标签:nbsp 分界线 处理 高斯分布 范围 weight 高斯 inf 场景
一、SVM目标和原理
svm分为线性可分和线性不可分两种
线性可分:
svm.SVC(C=0.8, kernel=‘linear‘, class_weight={-1:1, 1:20})
线性不可分: 使用径向基(高斯)核函数
svm.SVC(C=0.8, kernel=‘rbf‘, class_weight={-1: 1, 1: 10})
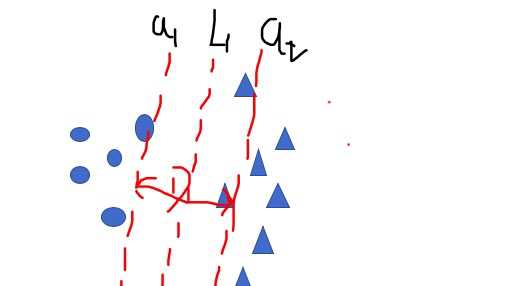
目标函数:所有样本点到所有可能分界线最小值中的最大值即为目标函数
找到目标函数之前首先要找到支撑向量。分界线L1具有无数条,需要在可行范围内使得D的值达到最大
二、SVM损失
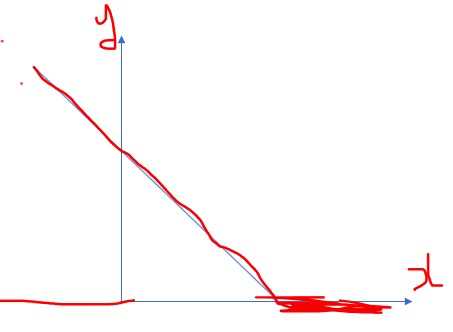
svm分类器即便分类是正确的的也会存在损失,其损失是在支撑向量和切分线之前的样本 距离切分线的距离
三、SVM参数
C值越大支撑向量距离切分线的距离越近,C值越小支撑向量距离切分线的距离越远
gamma 是高斯分布的一个参数,可以理解为其最大直径的 大小
四、适合场景
svm的训练效果和泛华是比较好的但是训练的时间长,适合处理特征少量或者中等的数据,特征多的可以选择logistics回归
标签:nbsp 分界线 处理 高斯分布 范围 weight 高斯 inf 场景
原文地址:https://www.cnblogs.com/bianjing/p/10752633.html