标签:详解 des odi rgs 方式 状态 bsp 通过 代码
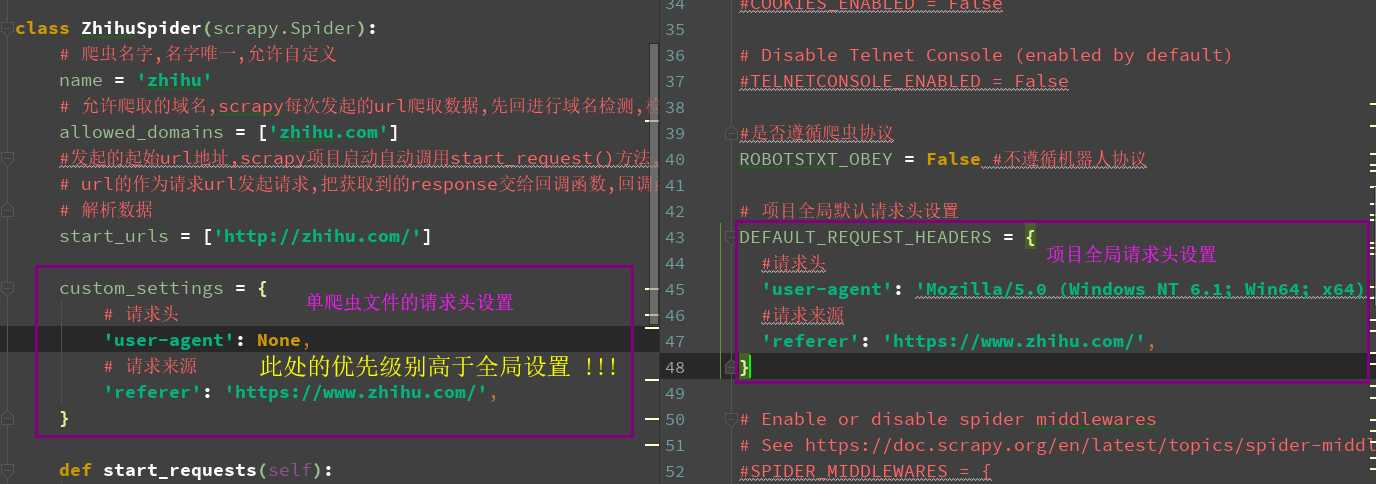
# -*- coding: utf-8 -*- import scrapy class ZhihuSpider(scrapy.Spider): # 爬虫名字,名字唯一,允许自定义 name = ‘zhihu‘ # 允许爬取的域名,scrapy每次发起的url爬取数据,先回进行域名检测,检测通过就爬取 allowed_domains = [‘zhihu.com‘] #发起的起始url地址,scrapy项目启动自动调用start_request()方法,把start_urls # url的作为请求url发起请求,把获取到的response交给回调函数,回调函数传递给parse # 解析数据 start_urls = [‘http://zhihu.com/‘] custom_settings = { # 请求头 ‘user-agent‘: None, # 请求来源 # ‘referer‘: ‘https://www.zhihu.com/‘, } def start_requests(self): ‘重写start_requests方法‘ for url in self.start_urls: #自定义解析方法 yield scrapy.Request(url=url,method=‘Get‘,callback=self.define_parse) def parse(self, response): pass def define_parse(self,response): print(response) #输出状态码 self.logger.info(response.status)
访问知乎不携带请求参数,返回400

两种请求头的书写方式如下(左:spisder, 右:settings.py)
allowed_domains
允许爬取的域名,scrapy每次发起的url爬取数据,先回进行域名检测,检测通过就爬取
start_urls
发起的起始url地址,scrapy项目启动自动调用start_request()方法,把start_urlsurl的作为请求url发起请求,把获取到的response交给回调函数,回调函数传递给parse解析数据
settings
全局的配置文件
logger
日志信息,使用=python自带的log模块
start_requests()
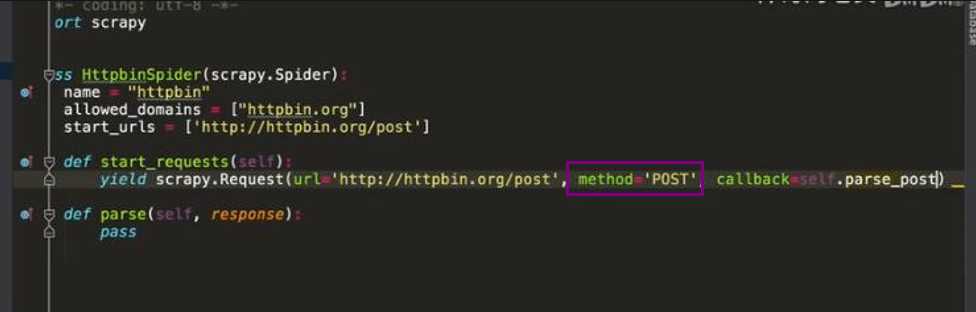
class MySpider(scrapy.Spider): name = ‘myspider‘ def start_requests(self): #使用FormRequest提交数据 return [scrapy.FormRequest("http://www.example.com/login", formdata={‘user‘: ‘john‘, ‘pass‘: ‘secret‘}, callback=self.logged_in)] def logged_in(self, response): pass
post 请求
parse(response)
参数:response(Response) - 对解析的响应
指定解析函数,可以扩展多个函数,多层次的解析方法.
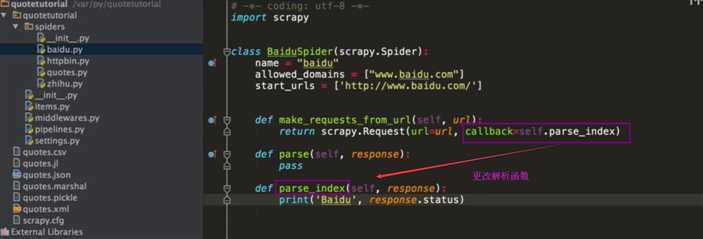
spider 启动参数配置
import scrapy class MySpider(scrapy.Spider): name = ‘myspider‘ def __init__(self, category=None, *args, **kwargs): super(MySpider, self).__init__(*args, **kwargs) self.start_urls = [‘http://www.example.com/categories/%s‘ % category]
命令行中调用
scrapy crawl myspider -a category=electronics
标签:详解 des odi rgs 方式 状态 bsp 通过 代码
原文地址:https://www.cnblogs.com/angle6-liu/p/10730410.html