标签:png 存储 读取 使用 blog create 指定 制造 fir
AMQP
定义
AMQP(Advanced Message Queuing Protocol,高级消息队列协议)是一个进程间传递异步消息的网络协议。
模型图
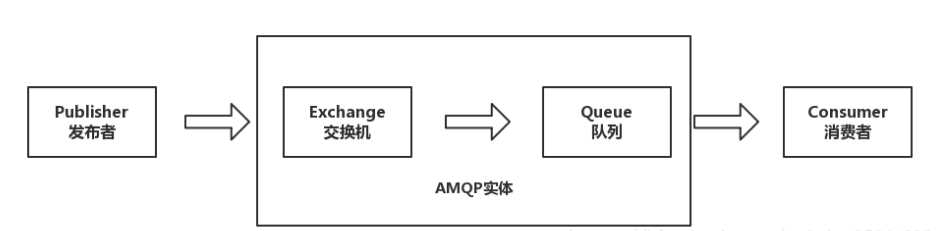
工作过程
发布者(Publisher)发布消息(Message),经由交换机(Exchange)。
交换机根据路由规则将收到的消息分发给与该交换机绑定的队列(Queue)。
最后 AMQP 代理会将消息投递给订阅了此队列的消费者,或者消费者按照需求自行获取。
应用场景
对于一个大型的软件系统来说,它会有很多的组件或者说模块或者说子系统或者(subsystem or Component or submodule)。那么这些模块的如何通信?这和传统的IPC有很大的区别。传统的IPC很多都是在单一系统上的,模块耦合性很大,不适合扩展(Scalability);如果使用socket那么不同的模块的确可以部署到不同的机器上,但是还是有很多问题需要解决。比如:
1)信息的发送者和接收者如何维持这个连接,如果一方的连接中断,这期间的数据如何方式丢失?
2)如何降低发送者和接收者的耦合度?
3)如何让Priority高的接收者先接到数据?
4)如何做到load balance?有效均衡接收者的负载?
5)如何有效的将数据发送到相关的接收者?也就是说将接收者subscribe 不同的数据,如何做有效的filter。
6)如何做到可扩展,甚至将这个通信模块发到cluster上?
7)如何保证接收者接收到了完整,正确的数据?
AMDQ协议解决了以上的问题,而RabbitMQ实现了AMQP。
参考文档
https://blog.csdn.net/weixin_37641832/article/details/83270778
https://www.cnblogs.com/dwlsxj/p/RabbitMQ.html
https://blog.csdn.net/anzhsoft/article/details/19563091
http://rabbitmq.mr-ping.com/
RabbitMQ
定义
RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现
https://www.rabbitmq.com/
生产者(Product)
发布消息到消息队列服务中。
交换机(Exchange)
生产者的消息并不能直接到Queue中,而是经过交换机分配的。一个消息可以分配给一个或者多个queue,分配通过bind进行的。
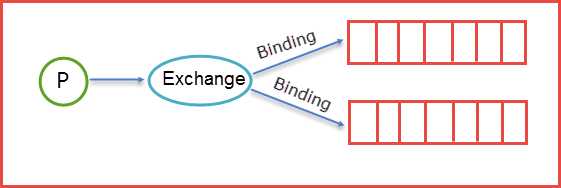
在绑定(Binding)Exchange和Queue的同时,一般会指定一个Binding Key,生产者将消息发送给Exchange的时候,一般会产生一个Routing Key,当Routing Key和Binding Key对应上的时候,消息就会发送到对应的Queue中去。那么Exchange有四种类型,不同的类型有着不同的策略。也就是表明不同的类型将决定绑定的Queue不同,换言之就是说生产者发送了一个消息,Routing Key的规则是A,那么生产者会将Routing Key=A的消息推送到Exchange中,这时候Exchange中会有自己的规则,对应的规则去筛选生产者发来的消息,如果能够对应上Exchange的内部规则就将消息推送到对应的Queue中去。那么接下来就来详细讲解下Exchange里面类型。
Exchange Type
我来用表格来描述下类型以及类型之间的区别。
fanout类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中。
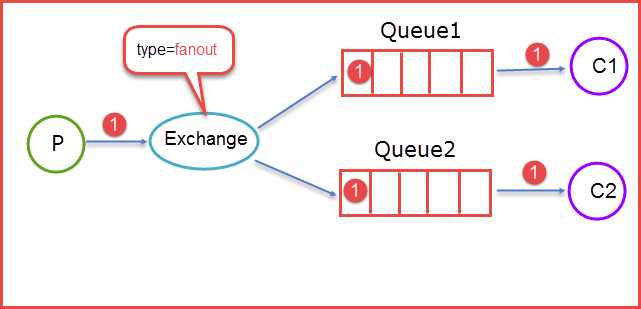
上图所示,生产者(P)生产消息1将消息1推送到Exchange,由于Exchange Type=fanout这时候会遵循fanout的规则将消息推送到所有与它绑定Queue,也就是图上的两个Queue最后两个消费者消费。
direct类型的Exchange路由规则也很简单,它会把消息路由到那些binding key与routing key完全匹配的Queue中
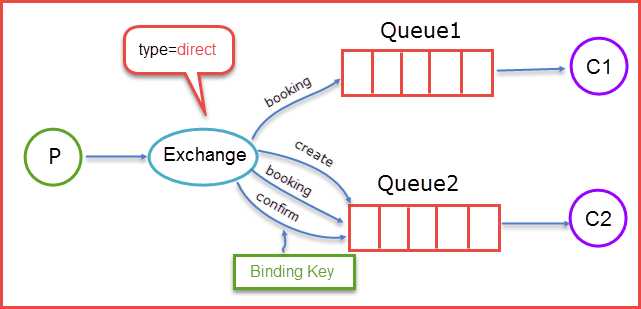
当生产者(P)发送消息时Rotuing key=booking时,这时候将消息传送给Exchange,Exchange获取到生产者发送过来消息后,会根据自身的规则进行与匹配相应的Queue,这时发现Queue1和Queue2都符合,就会将消息传送给这两个队列,如果我们以Rotuing key=create和Rotuing key=confirm发送消息时,这时消息只会被推送到Queue2队列中,其他Routing Key的消息将会被丢弃。
前面提到的direct规则是严格意义上的匹配,换言之Routing Key必须与Binding Key相匹配的时候才将消息传送给Queue,那么topic这个规则就是模糊匹配,可以通过通配符满足一部分规则就可以传送。它的约定是:
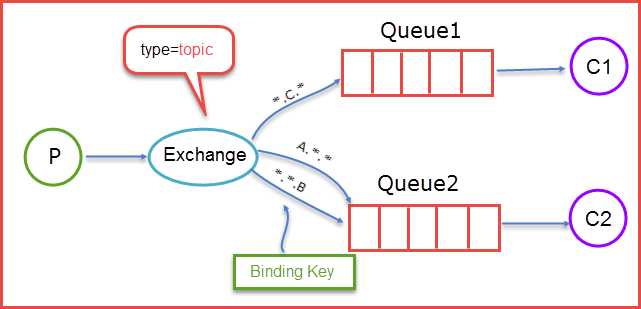
当生产者发送消息Routing Key=F.C.E的时候,这时候只满足Queue1,所以会被路由到Queue中,如果Routing Key=A.C.E这时候会被同是路由到Queue1和Queue2中,如果Routing Key=A.F.B时,这里只会发送一条消息到Queue2中。
headers类型的Exchange不依赖于routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。
在绑定Queue与Exchange时指定一组键值对;当消息发送到Exchange时,RabbitMQ会取到该消息的headers(也是一个键值对的形式),对比其中的键值对是否完全匹配Queue与Exchange绑定时指定的键值对;如果完全匹配则消息会路由到该Queue,否则不会路由到该Queue。
该类型的Exchange没有用到过(不过也应该很有用武之地),所以不做介绍。
这里在对其进行简要的表格整理:
| 类型名称 | 类型描述 |
| fanout | 把所有发送到该Exchange的消息路由到所有与它绑定的Queue中 |
| direct | Routing Key==Binding Key |
| topic | 我这里自己总结的简称模糊匹配 |
| headers | Exchange不依赖于routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。 |
队列Queue
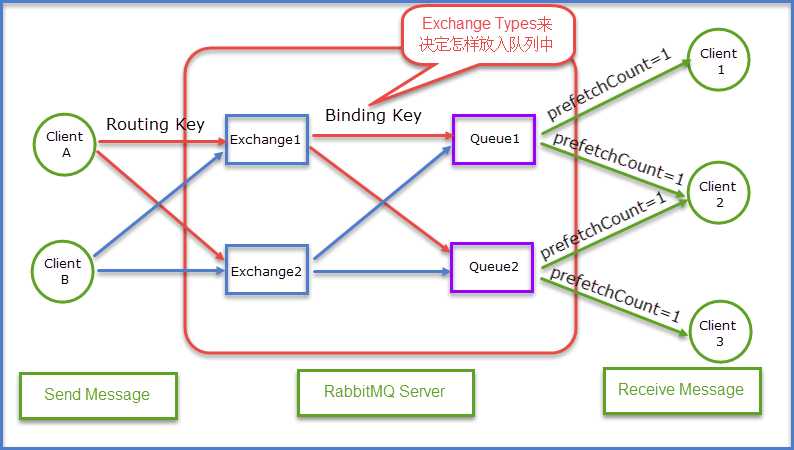
Queue(队列)RabbitMQ的作用是存储消息,队列的特性是先进先出。上图可以清晰地看到Client A和Client B是生产者,生产者生产消息最终被送到RabbitMQ的内部对象Queue中去,而消费者则是从Queue队列中取出数据。可以简化成表示为:

生产者Send Message “A”被传送到Queue中,消费者发现消息队列Queue中有订阅的消息,就会将这条消息A读取出来进行一些列的业务操作。这里只是一个消费正对应一个队列Queue,也可以多个消费者订阅同一个队列Queue,当然这里就会将Queue里面的消息平分给其他的消费者,但是会存在一个一个问题就是如果每个消息的处理时间不同,就会导致某些消费者一直在忙碌中,而有的消费者处理完了消息后一直处于空闲状态,因为前面已经提及到了Queue会平分这些消息给相应的消费者。这里我们就可以使用prefetchCount来限制每次发送给消费者消息的个数。详情见下图所示:
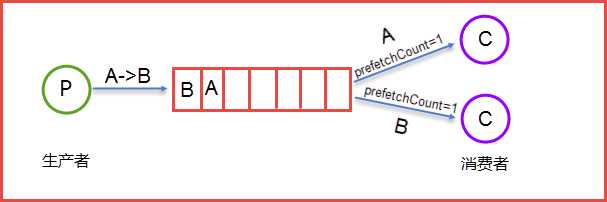
这里的prefetchCount=1是指每次从Queue中发送一条消息来。等消费者处理完这条消息后Queue会再发送一条消息给消费者。
基础对象
ConnectionFactory、Connection、Channel都是RabbitMQ对外提供的API中最基本的对象。Connection是RabbitMQ的socket链接,它封装了socket协议相关部分逻辑。ConnectionFactory为Connection的制造工厂。
Channel是我们与RabbitMQ打交道的最重要的一个接口,我们大部分的业务操作是在Channel这个接口中完成的,包括定义Queue、定义Exchange、绑定Queue与Exchange、发布消息等。
Connection就是建立一个TCP连接,生产者和消费者的都是通过TCP的连接到RabbitMQ Server中的,这个后续会再程序中体现出来。
Channel虚拟连接,建立在上面TCP连接的基础上,数据流动都是通过Channel来进行的。为什么不是直接建立在TCP的基础上进行数据流动呢?如果建立在TCP的基础上进行数据流动,建立和关闭TCP连接有代价。频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建立Channel是没有上述代价的。
标签:png 存储 读取 使用 blog create 指定 制造 fir
原文地址:https://www.cnblogs.com/wudequn/p/10640029.html