优化。
在下面的章节中,你将会看到上述每一步所做的具体工作。
jmap 即 JVM Memory Map。
jmap 用于生成 heap dump 文件。
如果不使用这个命令,还可以使用 -XX:+HeapDumpOnOutOfMemoryError 参数来让虚拟机出现 OOM 的时候,自动生成 dump 文件。
jmap 不仅能生成 dump 文件,还可以查询 finalize 执行队列、Java 堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。
命令格式:
jmap [option] LVMIDoption 参数:
dump 堆到文件,format 指定输出格式,live 指明是活着的对象,file 指定文件名
$ jmap -dump:live,format=b,file=dump.hprof 28920
Dumping heap to /home/xxx/dump.hprof ...
Heap dump file createddump.hprof 这个后缀是为了后续可以直接用 MAT(Memory Anlysis Tool)打开。
注意:使用 CMS GC 情况下,jmap -heap 的执行有可能会导致 java 进程挂起。
jmap -heap PID [root@chances bin]# ./jmap -heap 12379 Attaching to process ID 12379, please wait... Debugger attached successfully. Server compiler detected. JVM version is 17.0-b16 using thread-local object allocation. Parallel GC with 6 thread(s) Heap Configuration: MinHeapFreeRatio = 40 MaxHeapFreeRatio = 70 MaxHeapSize = 83886080 (80.0MB) NewSize = 1310720 (1.25MB) MaxNewSize = 17592186044415 MB OldSize = 5439488 (5.1875MB) NewRatio = 2 SurvivorRatio = 8 PermSize = 20971520 (20.0MB) MaxPermSize = 88080384 (84.0MB) Heap Usage: PS Young Generation Eden Space: capacity = 9306112 (8.875MB) used = 5375360 (5.1263427734375MB) free = 3930752 (3.7486572265625MB) 57.761608714788736% used From Space: capacity = 9306112 (8.875MB) used = 3425240 (3.2665634155273438MB) free = 5880872 (5.608436584472656MB) 36.80634834397007% used To Space: capacity = 9306112 (8.875MB) used = 0 (0.0MB) free = 9306112 (8.875MB) 0.0% used PS Old Generation capacity = 55967744 (53.375MB) used = 48354640 (46.11457824707031MB) free = 7613104 (7.2604217529296875MB) 86.39733629427693% used PS Perm Generation capacity = 62062592 (59.1875MB) used = 60243112 (57.452308654785156MB) free = 1819480 (1.7351913452148438MB) 97.06831451706046% used
jstack 用于生成 java 虚拟机当前时刻的线程快照。
线程快照是当前 java 虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
线程出现停顿的时候通过 jstack 来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。 如果 java 程序崩溃生成 core 文件,jstack 工具可以用来获得 core 文件的 java stack 和 native stack 的信息,从而可以轻松地知道 java 程序是如何崩溃和在程序何处发生问题。另外,jstack 工具还可以附属到正在运行的 java 程序中,看到当时运行的 java 程序的 java stack 和 native stack 的信息, 如果现在运行的 java 程序呈现 hung 的状态,jstack 是非常有用的。
命令格式:
jstack [option] LVMIDoption 参数:
-F - 当正常输出请求不被响应时,强制输出线程堆栈-l - 除堆栈外,显示关于锁的附加信息-m - 如果调用到本地方法的话,可以显示 C/C++的堆栈jps(JVM Process Status Tool),显示指定系统内所有的 HotSpot 虚拟机进程。
命令格式:
jps [options] [hostid]option 参数:
-l - 输出主类全名或 jar 路径-q - 只输出 LVMID-m - 输出 JVM 启动时传递给 main()的参数-v - 输出 JVM 启动时显示指定的 JVM 参数其中[option]、[hostid]参数也可以不写。
$ jps -l -m 28920 org.apache.catalina.startup.Bootstrap start 11589 org.apache.catalina.startup.Bootstrap start 25816 sun.tools.jps.Jps -l -m
jstat(JVM statistics Monitoring),是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT 编译等运行数据。
命令格式:
jstat [option] LVMID [interval] [count]参数:
jhat(JVM Heap Analysis Tool),是与 jmap 搭配使用,用来分析 jmap 生成的 dump,jhat 内置了一个微型的 HTTP/HTML 服务器,生成 dump 的分析结果后,可以在浏览器中查看。
注意:一般不会直接在服务器上进行分析,因为 jhat 是一个耗时并且耗费硬件资源的过程,一般把服务器生成的 dump 文件复制到本地或其他机器上进行分析。
命令格式:
jhat [dumpfile]jinfo(JVM Configuration info),用于实时查看和调整虚拟机运行参数。
之前的 jps -v 口令只能查看到显示指定的参数,如果想要查看未被显示指定的参数的值就要使用 jinfo 口令
命令格式:
jinfo [option] [args] LVMIDoption 参数:
详细参数说明请参考官方文档:Java HotSpot VM Options,这里仅列举常用参数。
配置描述-Xms堆空间初始值。-Xmx堆空间最大值。-XX:NewSize新生代空间初始值。-XX:MaxNewSize新生代空间最大值。-Xmn新生代空间大小。-XX:PermSize永久代空间的初始值。-XX:MaxPermSize永久代空间的最大值。
配置描述-XX:+UseSerialGC串行垃圾回收器-XX:+UseParallelGC并行垃圾回收器-XX:+UseParNewGC使用 ParNew + Serial Old 垃圾回收器组合-XX:+UseConcMarkSweepGC并发标记扫描垃圾回收器-XX:ParallelCMSThreads=并发标记扫描垃圾回收器 = 为使用的线程数量-XX:+UseG1GCG1 垃圾回收器
配置描述-XX:+PrintGCDetails打印 GC 日志-Xloggc:<filename>指定 GC 日志文件名-XX:+HeapDumpOnOutOfMemoryError内存溢出时输出堆快照文件
年轻代的设置很关键。
JVM 中最大堆大小有三方面限制:
整个堆大小 = 年轻代大小 + 年老代大小 + 持久代大小-XX:PermSize 设置。-Xmn 设置。JVM 给了三种选择:串行收集器、并行收集器、并发收集器。
获取 GC 日志有两种方式:
jstat -gc 统计垃圾回收堆的行为:
jstat -gc 1262
S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT
26112.0 24064.0 6562.5 0.0 564224.0 76274.5 434176.0 388518.3 524288.0 42724.7 320 6.417 1 0.398 6.815也可以设置间隔固定时间来打印:
$ jstat -gc 1262 2000 20这个命令意思就是每隔 2000ms 输出 1262 的 gc 情况,一共输出 20 次
Tomcat 设置示例:
JAVA_OPTS="-server -Xms2000m -Xmx2000m -Xmn800m -XX:PermSize=64m -XX:MaxPermSize=256m -XX:SurvivorRatio=4
-verbose:gc -Xloggc:$CATALINA_HOME/logs/gc.log
-Djava.awt.headless=true
-XX:+PrintGCTimeStamps -XX:+PrintGCDetails
-Dsun.rmi.dgc.server.gcInterval=600000 -Dsun.rmi.dgc.client.gcInterval=600000
-XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=15"-Xms2000m -Xmx2000m -Xmn800m -XX:PermSize=64m -XX:MaxPermSize=256m Xms,即为 jvm 启动时得 JVM 初始堆大小,Xmx 为 jvm 的最大堆大小,xmn 为新生代的大小,permsize 为永久代的初始大小,MaxPermSize 为永久代的最大空间。-XX:SurvivorRatio=4 SurvivorRatio 为新生代空间中的 Eden 区和救助空间 Survivor 区的大小比值,默认是 8,则两个 Survivor 区与一个 Eden 区的比值为 2:8,一个 Survivor 区占整个年轻代的 1/10。调小这个参数将增大 survivor 区,让对象尽量在 survitor 区呆长一点,减少进入年老代的对象。去掉救助空间的想法是让大部分不能马上回收的数据尽快进入年老代,加快年老代的回收频率,减少年老代暴涨的可能性,这个是通过将-XX:SurvivorRatio 设置成比较大的值(比如 65536)来做到。-verbose:gc -Xloggc:$CATALINA_HOME/logs/gc.log 将虚拟机每次垃圾回收的信息写到日志文件中,文件名由 file 指定,文件格式是平文件,内容和-verbose:gc 输出内容相同。-Djava.awt.headless=true Headless 模式是系统的一种配置模式。在该模式下,系统缺少了显示设备、键盘或鼠标。-XX:+PrintGCTimeStamps -XX:+PrintGCDetails 设置 gc 日志的格式-Dsun.rmi.dgc.server.gcInterval=600000 -Dsun.rmi.dgc.client.gcInterval=600000 指定 rmi 调用时 gc 的时间间隔-XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=15 采用并发 gc 方式,经过 15 次 minor gc 后进入年老代Young GC 回收日志:
2016-07-05T10:43:18.093+0800: 25.395: [GC [PSYoungGen: 274931K->10738K(274944K)] 371093K->147186K(450048K), 0.0668480 secs] [Times: user=0.17 sys=0.08, real=0.07 secs]Full GC 回收日志:
2016-07-05T10:43:18.160+0800: 25.462: [Full GC [PSYoungGen: 10738K->0K(274944K)] [ParOldGen: 136447K->140379K(302592K)] 147186K->140379K(577536K) [PSPermGen: 85411K->85376K(171008K)], 0.6763541 secs] [Times: user=1.75 sys=0.02, real=0.68 secs]通过上面日志分析得出,PSYoungGen、ParOldGen、PSPermGen 属于 Parallel 收集器。其中 PSYoungGen 表示 gc 回收前后年轻代的内存变化;ParOldGen 表示 gc 回收前后老年代的内存变化;PSPermGen 表示 gc 回收前后永久区的内存变化。young gc 主要是针对年轻代进行内存回收比较频繁,耗时短;full gc 会对整个堆内存进行回城,耗时长,因此一般尽量减少 full gc 的次数
通过两张图非常明显看出 gc 日志构成:
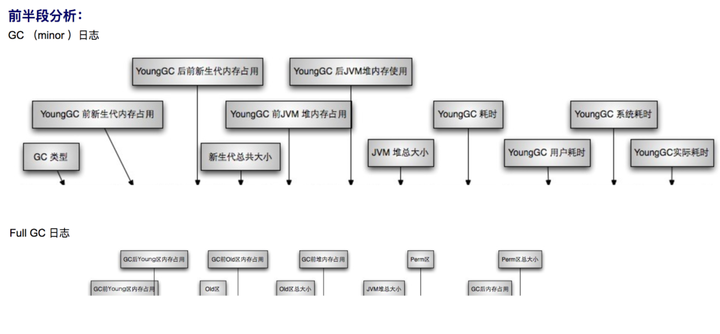
OutOfMemory(OOM)分析
OutOfMemory ,即内存溢出,是一个常见的 JVM 问题。那么分析 OOM 的思路是什么呢?
首先,要知道有三种 OutOfMemoryError:
OutOfMemoryError:PermGen space 表示方法区和运行时常量池溢出。
原因:
Perm 区主要用于存放 Class 和 Meta 信息的,Class 在被 Loader 时就会被放到 PermGen space,这个区域称为年老代。GC 在主程序运行期间不会对年老区进行清理,默认是 64M 大小。
当程序程序中使用了大量的 jar 或 class,使 java 虚拟机装载类的空间不够,超过 64M 就会报这部分内存溢出了,需要加大内存分配,一般 128m 足够。
解决方案:
(1)扩大永久代空间
-XX:PermSize 和 -XX:MaxPermSize 来控制永久代大小。-XX:MetaspaceSize 和 -XX:MaxMetaspaceSize 控制元空间大小。注意:-XX:PermSize 一般设为 64M
(2)清理应用程序中 WEB-INF/lib 下的 jar,用不上的 jar 删除掉,多个应用公共的 jar 移动到 Tomcat 的 lib 目录,减少重复加载。
OutOfMemoryError:Java heap space 表示堆空间溢出。
原因:JVM 分配给堆内存的空间已经用满了。
(1)使用 jmap 或 -XX:+HeapDumpOnOutOfMemoryError 获取堆快照。 (2)使用内存分析工具(visualvm、mat、jProfile 等)对堆快照文件进行分析。 (3)根据分析图,重点是确认内存中的对象是否是必要的,分清究竟是是内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)。
内存泄漏是指由于疏忽或错误造成程序未能释放已经不再使用的内存的情况。
内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,失去了对该段内存的控制,因而造成了内存的浪费。
内存泄漏随着被执行的次数越多-最终会导致内存溢出。
而因程序死循环导致的不断创建对象-只要被执行到就会产生内存溢出。
内存泄漏常见几个情况:
重点关注:
(1)检查程序,看是否有死循环或不必要地重复创建大量对象。有则改之。
下面是一个重复创建内存的示例:
public class OOM { public static void main(String[] args) { Integer sum1=300000; Integer sum2=400000; OOM oom = new OOM(); System.out.println("往ArrayList中加入30w内容"); oom.javaHeapSpace(sum1); oom.memoryTotal(); System.out.println("往ArrayList中加入40w内容"); oom.javaHeapSpace(sum2); oom.memoryTotal(); } public void javaHeapSpace(Integer sum){ Random random = new Random(); ArrayList openList = new ArrayList(); for(int i=0;i<sum;i++){ String charOrNum = String.valueOf(random.nextInt(10)); openList.add(charOrNum); } } public void memoryTotal(){ Runtime run = Runtime.getRuntime(); long max = run.maxMemory(); long total = run.totalMemory(); long free = run.freeMemory(); long usable = max - total + free; System.out.println("最大内存 = " + max); System.out.println("已分配内存 = " + total); System.out.println("已分配内存中的剩余空间 = " + free); System.out.println("最大可用内存 = " + usable); } }
执行结果:
往ArrayList中加入30w内容
最大内存 = 20447232
已分配内存 = 20447232
已分配内存中的剩余空间 = 4032576
最大可用内存 = 4032576
往ArrayList中加入40w内容Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOf(Arrays.java:2245) at java.util.Arrays.copyOf(Arrays.java:2219) at java.util.ArrayList.grow(ArrayList.java:242) at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:216) at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:208) at java.util.ArrayList.add(ArrayList.java:440) at pers.qingqian.study.seven.OOM.javaHeapSpace(OOM.java:36) at pers.qingqian.study.seven.OOM.main(OOM.java:26)
(2)扩大堆内存空间
使用 -Xms 和 -Xmx 来控制堆内存空间大小。
原因:JDK6 新增错误类型,当 GC 为释放很小空间占用大量时间时抛出;一般是因为堆太小,导致异常的原因,没有足够的内存。
解决方案:
查看系统是否有使用大内存的代码或死循环; 通过添加 JVM 配置,来限制使用内存:
<jvm-arg>-XX:-UseGCOverheadLimit</jvm-arg>
原因:线程过多
那么能创建多少线程呢?这里有一个公式:
(MaxProcessMemory - JVMMemory - ReservedOsMemory) / (ThreadStackSize) = Number of threads
MaxProcessMemory 指的是一个进程的最大内存
JVMMemory JVM内存
ReservedOsMemory 保留的操作系统内存
ThreadStackSize 线程栈的大小当发起一个线程的创建时,虚拟机会在 JVM 内存创建一个 Thread 对象同时创建一个操作系统线程,而这个系统线程的内存用的不是 JVMMemory,而是系统中剩下的内存: (MaxProcessMemory - JVMMemory - ReservedOsMemory) 结论:你给 JVM 内存越多,那么你能用来创建的系统线程的内存就会越少,越容易发生 java.lang.OutOfMemoryError: unable to create new native thread。
定位步骤:
(1)执行 top -c 命令,找到 cpu 最高的进程的 id
(2)jstack PID 导出 Java 应用程序的线程堆栈信息。
示例:
jstack 6795 "Low Memory Detector" daemon prio=10 tid=0x081465f8 nid=0x7 runnable [0x00000000..0x00000000] "CompilerThread0" daemon prio=10 tid=0x08143c58 nid=0x6 waiting on condition [0x00000000..0xfb5fd798] "Signal Dispatcher" daemon prio=10 tid=0x08142f08 nid=0x5 waiting on condition [0x00000000..0x00000000] "Finalizer" daemon prio=10 tid=0x08137ca0 nid=0x4 in Object.wait() [0xfbeed000..0xfbeeddb8] at java.lang.Object.wait(Native Method) - waiting on <0xef600848> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:116) - locked <0xef600848> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:132) at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:159) "Reference Handler" daemon prio=10 tid=0x081370f0 nid=0x3 in Object.wait() [0xfbf4a000..0xfbf4aa38] at java.lang.Object.wait(Native Method) - waiting on <0xef600758> (a java.lang.ref.Reference$Lock) at java.lang.Object.wait(Object.java:474) at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:116) - locked <0xef600758> (a java.lang.ref.Reference$Lock) "VM Thread" prio=10 tid=0x08134878 nid=0x2 runnable "VM Periodic Task Thread" prio=10 tid=0x08147768 nid=0x8 waiting on condition
在打印的堆栈日志文件中,tid 和 nid 的含义:
nid : 对应的 Linux 操作系统下的 tid 线程号,也就是前面转化的 16 进制数字
tid: 这个应该是 jvm 的 jmm 内存规范中的唯一地址定位在 CPU 过高的情况下,查找响应的线程,一般定位都是用 nid 来定位的。而如果发生死锁之类的问题,一般用 tid 来定位。
(3)定位 CPU 高的线程打印其 nid
查看线程下具体进程信息的命令如下:
top -H -p 6735
top - 14:20:09 up 611 days, 2:56, 1 user, load average: 13.19, 7.76, 7.82 Threads: 6991 total, 17 running, 6974 sleeping, 0 stopped, 0 zombie %Cpu(s): 90.4 us, 2.1 sy, 0.0 ni, 7.0 id, 0.0 wa, 0.0 hi, 0.4 si, 0.0 st KiB Mem: 32783044 total, 32505008 used, 278036 free, 120304 buffers KiB Swap: 0 total, 0 used, 0 free. 4497428 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6800 root 20 0 27.299g 0.021t 7172 S 54.7 70.1 187:55.61 java 6803 root 20 0 27.299g 0.021t 7172 S 54.4 70.1 187:52.59 java 6798 root 20 0 27.299g 0.021t 7172 S 53.7 70.1 187:55.08 java 6801 root 20 0 27.299g 0.021t 7172 S 53.7 70.1 187:55.25 java 6797 root 20 0 27.299g 0.021t 7172 S 53.1 70.1 187:52.78 java 6804 root 20 0 27.299g 0.021t 7172 S 53.1 70.1 187:55.76 java 6802 root 20 0 27.299g 0.021t 7172 S 52.1 70.1 187:54.79 java 6799 root 20 0 27.299g 0.021t 7172 S 51.8 70.1 187:53.36 java 6807 root 20 0 27.299g 0.021t 7172 S 13.6 70.1 48:58.60 java 11014 root 20 0 27.299g 0.021t 7172 R 8.4 70.1 8:00.32 java 10642 root 20 0 27.299g 0.021t 7172 R 6.5 70.1 6:32.06 java 6808 root 20 0 27.299g 0.021t 7172 S 6.1 70.1 159:08.40 java 11315 root 20 0 27.299g 0.021t 7172 S 3.9 70.1 5:54.10 java 12545 root 20 0 27.299g 0.021t 7172 S 3.9 70.1 6:55.48 java 23353 root 20 0 27.299g 0.021t 7172 S 3.9 70.1 2:20.55 java 24868 root 20 0 27.299g 0.021t 7172 S 3.9 70.1 2:12.46 java 9146 root 20 0 27.299g 0.021t 7172 S 3.6 70.1 7:42.72 java
由此可以看出占用 CPU 较高的线程,但是这些还不高,无法直接定位到具体的类。nid 是 16 进制的,所以我们要获取线程的 16 进制 ID:
printf "%x\n" 6800
输出结果:45cd然后根据输出结果到 jstack 打印的堆栈日志中查定位:
"catalina-exec-5692" daemon prio=10 tid=0x00007f3b05013800 nid=0x45cd waiting on condition [0x00007f3ae08e3000] java.lang.Thread.State: TIMED_WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000006a7800598> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:226) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2082) at java.util.concurrent.LinkedBlockingQueue.poll(LinkedBlockingQueue.java:467) at org.apache.tomcat.util.threads.TaskQueue.poll(TaskQueue.java:86) at org.apache.tomcat.util.threads.TaskQueue.poll(TaskQueue.java:32) at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1068) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) at java.lang.Thread.run(Thread.java:745)
免费Java资料需要自己领取,涵盖了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo高并发分布式等教程,一共30G。
传送门:https://mp.weixin.qq.com/s/JzddfH-7yNudmkjT0IRL8Q

标签:永久代 超时 object 提高 created har method 信息 ef6
原文地址:https://www.cnblogs.com/yuxiang1/p/10702967.html