标签:合规 code http 简单 函数 inf local 第一个 findall
1、
def f(x,l=[]): for i in range(x): l.append(i*i) print(l) f(2) f(3,[3,2,1]) f(3)
考查知识点:列表,深浅copy。弄清楚就ok
[0, 1] [3, 2, 1, 0, 1, 4] [0, 1, 0, 1, 4]
2、
用python , 123456789变成987654321‘
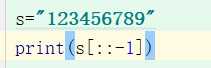
太简单
考查知识点:切片
3、
python 的re模块中match() search()findall() compile()的区别
match与search函数功能一样,match匹配字符串开始的第一个位置,search是在字符串全局匹配第一个符合规则的。
简单来说就是:
re.match与re.search的区别:re.match只匹配字符串的开始,
如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
而re.search匹配整个字符串,直到找到一个匹配。
re.findall函数返回的总是正则表达式在字符串中所有匹配结果的列表list,此处主要讨论列表中“结果”的展现方式,即findall中返回列表中每个元素包含的信息。
使用re的一般步骤是先使用re.compile()函数,将正则表达式的字符串形式编译为Pattern实例,
然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
4、a/b/.././c/QN1UH78VKP2T7)IA]ZM(FW.gif) estips变成a/c/test.jpg变成a/c/test.jpg
estips变成a/c/test.jpg变成a/c/test.jpg
为上一级为本级
稍微欠缺的方法,这个写死了:
s="a/b/.././c/test.jpg" s1=s.split("/") s1.pop(s1.index("..")-1) s1.pop(s1.index("..")) s1.pop(s1.index(".")) l = [] for i in s1: l.append(i) print("/".join(l))
正常思路:
s="a/b/.././c/test.jpg" s1=s.split("/") l = [] for i in s1: if i == "..": l.pop() elif i == ".": continue else: l.append(i) print("/".join(l))
考查知识点:列表的几个常用方法
99乘法表
for x in range(1, 10): for y in range(1, x+1): print("%s*%s=%s" % (y, x, x * y), end=‘ ‘) print() # print默认参数‘换行’,没有此条语句输出打印时将不会换行
一行代码实现:
print(‘\n‘.join([‘ ‘.join([‘{}*{}={}‘.format(y,x,y*x) for y in range(1, x+1)]) for x in range(1,10)]))
6、
找到1000以内的龙腾数,各个位数的和为5的数为龙腾数
for i in range(1000): a = i // 100 # 获得百位上的数字 b = i // 10 % 10 # 获得十位数的数字 c = i % 10 # 获得个位数的数字 if a + b + c == 5: print(i)
主要思路:怎么获取百位数字,用这个数整除100就会得到百位上的数字
怎么获取十位数字,用这个数整除10再对10取余,就会得到十位上的数字
怎么获取个位上的数字,用这个数对10取余就会得到个位上的数字
7、
python给一个有序列表,求出插入值的索引
def index(nlist, k): if k < nlist[0]: # 假如插入的元素比第一个元素小,则就直接插在第一个元素的位置,第一个元素的索引是0 p = 0 elif k > nlist[-1]: # 假如插入的元素比最后一个元素大,则就直接插在最后元素的位置,最后一个元素的索引为len(l)-1 p = len(nlist) - 1 else: p = 0 # p=0归位 for item in nlist: # 然后对传过来的列表进行循环打印 if k < item: # 判断插入的元素的大小 break # 直到插入的元素大于item了 p += 1 return p lis = [1, 3, 5, 7, 8, 9, 11] result = index(lis, 10) print(result)
8、
赋值是指向同一个对象吗
在python中,对象的赋值就是简单的对象引用
赋值操作(包括对象作为参数、返回值)不会开辟新的内存空间,它只是复制了新对象的引用。也就是说,除了list_b这个名字以外,没有其它的内存开销。
浅拷贝会创建新对象,其内容是原对象的引用。
深拷贝:和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。因而,它的时间和空间开销要高。
总结:赋值是指的同一个对象。
深浅拷贝都是创建了新对象。
标签:合规 code http 简单 函数 inf local 第一个 findall
原文地址:https://www.cnblogs.com/hnlmy/p/10738087.html