标签:his 数字 要求 [] 结果 cti 开始 汉字 图片
常用的匹配规则:
\w——匹配字母、数字、下划线,等价于[a-zA-Z0-9_] \w可以匹配汉字(python),
\W——匹配不是字母、数字、下划线的其他字符
\s——匹配任意空白字符,等价于(\t\n\r\f)
\S——匹配任意非空字符
\d——匹配数字,等价于[0-9]
\D——匹配不是数字的字符
\A——匹配字符串开头
\Z——匹配字符串结尾的,如果存在换行,只匹配到换行前的结束字符串
\z——匹配字符串结尾的,如果存在换行,匹配到换行符\n
\G——最好完成匹配的位置
\n——匹配一个换行符
\t——匹配一个制表符(tab)
^——匹配一行字符串的开头
$——匹配一行字符串的结尾
. ——匹配任意字符,除了换行符.当re.DOTALL标记被指定时,这可以匹配包括换行符在内的任字符
[...]——用来表示一组字符,比如[abc]表示匹配a或b或c,[a-z],[0-9]
[^...]——匹配不在[]里面的字符,比如[^abc]匹配除a,b,c以外的字符
* ——匹配0个或多个字符
+ ——匹配1个或多个字符
?——匹配0个或1个前面的正则表达式片段,(.*?)表示尽可能少地匹配字符(后面详解)
{n}——精确匹配前面n个前面的表达式,如\d{5}表示匹配5个数字
{n,m}——匹配前面的表达式n到m次,贪婪模式
a|b——匹配a或者b
()——匹配括号里的表达式,也可以表示一个组
二、常用方法:
1、math()
math()会尝试从字符串的起始位置匹配正则表达式;
import re content = ‘Hello 123 4567 World _This is a Regex Demo‘ print(len(content)) result = re.match(‘^Hello.*is‘, content)#.*——多个字符Hello开始的字符串,is结束的字符串 print(result) print(result.group())#group()方法输出匹配到的内容 print(result.span())#span()方法输出匹配范围
结果:

match()方法只能从字符串开头匹配,如果开头不匹配就失败,例如:
import re content = ‘Hello 123 4567 World _This is a Regex Demo‘ print(len(content)) result = re.match(‘^llo.*is‘, content) print(result)
结果:

2、search()
search()匹配时会扫描整个字符串
例如上面提到的
import re content = ‘Hello 123 4567 World _This is a Regex Demo‘ print(len(content)) result = re.search(‘llo.*is‘, content) print(result)
结果:
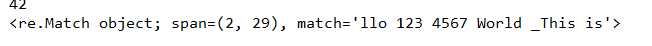
但如果有多个符合匹配信息的内容,只能得到第一个,例如:
import re html=‘‘‘div id=" songs -list"><h2 class-"title">经典老 歌</h2><p class="introduction">经典老歌列表</p: <ul id="list" class="list-group"<1i data-view="2">- -路上有你</li><11 data-view "7"> <a href-"/2.mp3" singer"任贤齐">沧海一声笑</a></li> <li data-view="4" class-"active"s <a href="/3.mp3" singer"齐秦">往事随风</a></li> <li data-view"6"><a htef="/4.mp3"singer "bynd">光辉岁月</a></11><li data-view-"5" shref:"/6.mp" snge."邓丽君”>但愿人长久</a></li></ul> ? </div>‘‘‘ result = re.search(‘<li.*?singer=*(.*?)>(.*?)</a>‘, html,re.S)#re.S匹配包括换行符在内的所有字符 if result: print(result.group(1),result.group(2))
结果:
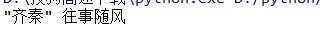
可以看到,满足要求的很多,但是只得到第一个
3、findall()
匹配时会扫描整个字符串,并且返回匹配的所有内容
import re html=‘‘‘div id=" songs -list"><h2 class-"title">经典老歌 </h2><p class="introduction"> 经典老歌列表</p: <ul id="list" class="list-group" <1i data-view="2">- -路上有你</li> <11 data-view "7"> <a href-"/2.mp3" singer"任贤齐">沧海一声笑</a> </li> <li data-view="4" class-"active"s <a href="/3.mp3" singer"齐秦">往事随风</a> </li> <li data-view"6"><a href="/4.mp3"singer="beyond">光辉岁月</a> </1i> <li data-view-"5"> <a href="/6.mp" singer="邓丽君”>但愿人长久</a> </li> </ul> </div>‘‘‘ result = re.findall(‘<li.*?singer=*(.*?)">(.*?)</a>‘, html,re.S) print(result)
结果:

4、sub()
5、compile()
标签:his 数字 要求 [] 结果 cti 开始 汉字 图片
原文地址:https://www.cnblogs.com/jcb9426986/p/10771679.html