标签:请求 apache daemon 需要 管理 local trap 写入 tar
Kafka 是一款分布式消息发布和订阅系统,具有高性能、高吞吐量的特点而被广泛应用与大数据传输场景。它是由 LinkedIn 公司开发,使用 Scala 语言编写,之后成为 Apache 基金会的一个顶级项目。kafka 提供了类似 JMS 的特性,但是在设计和实现上是完全不同的,而且他也不是 JMS 规范的实现。
kafka 作为一个消息系统,早起设计的目的是用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)。活动流数据是所有的网站对用户的使用情况做分析的时候要用到的最常规的部分,活动数据包括页面的访问量(PV)、被查看内容方面的信息以及搜索内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性的对这些文件进行统计分析。运营数据指的是服务器的性能数据(CPU、IO 使用率、请求时间、服务日志等)。
由于 kafka 具有更好的吞吐量、内置分区、冗余及容错性的优点(kafka 每秒可以处理几十万消息),让 kafka 成为了一个很好的大规模消息处理应用的解决方案。所以在企业级应用长,主要会应用于如下几个方面
Ø 行为跟踪:kafka 可以用于跟踪用户浏览页面、搜索及其他行为。通过发布-订阅模式实时记录到对应的 topic 中,通过后端大数据平台接入处理分析,并做更进一步的实时处理和监控
Ø 日志收集:日志收集方面,有很多比较优秀的产品,比如 Apache Flume,很多公司使用kafka 代理日志聚合。日志聚合表示从服务器上收集日志文件,然后放到一个集中的平台(文件服务器)进行处理。在实际应用开发中,我们应用程序的 log 都会输出到本地的磁盘上,排查问题的话通过 linux 命令来搞定,如果应用程序组成了负载均衡集群,并且集群的机器有几十台以上,那么想通过日志快速定位到问题,就是很麻烦的事情了。所以一般都会做一个日志统一收集平台管理 log 日志用来快速查询重要应用的问题。所以很多公司的套路都是把应用日志几种到 kafka 上,然后分别导入到 es 和 hdfs 上,用来做实时检索分析和离线统计数据备份等。而另一方面,kafka 本身又提供了很好的 api 来集成日志并且做日志收集。
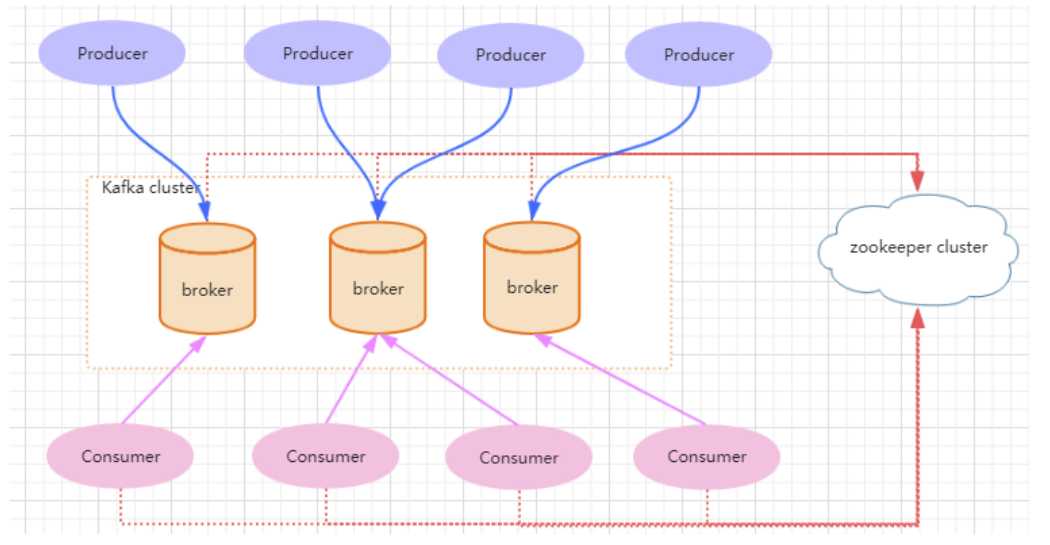
一个典型的 kafka 集群包含若干 Producer(可以是应用节点产生的消息,也可以是通过Flume 收集日志产生的事件),若干个 Broker(kafka 支持水平扩展)、若干个 Consumer Group,以及一个 zookeeper 集群。kafka 通过 zookeeper 管理集群配置及服务协同。Producer 使用 push 模式将消息发布到 broker,consumer 通过监听使用 pull 模式从broker 订阅并消费消息。多个 broker 协同工作,producer 和 consumer 部署在各个业务逻辑中。三者通过zookeeper 管理协调请求和转发。这样就组成了一个高性能的分布式消息发布和订阅系统。图上有一个细节是和其他 mq 中间件不同的点,producer 发送消息到 broker的过程是 push,而 consumer 从 broker 消费消息的过程是 pull,主动去拉数据。而不是 broker 把数据主动发送给 consumer。
1.下载安装包 :http://kafka.apache.org/downloads。
解压 : tar -zxvf kafka_2.11-1.1.0.tgz 这样子就安装好了。
2.启动/停止 kafka:
1. 需要先启动 zookeeper,如果没有搭建 zookeeper 环境,可以直接运行kafka 内嵌的 zookeeper
启动命令: bin/zookeeper-server-start.sh config/zookeeper.properties
如果连接外部zookeeper 需要修改 config/server.properties 配置文件来配置我们的zookeeper。修改如下信息。zk集群环境用逗号隔开。
zookeeper.connect=192.168.254.135:2181
这个时候可以通过 sh kafka-server-start.sh (-daemon) ../config/server.properties 命令来启动服务后台运行。若不加括号里的参数则在当前进程启动,按CTRL+c退出。
3.创建 一个名为 test 的 topic(在bin目录下) :Replication-factor 表示该 topic 需要在不同的 broker 中保存几份,这里设置成 1,表示在两个 broker 中保存两份。Partitions 分区
sh kafka-topics.sh --create --zookeeper 192.168.25.128:2181 --replication-factor 1 --partitions 1 --topic test
查看 topic 列表:
sh kafka-topics.sh --list --zookeeper 192.168.25.128:2181
4.发送消息:发送两条消息
sh kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic > This is a message > This is another message
5.启动消费者:
sh kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
在 3台机器上都配置上 zookeeper.connect=192.168.254.135:2181 信息。zk要是也做了集群用逗号分开
修改 server.properties 文件中 broker.id=0 ,在集群中这个 id 要求是唯一的,我们分别改成 1 2 3.
放开 listeners=PLAINTEXT://:9092 配置,修改为listeners=PLAINTEXT://本机IP:9092,然后先后启动就可以,注意这里先启动的,也就是先到zk上面去注册的就是 leader。
标签:请求 apache daemon 需要 管理 local trap 写入 tar
原文地址:https://www.cnblogs.com/flgb/p/10708425.html