标签:image 推荐 edr img mod 实现 pre nbsp end
Vi t1.txt
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
1.装载数据
scala> import org.apache.spark.mllib.recommendation.{ALS, Rating}
scala> val data = sc.textFile("hdfs://h201:9000/t1.txt")
2.解析原始数据
scala> val ratings = data.map(_.split(",") match { case Array(user, product, rate) =>
Rating(user.toInt, product.toInt, rate.toDouble)}).cache()
3.查看用户和物品
val users = ratings.map(_.user).distinct()
val products = ratings.map(_.product).distinct()
4.训练数据
rank是模型中隐性因子的个数
scala> val rank = 3
scala> val lambda = 0.01
scala> val numIterations = 2
scala> val model = ALS.train(ratings, rank, numIterations, lambda)
用户评估
scala> val a1=model.userFeatures
商品评估
scala> val a2=model.productFeatures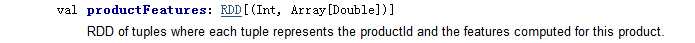
5.评测
val usersProducts= ratings.map { case Rating(user, product, rate) => (user, product)}
预测
var predictions = model.predict(usersProducts).map { case Rating(user, product, rate) =>((user, product), rate)}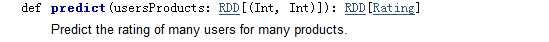
结果与 预测结果合并
val ratesAndPreds = ratings.map { case Rating(user, product, rate) =>((user, product), rate)}.join(predictions)
计算均方误差
val rmse= math.sqrt(ratesAndPreds.map { case ((user, product), (r1, r2)) =>
val err = (r1 - r2)
err * err
}.mean())
// mean()方法,求均值
6.为用户1 ,推荐top3个商品
scala> val userid = 1
scala> val k=3 (推荐个数)
scala> val topKRecs = model.recommendProducts(userid, k)
scala> println(topKRecs.mkString("\n"))
查看用户的历史打分
val goodsForUser=ratings.keyBy(_.user).lookup(1)
7.查看用户下 对某商品的 预测分
val predictedRating = model.predict(1,105)
8.批量推荐
scala> val users = ratings.map(_.user).distinct()
scala> users.collect.flatMap { user =>
model.recommendProducts(user, 3)}
Vi t1.txt
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
1.装载数据
scala> import org.apache.spark.mllib.recommendation.{ALS, Rating}
scala> val data = sc.textFile("hdfs://h201:9000/t1.txt")
2.解析原始数据
scala> val ratings = data.map(_.split(",") match { case Array(user, product, rate) =>
Rating(user.toInt, product.toInt, rate.toDouble)}).cache()
3. 查看用户和物品
val users = ratings.map(_.user).distinct()
val products = ratings.map(_.product).distinct()
4. 训练数据
rank是模型中隐性因子的个数
scala> val rank = 3
scala> val lambda = 0.01
scala> val numIterations = 2
scala> val model = ALS.train(ratings, rank, numIterations, lambda)
用户评估
scala> val a1=model.userFeatures
商品评估
scala> val a2=model.productFeatures
5. 评测
val usersProducts= ratings.map { case Rating(user, product, rate) => (user, product)}
预测
var predictions = model.predict(usersProducts).map { case Rating(user, product, rate) =>((user, product), rate)}
结果与 预测结果合并
val ratesAndPreds = ratings.map { case Rating(user, product, rate) =>((user, product), rate)}.join(predictions)
计算均方误差
val rmse= math.sqrt(ratesAndPreds.map { case ((user, product), (r1, r2)) =>
val err = (r1 - r2)
err * err
}.mean())
mean()方法,求均值
6.为用户1 ,推荐top3个商品
scala> val userid = 1
scala> val k=3 (推荐个数)
scala> val topKRecs = model.recommendProducts(userid, k)
scala> println(topKRecs.mkString("\n"))
查看用户的历史打分
val goodsForUser=ratings.keyBy(_.user).lookup(1)
7.查看用户下 对某商品的 预测分
val predictedRating = model.predict(1,105)
8.批量推荐
scala> val users = ratings.map(_.user).distinct()
scala> users.collect.flatMap { user =>
model.recommendProducts(user, 3)}
标签:image 推荐 edr img mod 实现 pre nbsp end
原文地址:https://www.cnblogs.com/xiguage119/p/10722954.html