标签:col 存储 final 内存 线程 process http key res
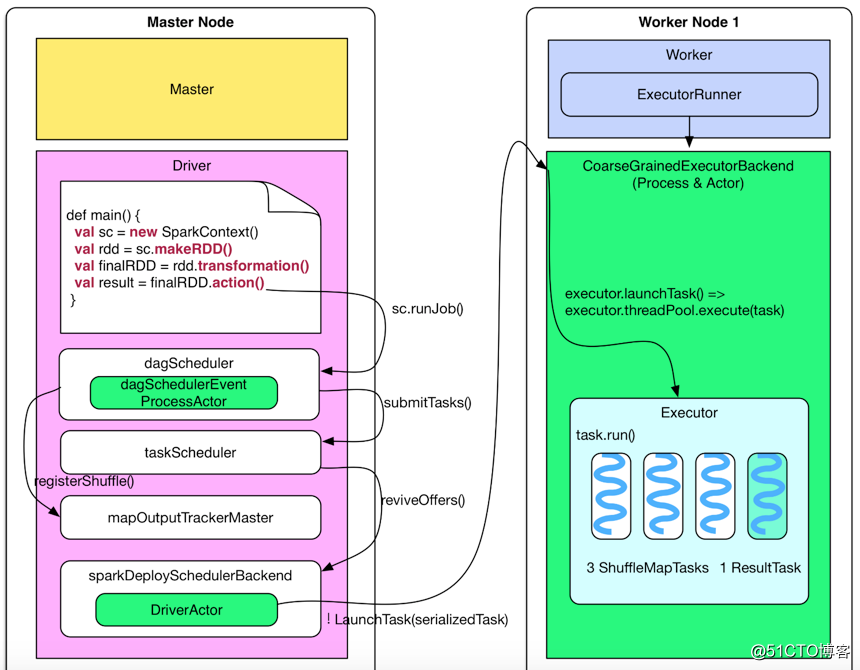
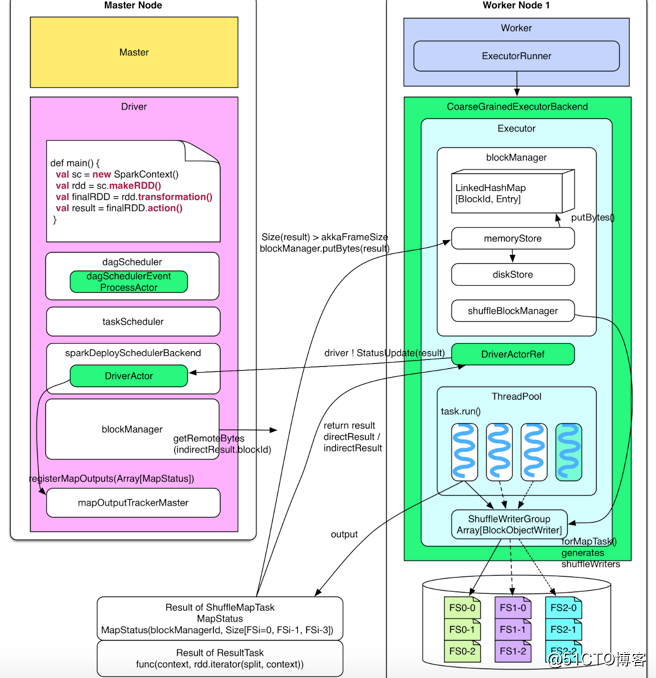
上图是task执行流程,具体执行过程如下
spark(二):spark架构及物理执行图
原文地址:https://blog.51cto.com/4876017/2382943