标签:mic nbsp 搭建环境 客户端 编号 replica target 服务 mamicode
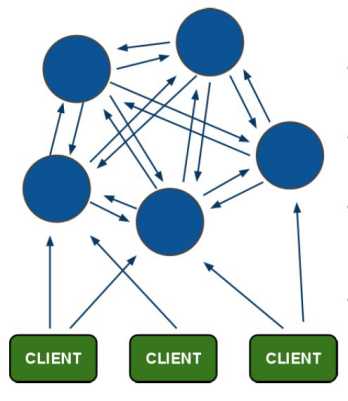
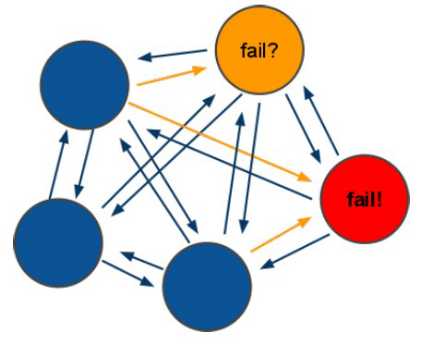
redis-cluster投票:容错 (至少要三个才可以,才能超过半数)
架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,
redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,
这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致
均等的将哈希槽映射到不同的节点
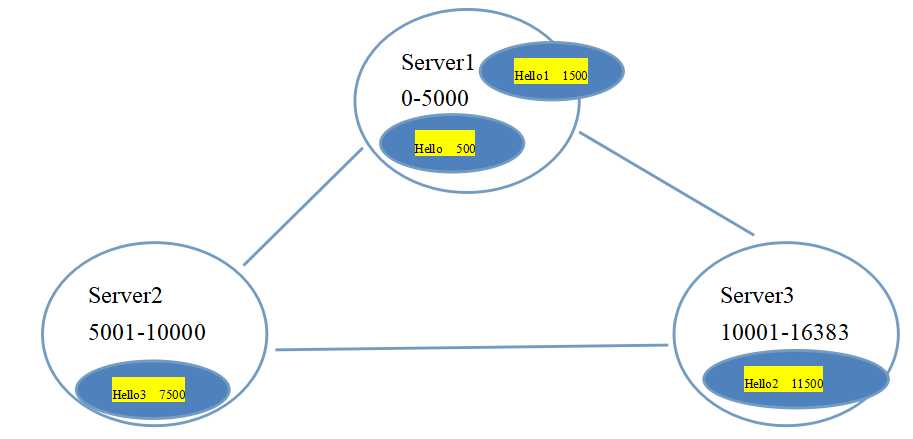
搭建集群,极限情况也就最多16384个节点。
Redis集群中至少应该有3个节点。要保证集群得高可用,需要每个节点有1个备份机。
Redis集群需要6台服务器。
搭建伪分布式。可以使用一台虚拟机允许6个redis实例。需要修改redis得端口号7001-7006
第一步:准备好1台redis服务器
【这里我使用的之前搭建好的一台服务器】
虚拟机上面安装Redis的方法,参照的是redis在Linux上的安装教程:
第二步:在/usr/local下面创建一个集群目录
# mkdir /usr/local/redis-cluster
第三步:拷贝已经安装好的redis实例到redis-cluster目录下
[root@admin local]# cp -r redis/bin redis-cluster/redis01
第四步:删除拷贝的实例里面的dump.rdb 和 appendonly.aof文件。
因为本实例没有启动AOF持久化的,所以就没有appendonly.aof文件。
只用删除dump.rdb文件。
我们搭建集群的时候,每个节点应该是一个空节点,这里面不应该有数据,这个实例之前使用过,里面有数据。
搭建集群的时候防止出现问题,所以先给删除掉,保证是一个干净的节点。
[root@admin redis01]# rm -rf dump.rdb
第五步:修改配置文件中的端口号
[root@admin redis01]# vim redis.conf
将默认的6379端口修改为7001

输入wq保存并退出
第六步:修改配置文件中的启动集群
[root@admin redis01]# vim redis.conf
修改前:

修改后:

输入wq保存并退出
第七步:复制第六步修改完成配置文件的redis实例5份
[root@admin redis-cluster]# cp -r redis01/ redis02 [root@admin redis-cluster]# cp -r redis01/ redis03 [root@admin redis-cluster]# cp -r redis01/ redis04 [root@admin redis-cluster]# cp -r redis01/ redis05 [root@admin redis-cluster]# cp -r redis01/ redis06
第八步:修改redis02~redis06实例的端口号分别为7002~7006
[root@admin redis-cluster]# vim redis02/redis.conf [root@admin redis-cluster]# vim redis03/redis.conf [root@admin redis-cluster]# vim redis04/redis.conf [root@admin redis-cluster]# vim redis05/redis.conf [root@admin redis-cluster]# vim redis06/redis.conf
第九步:使用批处理启动上面的6个实例
这里也可以一个一个的启动,只是麻烦一些。
1、首先执行命令vim start-all.sh创建一个批处理文件,并编辑
[root@admin redis-cluster]# vim start-all.sh
文件的内如如下:
cd redis01 ./redis-server redis.conf cd .. cd redis02 ./redis-server redis.conf cd .. cd redis03 ./redis-server redis.conf cd .. cd redis04 ./redis-server redis.conf cd .. cd redis05 ./redis-server redis.conf cd .. cd redis06 ./redis-server redis.conf cd ..
2、修改start-all.sh文件的权限,给当前用户所有权限
[root@admin redis-cluster]# chmod u+x start-all.sh

3、执行start-all.sh启动所有的6个redis实例
[root@admin redis-cluster]# ./start-all.sh
4、查看一下是否真的启动起来了
[root@admin redis-cluster]# ps -aux | grep -i redis --color

到这里6个节点全部配置好,并且启动起来了。
下面就需要把集群搭建起来,也就是把这六个节点连到一起来。
这里我们需要使用一个工具,这个工具就在我们的redis源代码的src目录下面。
执行命令切换到src目录下:
[root@admin redis-cluster]# cd /usr/local/redis-3.0.0/src
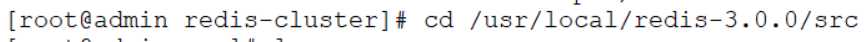
查看里面的rb文件
[root@admin src]# ll *.rb
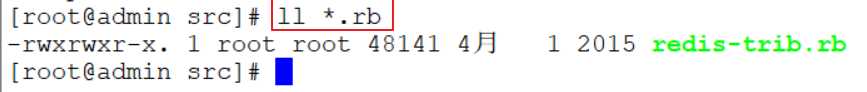
复制Ruby脚本文件redis-trib.rb到redis-cluster目录下去
[root@admin src]# cp -r redis-trib.rb /usr/local/redis-cluster/
下面简单了解一下Ruby是什么?
第一步:我们使用ruby脚本搭建集群,所以需要安装ruby的运行环境。
依次执行下面两条命令
# yum install ruby
中间如果出现询问输入y确认即可。

# yum install rubygems
中间如果出现询问输入y确认即可。

第二步:安装ruby脚本运行使用的包
1.上传包到Linux服务器上
2、将其复制到/usr/local目录下
[root@admin soft]# cp redis-3.0.0.gem /usr/local

3、安装redis-3.0.0.gem
[root@admin local]# gem install redis-3.0.0.gem
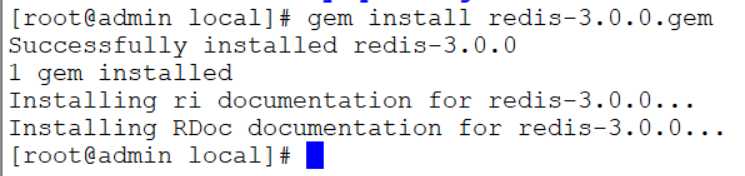
这样这个库就安装好了。
现在redis-trib.rb这个脚本就可以执行了。
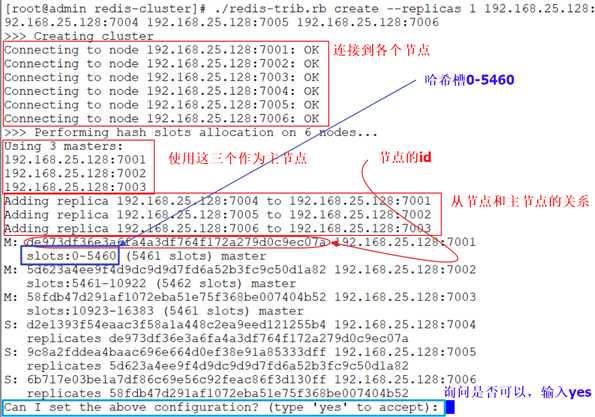
[root@admin redis-cluster]# ./redis-trib.rb create --replicas 1 192.168.25.128:7001 192.168.25.128:7002 192.168.25.128:7003 192.168.25.128:7004 192.168.25.128:7005 192.168.25.128:7006
1 表示每个节点有一个备份机。
因为我们是在一台服务器上面演示,ip一样只是端口不一样。执行的过程中有一个计算过程,算出来是6个节点,所以集群里面有三个节点。
如果里面只有5个ip地址列表的话,就不是整数了,会报错。所以这里一定要是偶数个节点。
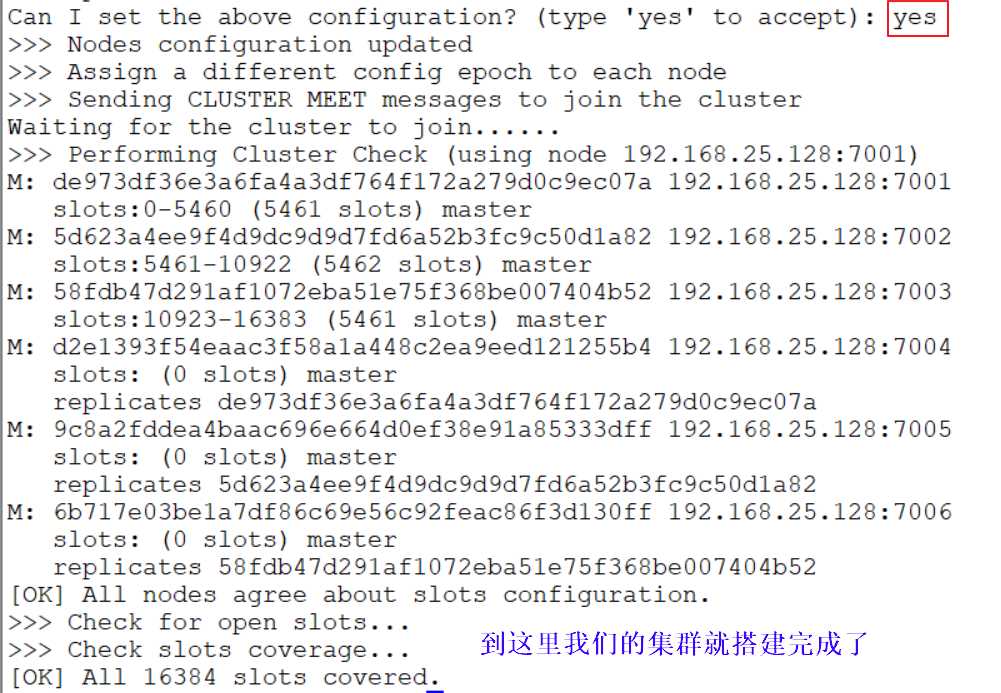
再补充一下:如果我们真的是在六台服务器上搭建集群的话,不中和这个也是一样的。
只需要在任意一台服务器上面执行上面的搭建环境过程,
使用Ruby脚本搭建集群,但是特别需要注意的是:每台
服务器上的防火墙一定要关闭。如果没有关闭防火墙的话
在询问是否可以的时候,输入yes之后,会卡住Waiting
for the cluster to join......这里不动。

连接集群我们使用redis提供的客户端redis-cli,连接集群中的任意节点就可以了。
[root@admin redis-cluster]# redis01/redis-cli -p 7006 -c
-c 代表连接的是redis集群。
连接从节点也是一样的。

下面测试一下:
可以看到通过计算,username定位到了14315这个哈希槽,存入的是端口7003的这台服务器。

可以看到通过计算,age定位到了741这个哈希槽,存入的是端口7001的这台服务器。

可以看到,这样数据就可以均匀的分布到每一台服务器,可以实现每个节点都有一定数量的数据。
如果主节点挂了,从节点就可以顶替工作,这也就实现了高可用。
特别需要注意的是:连接集群的时候需要加上 -c 参数
标签:mic nbsp 搭建环境 客户端 编号 replica target 服务 mamicode
原文地址:https://www.cnblogs.com/lywJ/p/10710878.html