标签:header parent footer relative 存在 edit 输入 特征 lis
——只能学习到相对简单的模型
shadow method:
——不能充分的发挥 end-to-end 训练的优势.
SGD 微调:
——需要在待跟踪视频上执行 SGD 算法来微调参数, 无法达到实时性的要求.
训练一个 Siamese 网络, 利用相似性计算来实现在搜索图片(search image )上定位范例图片(exemplar image).
从被标注的视频(每帧中的目标都被 bounding box 框出)中获取用于训练的图片对, 两张图片的帧间隔小于T.
search image:
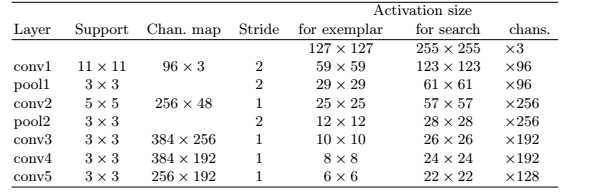
以目标为中心的大小为255*255的图片, 超出原图的区域用合理的RGB值填充, 不对原图进行缩放.
exemplar image:
以目标为中心的大小为127*127的图片. 具体地, 若 bounding box(红色框) 的大小为 (w, h), padding 的大小为 p, 则调整因子 s 由以下约束决定:



由于训练帧的目标都在图片中心, 故而训练帧对应的分数矩阵(score map, 具体意义参见网络结构)的值由如下规则给出: 距离分数矩阵(score map)中心 R 以内的点为正例, 其他点为反例.(需考虑 stride 值, 其中stride值为搜索图片中选出候选图片时的步长, 由φ网络中的池化层决定)

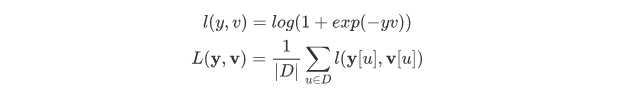
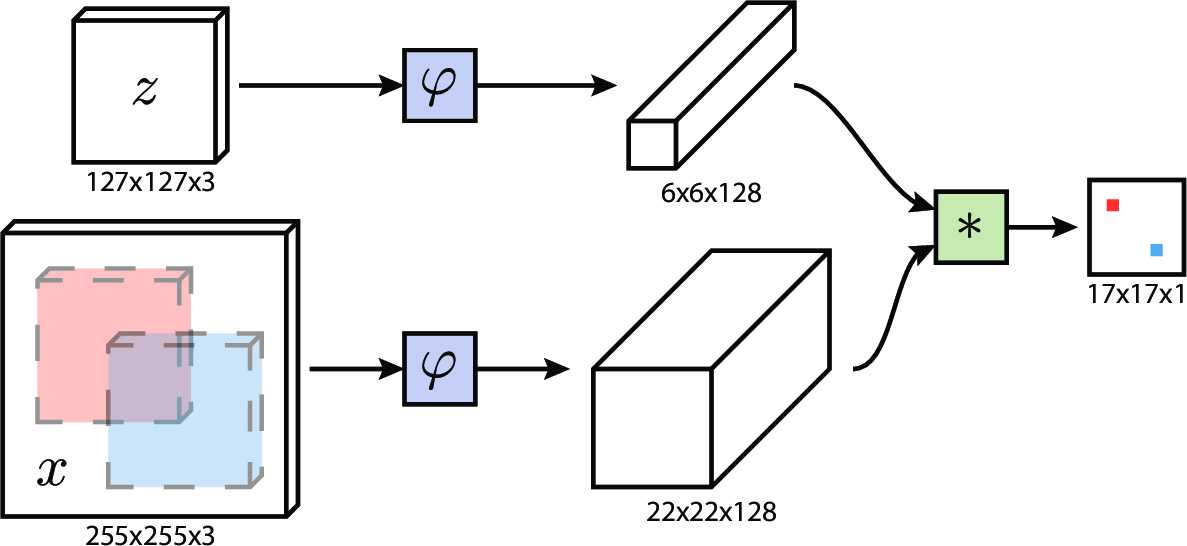


以一对训练图片为例, 将范例图片(exemplar image)喂给上图中的 z, 将搜索图片(search image) 喂给上图中的 x , 之后进行前向传播得到分数矩阵(score map), 根据训练标注中所定义的作为 ground truth 的分数矩阵计算loss 执行反向传播算法更新全卷积网络 φ 中的参数.
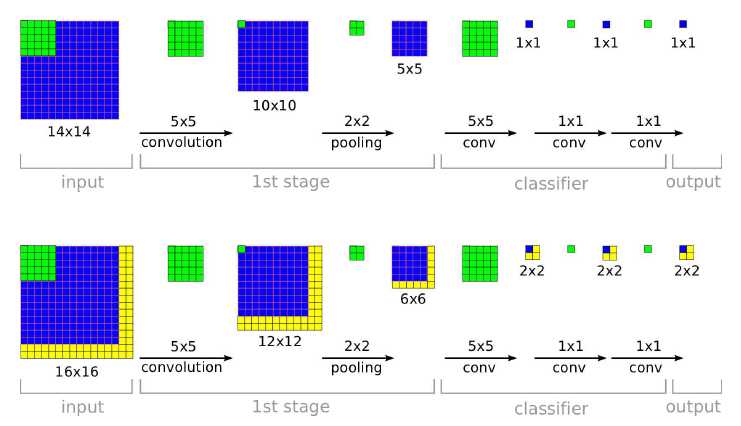
输入大小可变
计算共享

标签:header parent footer relative 存在 edit 输入 特征 lis
原文地址:https://www.cnblogs.com/USTC-manker/p/10755473.html