标签:pipeline pip 大数据 线数据 流式 tensor 文字 讲解 第一部分
研究大数据和数据挖掘的都知道,并行化算法研究是大数据领域一个较为重要的研究热点。近年来国内外开始关注在 Spark 平台上如何实现各种机器学习和数据挖掘并行化算法设计。
Spark 提供了大量的库,包括SQL、DataFrames、MLlib、GraphX、Spark Streaming。 开发者可以在同一个应用程序中无缝组合使用这些库。
《深度实践Spark机器学习》系统讲解了Spark机器学习的技术、原理、组件、算法,以及构建Spark机器学习系统的方法、流程、标准和规范。此外,还介绍了Spark的深度学习框架TensorFlowOnSpark,以及如何借助它实现卷积神经网络和循环神经网络。
学习参考:
《深度实践Spark机器学习》PDF,247页,带书签目录,文字可以复制;
作者 吴茂贵等。
下载:https://pan.baidu.com/s/15l70-TlT0zomyxUroNjJCA
提取码: aab6
全书共14章,分为四个部分:
第一部分(1~7章)
主要讲解了Spark机器学习的技术、原理和核心组件,包括Spark ML、Spark ML Pipeline、Spark MLlib,以及如何构建一个Spark
机器学习系统。
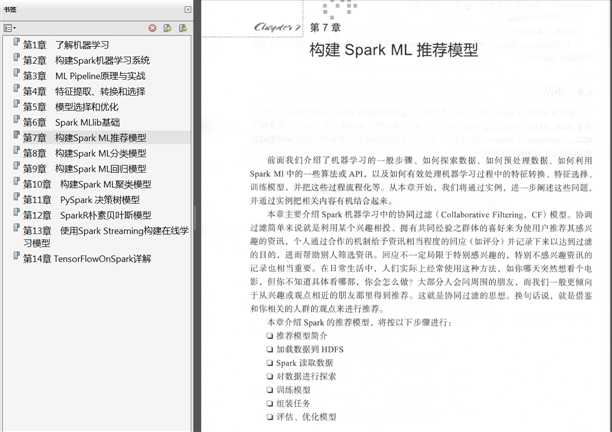
第二部分(8~12章)
主要以实例为主,讲解了Spark ML的各种机器学习算法,包括推荐模型、分类模型、聚类模型、回归模型,以及PySpark决策
树模型和Spark R朴素贝叶斯模型。
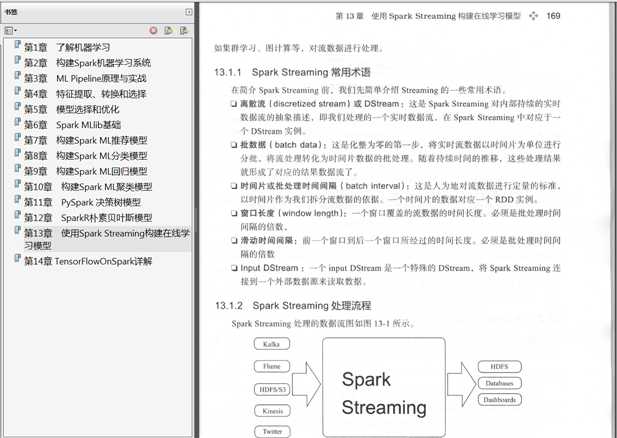
第三部分(第13章)
与之前的批量处理不同,本章以在线数据或流式数据为主,讲解了Spark的流式计算框架Spark Streaming。
第四部分(第14章)
介绍了Spark深度学习,主要包括TensorFlow的基础知识及它与Spark的整合框架TensorFlowOnSpark。
标签:pipeline pip 大数据 线数据 流式 tensor 文字 讲解 第一部分
原文地址:https://www.cnblogs.com/jiaomx/p/10739676.html