标签:图结构 名称 plt des 类型 cti 利用 ace numpy
一、jieba 库简介
(1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组;除此之外,jieba 库还提供了增加自定义中文单词的功能。
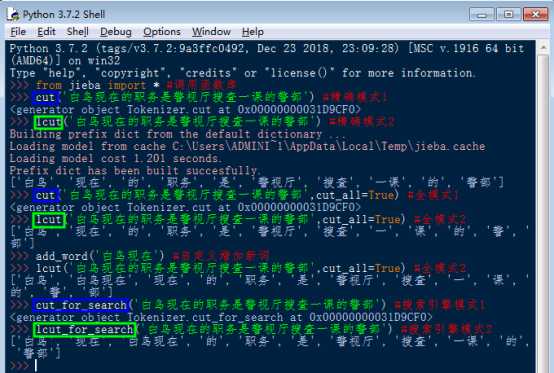
(2) jieba 库支持3种分词模式:
精确模式:将句子最精确地切开,适合文本分析。
全模式:将句子中所以可以成词的词语都扫描出来,速度非常快,但是不能消除歧义。
搜索引擎模式:在精确模式的基础上,对长分词再次切分,提高召回率,适合搜索引擎分词。
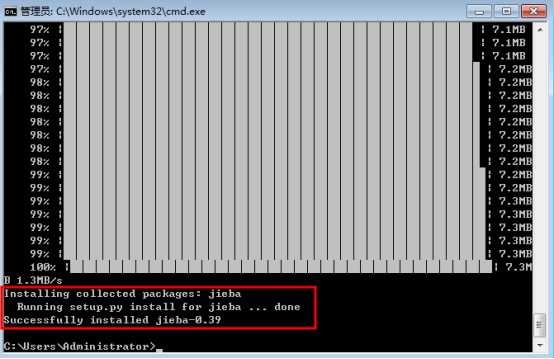
二、安装库函数
(1) 在命令行下输入指令:
pip install jieba
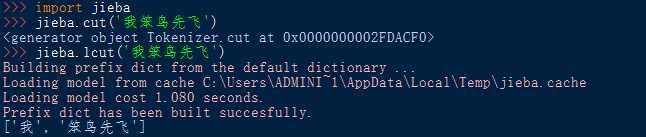
三、调用库函数
(1) 导入库函数:import <库名>
使用库中函数:<库名> . <函数名> (<函数参数>)
)
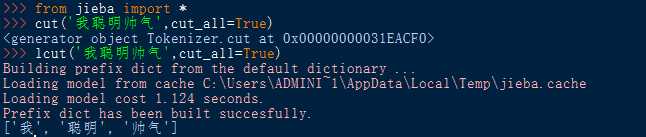
(2) 导入库函数:from <库名> import * ( *为通配符 )
使用库中函数:<函数名> (<函数参数>)
函数使用实例
(1) jieba 库单枪匹马
A. 代码实现
注:代码使用的文档 >>> Detective_Novel(utf-8).zip [点击下载],也可自行找 utf-8 编码格式的txt文件。
1 # -*- coding:utf-8 -*-
2 from jieba import *
3
4 def Replace(text,old,new): #替换列表的字符串
5 for char in old:
6 text = text.replace(char,new)
7 return text
8
9 def getText(filename): #读取文件内容(utf-8 编码格式)
10 #特殊符号和部分无意义的词
11 sign = ‘‘‘!~·@¥……*“”‘’\n(){}【】;:"‘「,」。-、?‘‘‘
12 txt = open(‘{}.txt‘.format(filename),encoding=‘utf-8‘).read()
13 return Replace(txt,sign," ")
14
15 def word_count(passage,N): #计算passage文件中的词频数,并将前N个输出
16 words = lcut(passage) #精确模式分词形式
17 counts = {} #创建计数器 --- 字典类型
18 for word in words: #消除同意义的词和遍历计数
19 if word == ‘小五‘ or word == ‘小五郎‘ or word == ‘五郎‘:
20 rword = ‘毛利‘
21 elif word == ‘柯‘ or word == ‘南‘:
22 rword = ‘柯南‘
23 elif word == ‘小‘ or word == ‘兰‘:
24 rword = ‘小兰‘
25 elif word == ‘目‘ or word == ‘暮‘ or word == ‘警官‘:
26 rword = ‘暮目‘
27 else:
28 rword = word
29 counts[rword] = counts.get(rword,0) + 1
30 excludes = lcut_for_search("你我事他和她在这也有什么的是就吧啊吗哦呢都了一个")
31 for word in excludes: #除去意义不大的词语
32 del(counts[word])
33 items = list(counts.items()) #转换成列表形式
34 items.sort(key = lambda x : x[1], reverse = True ) #按次数排序
35 for i in range(N): #依次输出
36 word,count = items[i]
37 print("{:<7}{:>6}".format(word,count))
38
39 if __name__ == ‘__main__‘:
40 passage = getText(‘Detective_Novel‘) #输入文件名称读入文件内容
41 word_count(passage,20) #调用函数得到词频数
B. 执行结果
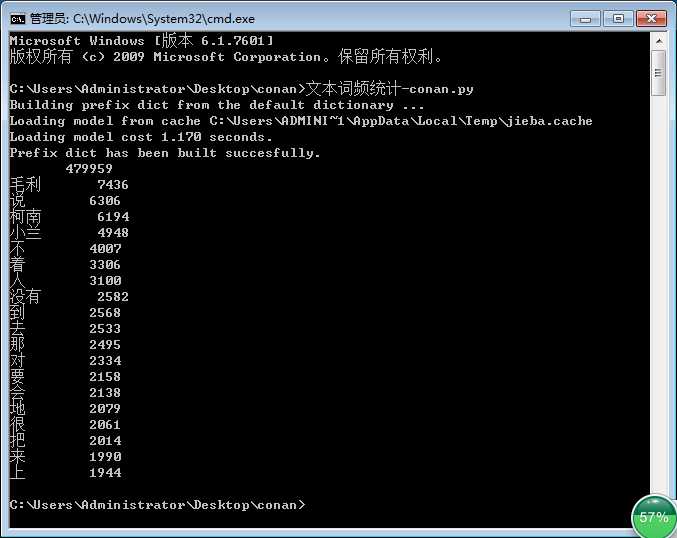
(2) jieba 库 和 wordcloud 库 强强联合 --- 词云图
A. 代码实现
1 # -*- coding:utf-8 -*-
2 from wordcloud import WordCloud
3 import matplotlib.pyplot as plt
4 import numpy as np
5 from PIL import Image
6 from jieba import *
7
8 def Replace(text,old,new): #替换列表的字符串
9 for char in old:
10 text = text.replace(char,new)
11 return text
12
13 def getText(filename): #读取文件内容(utf-8 编码格式)
14 #特殊符号和部分无意义的词
15 sign = ‘‘‘!~·@¥……*“”‘’\n(){}【】;:"‘「,」。-、?‘‘‘
16 txt = open(‘{}.txt‘.format(filename),encoding=‘utf-8‘).read()
17 return Replace(txt,sign," ")
18
19 def creat_word_cloud(filename): #将filename 文件的词语按出现次数输出为词云图
20 text = getText(filename) #读取文件
21 wordlist = lcut(text) #jieba库精确模式分词
22 wl = ‘ ‘.join(wordlist) #生成新的字符串
23
24 #设置词云图
25 font = r‘C:\Windows\Fonts\simfang.ttf‘ #设置字体路径
26 wc = WordCloud(
27 background_color = ‘black‘, #背景颜色
28 max_words = 2000, #设置最大显示的词云数
29 font_path = font, #设置字体形式(在本机系统中)
30 height = 1200, #图片高度
31 width = 1600, #图片宽度
32 max_font_size = 100, #字体最大值
33 random_state = 100, #配色方案的种类
34 )
35 myword = wc.generate(wl) #生成词云
36 #展示词云图
37 plt.imshow(myword)
38 plt.axis(‘off‘)
39 plt.show()
40 #以原本的filename命名保存词云图
41 wc.to_file(‘{}.png‘.format(filename))
42
43 if __name__ == ‘__main__‘:
44 creat_word_cloud(‘Detective_Novel‘) #输入文件名生成词云图

标签:图结构 名称 plt des 类型 cti 利用 ace numpy
原文地址:https://www.cnblogs.com/luorunsb/p/10708243.html