标签:code ons .com spi ide 博客 awl 创建 网站
思路:
从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数。
1. 创建项目
scrapy startproject myspiderproject
2. 创建crawlSpider 爬虫
scrapy genspider -t crawl 爬虫名 爬取网站域名
3. 启动爬虫
scrapy crawl 爬虫名 # 会打印日志
scrapy crawl 爬虫名 --nolog
crawlSpider 的参数解析:
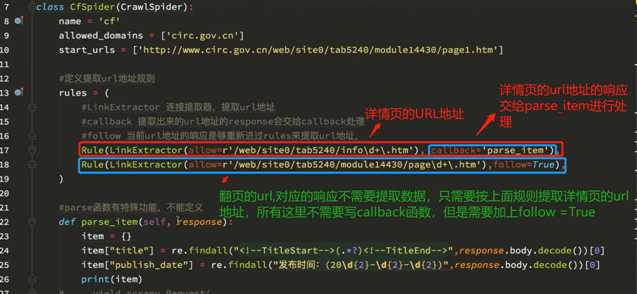
需求:爬取csdn上面所有的博客专家及其文章的文章 Url地址:http://blog.csdn.net/experts.html 。
分析:

使用crawlSpider 的注意点:

补充知识点:

标签:code ons .com spi ide 博客 awl 创建 网站
原文地址:https://www.cnblogs.com/knighterrant/p/10710947.html