标签:location default 文本格式 none input col mat 不必要 场景
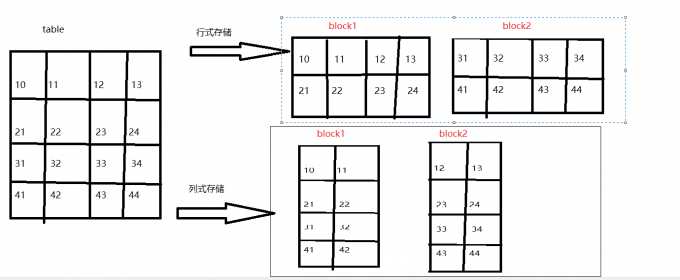
【注意】hive默认的文件格式是TextFile,可通过set hive.default.fileformat 进行配置
hive中的文件格式的简介
原文地址:https://www.cnblogs.com/xuziyu/p/10737199.html