标签:public rop accept 研究 dataset 实时 机构 rip 代码实现

卧龙岗大学,第一次听说这个学校。竟然是在澳大利亚的一个学校。好吧,华人果然全球了
使用一个加权协方差因子,来积累前几帧的信息,使用增强学习来实现online learning,可以不用使用分好段的视频来预测动作
#############################################################

前人研究的主要分类方法,缺点是没有办法实时检测

视频动作的特征表现,主要依靠这两种
主要介绍了一下,上面两种分类方法,主要的几个研究方法,讲了一下这些的缺点。

特别强调了一个苏联人的一个方法,并讲解自己的文字解决了他的两个问题:没有权重的对待不同帧
权重方差因子:


时间权重的变化:
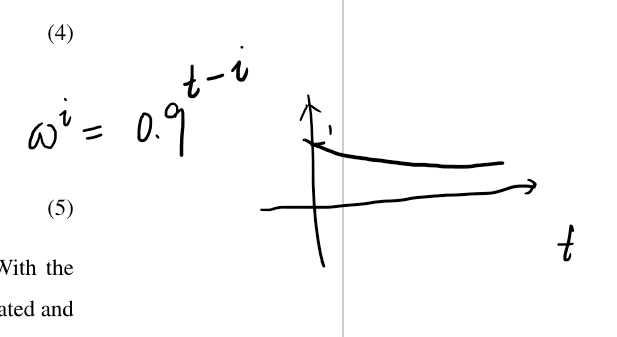
帧权重的变化:

这里,能量是结点的动量和势能。
增量学习:

后面还给予了证明。
一些度量性能。还有结果展示

后面使用了一些去噪和归一化
动作特征向量的选取:

使用KNN和SVM进行特征分类
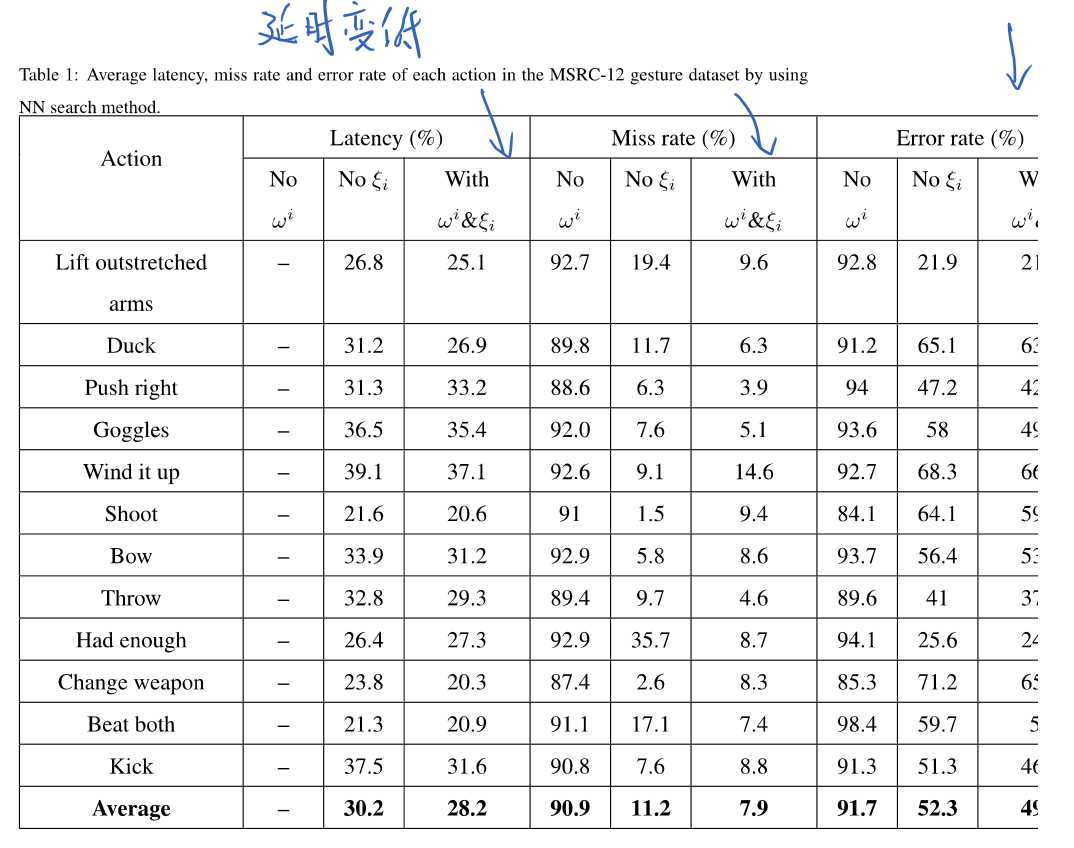
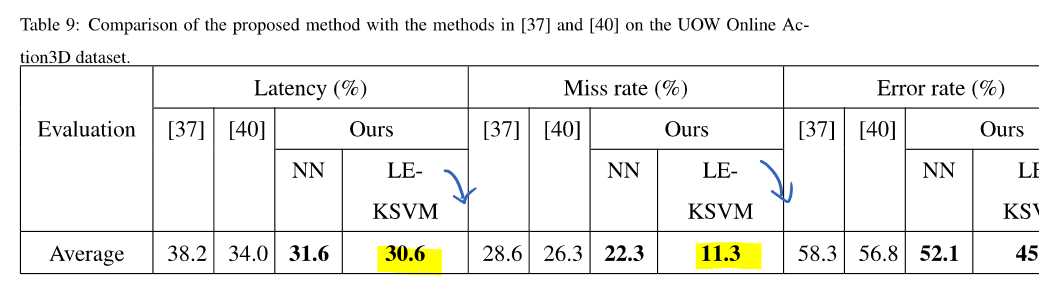
展示了在三个数据集上面的结果:


最后一种数据集,是卧龙岗大学自己创造的,适合增量学习。
5The depth and skeleton data will be made available after the paper being accepted for publication at:
http://www.uow.edu.au/˜wanqing/#UOWActionDatasets
https://www.uow.edu.au/~wanqing/#UOWActionDatasets
最后讲解了使用的硬件情况:

以及对比,KNN和SVM的情况:
标签:public rop accept 研究 dataset 实时 机构 rip 代码实现
原文地址:https://www.cnblogs.com/captain-dl/p/10759693.html