假设文本中的内容为:
aaaa
bbbb
ccccc
dddd
要求将文本内容处理为:
aaaa bbbb
cccc dddd
(中间以制表符分隔)
方法一:
sed -n ‘{N;s/\n/\t/p}‘ test.txt
方法二:
awk ‘{tmp=$0;getline;print tmp"\t"$0}‘ test.txt
昨天写一个脚本花了一天的2/3的时间,而且大部分时间都耗在了sed命令上,今天不总结一下都对不起昨天流逝的时间啊~~~
用sed命令在行首或行尾添加字符的命令有以下几种:
假设处理的文本为test.file

在每行的头添加字符,比如"HEAD",命令如下:
sed ‘s/^/HEAD&/g‘ test.file
在每行的行尾添加字符,比如“TAIL”,命令如下:
sed ‘s/$/&TAIL/g‘ test.file
运行结果如下图:

几点说明:
1."^"代表行首,"$"代表行尾
2.‘s/$/&TAIL/g‘中的字符g代表每行出现的字符全部替换,如果想在特定字符处添加,g就有用了,否则只会替换每行第一个,而不继续往后找了
例:
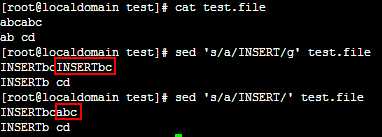
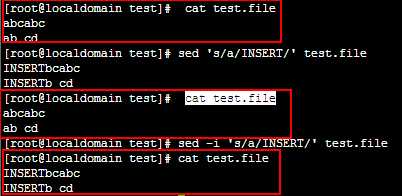
3.如果想导出文件,在命令末尾加"> outfile_name";如果想在原文件上更改,添加选项"-i",如
4.也可以把两条命令和在一起,在test.file的每一行的行头和行尾分别添加字符"HEAD"、“TAIL”,命令:sed ‘/./{s/^/HEAD&/;s/$/&TAIL/}‘ test.file
以上其实都还OK,昨天花太多时间,主要因为被处理的文件是用mysql从数据库提取的结果导出来的,别人给我之后我就直接处理,太脑残了= -我一直有点怀疑之所以结果不对,有可能是windows和linux换行的问题,可是因为对sed不熟,就一直在搞sed。。。。。。。
众所周知(= -),window和linux的回车换行之云云,如果你知道了,跳过这一段,不知道,读一下呗:
Unix系统里,每行结尾只有“<换行>”,即“\n”;Windows系统里面,每行结尾是“<换行><回 车>”,即“\n\r”。一个直接后果是,Unix系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix下打开的话,在每行的结尾可能会多出一个^M符号。
好了,所以我的问题就出在被处理的文件的每行末尾都有^M符号,而这通常是看不出来的。可以用"cat -A test.file"命令查看。因此当我想在行尾添加字符的时候,它总是添加在行首且会覆盖掉原来行首的字符。
要把文件转换一下,有两种方法:
1.命令dos2unix test.file
2.去掉"\r" ,用命令sed -i ‘s/\r//‘ test.file
好了,这样处理完,就OK啦!!!