标签:示例 example href period ESS 处理 blank dpi training
回归(Regression):https://www.tensorflow.org/tutorials/keras/basic_regression
主要步骤:
数据部分
模型部分
Attribute Information:
回调函数是一个函数的合集,在训练的阶段中,用来查看训练模型的内在状态和统计。
在训练时,相应的回调函数的方法就会被在各自的阶段被调用。
一般是在model.fit函数中调用callbacks(参数为callbacks,必须输入list类型的数据)。
简而言之,Callbacks用于指定在每个epoch开始和结束的时候进行哪种特定操作。
EarlyStopping是Callbacks的一种,可用来加快学习的速度,提高调参效率。
使用一个EarlyStopping回调来测试每一个迭代的训练条件,如果某个迭代过后没有显示改进,自动停止训练。
GitHub:https://github.com/anliven/Hello-AI/blob/master/Google-Learn-and-use-ML/3_basic_regression.py
1 # coding=utf-8 2 import tensorflow as tf 3 from tensorflow import keras 4 from tensorflow.python.keras import layers 5 import matplotlib.pyplot as plt 6 import pandas as pd 7 import seaborn as sns 8 import pathlib 9 import os 10 11 os.environ[‘TF_CPP_MIN_LOG_LEVEL‘] = ‘2‘ 12 print("# TensorFlow version: {} - tf.keras version: {}".format(tf.VERSION, tf.keras.__version__)) # 查看版本 13 14 # ### 数据部分 15 # 获取数据(Get the data) 16 ds_path = str(pathlib.Path.cwd()) + "\\datasets\\auto-mpg\\" 17 ds_file = keras.utils.get_file(fname=ds_path + "auto-mpg.data", origin="file:///" + ds_path) # 获得文件路径 18 column_names = [‘MPG‘, ‘Cylinders‘, ‘Displacement‘, ‘Horsepower‘, ‘Weight‘, ‘Acceleration‘, ‘Model Year‘, ‘Origin‘] 19 raw_dataset = pd.read_csv(filepath_or_buffer=ds_file, # 数据的路径 20 names=column_names, # 用于结果的列名列表 21 na_values="?", # 用于替换NA/NaN的值 22 comment=‘\t‘, # 标识着多余的行不被解析(如果该字符出现在行首,这一行将被全部忽略) 23 sep=" ", # 分隔符 24 skipinitialspace=True # 忽略分隔符后的空白(默认为False,即不忽略) 25 ) # 通过pandas导入数据 26 data_set = raw_dataset.copy() 27 print("# Data set tail:\n{}".format(data_set.tail())) # 显示尾部数据 28 29 # 清洗数据(Clean the data) 30 print("# Summary of NaN:\n{}".format(data_set.isna().sum())) # 统计NaN值个数(NaN代表缺失值,可用isna()和notna()来检测) 31 data_set = data_set.dropna() # 方法dropna()对缺失的数据进行过滤 32 origin = data_set.pop(‘Origin‘) # Origin"列是分类不是数值,转换为独热编码(one-hot encoding) 33 data_set[‘USA‘] = (origin == 1) * 1.0 34 data_set[‘Europe‘] = (origin == 2) * 1.0 35 data_set[‘Japan‘] = (origin == 3) * 1.0 36 data_set.tail() 37 print("# Data set tail:\n{}".format(data_set.tail())) # 显示尾部数据 38 39 # 划分训练集和测试集(Split the data into train and test) 40 train_dataset = data_set.sample(frac=0.8, random_state=0) 41 test_dataset = data_set.drop(train_dataset.index) # 测试作为模型的最终评估 42 43 # 检查数据(Inspect the data) 44 sns.pairplot(train_dataset[["MPG", "Cylinders", "Displacement", "Weight"]], diag_kind="kde") 45 plt.figure(num=1) 46 plt.savefig("./outputs/sample-3-figure-1.png", dpi=200, format=‘png‘) 47 plt.show() 48 plt.close() 49 train_stats = train_dataset.describe() # 总体统计数据 50 train_stats.pop("MPG") 51 train_stats = train_stats.transpose() # 通过transpose()获得矩阵的转置 52 print("# Train statistics:\n{}".format(train_stats)) 53 54 # 分离标签(Split features from labels) 55 train_labels = train_dataset.pop(‘MPG‘) # 将要预测的值 56 test_labels = test_dataset.pop(‘MPG‘) 57 58 59 # 规范化数据(Normalize the data) 60 def norm(x): 61 return (x - train_stats[‘mean‘]) / train_stats[‘std‘] 62 63 64 normed_train_data = norm(train_dataset) 65 normed_test_data = norm(test_dataset) 66 67 68 # ### 模型部分 69 # 构建模型(Build the model) 70 def build_model(): # 模型被包装在此函数中 71 model = keras.Sequential([ # 使用Sequential模型 72 layers.Dense(64, activation=tf.nn.relu, input_shape=[len(train_dataset.keys())]), # 包含64个单元的全连接隐藏层 73 layers.Dense(64, activation=tf.nn.relu), # 包含64个单元的全连接隐藏层 74 layers.Dense(1)] # 一个输出层,返回单个连续的值 75 ) 76 optimizer = tf.keras.optimizers.RMSprop(0.001) 77 model.compile(loss=‘mean_squared_error‘, # 损失函数 78 optimizer=optimizer, # 优化器 79 metrics=[‘mean_absolute_error‘, ‘mean_squared_error‘] # 在训练和测试期间的模型评估标准 80 ) 81 return model 82 83 84 # 检查模型(Inspect the model) 85 mod = build_model() # 创建模型 86 mod.summary() # 打印出关于模型的简单描述 87 example_batch = normed_train_data[:10] # 从训练集中截取10个作为示例批次 88 example_result = mod.predict(example_batch) # 使用predict()方法进行预测 89 print("# Example result:\n{}".format(example_result)) 90 91 92 # 训练模型(Train the model) 93 class PrintDot(keras.callbacks.Callback): 94 def on_epoch_end(self, epoch, logs): 95 if epoch % 100 == 0: 96 print(‘‘) 97 print(‘.‘, end=‘‘) # 每完成一次训练打印一个“.”符号 98 99 100 EPOCHS = 1000 # 训练次数 101 102 history = mod.fit(normed_train_data, 103 train_labels, 104 epochs=EPOCHS, # 训练周期(训练模型迭代轮次) 105 validation_split=0.2, # 用来指定训练集的一定比例数据作为验证集(0~1之间的浮点数) 106 verbose=0, # 日志显示模式:0为安静模式, 1为进度条(默认), 2为每轮一行 107 callbacks=[PrintDot()] # 回调函数(在训练过程中的适当时机被调用) 108 ) # 返回一个history对象,包含一个字典,其中包括训练期间发生的情况(training and validation accuracy) 109 110 111 def plot_history(h, n=1): 112 """可视化模型训练过程""" 113 hist = pd.DataFrame(h.history) 114 hist[‘epoch‘] = h.epoch 115 print("\n# History tail:\n{}".format(hist.tail())) 116 117 plt.figure(num=n, figsize=(6, 8)) 118 119 plt.subplot(2, 1, 1) 120 plt.xlabel(‘Epoch‘) 121 plt.ylabel(‘Mean Abs Error [MPG]‘) 122 plt.plot(hist[‘epoch‘], hist[‘mean_absolute_error‘], label=‘Train Error‘) 123 plt.plot(hist[‘epoch‘], hist[‘val_mean_absolute_error‘], label=‘Val Error‘) 124 plt.ylim([0, 5]) 125 126 plt.subplot(2, 1, 2) 127 plt.xlabel(‘Epoch‘) 128 plt.ylabel(‘Mean Square Error [$MPG^2$]‘) 129 plt.plot(hist[‘epoch‘], hist[‘mean_squared_error‘], label=‘Train Error‘) 130 plt.plot(hist[‘epoch‘], hist[‘val_mean_squared_error‘], label=‘Val Error‘) 131 plt.ylim([0, 20]) 132 133 filename = "./outputs/sample-3-figure-" + str(n) + ".png" 134 plt.savefig(filename, dpi=200, format=‘png‘) 135 plt.show() 136 plt.close() 137 138 139 plot_history(history, 2) # 可视化 140 141 # 调试 142 model2 = build_model() 143 early_stop = keras.callbacks.EarlyStopping(monitor=‘val_loss‘, 144 patience=10) # 指定提前停止训练的callbacks 145 history2 = model2.fit(normed_train_data, 146 train_labels, 147 epochs=EPOCHS, 148 validation_split=0.2, 149 verbose=0, 150 callbacks=[early_stop, PrintDot()]) # 当没有改进时自动停止训练(通过EarlyStopping) 151 plot_history(history2, 3) 152 loss, mae, mse = model2.evaluate(normed_test_data, test_labels, verbose=0) 153 print("# Testing set Mean Abs Error: {:5.2f} MPG".format(mae)) # 测试集上的MAE值 154 155 # 做出预测(Make predictions) 156 test_predictions = model2.predict(normed_test_data).flatten() # 使用测试集中数据进行预测 157 plt.figure(num=4, figsize=(6, 8)) 158 plt.scatter(test_labels, test_predictions) 159 plt.xlabel(‘True Values [MPG]‘) 160 plt.ylabel(‘Predictions [MPG]‘) 161 plt.axis(‘equal‘) 162 plt.axis(‘square‘) 163 plt.xlim([0, plt.xlim()[1]]) 164 plt.ylim([0, plt.ylim()[1]]) 165 plt.plot([-100, 100], [-100, 100]) 166 plt.savefig("./outputs/sample-3-figure-4.png", dpi=200, format=‘png‘) 167 plt.show() 168 plt.close() 169 170 error = test_predictions - test_labels 171 plt.figure(num=5, figsize=(6, 8)) 172 plt.hist(error, bins=25) # 通过直方图来展示错误的分布情况 173 plt.xlabel("Prediction Error [MPG]") 174 plt.ylabel("Count") 175 plt.savefig("./outputs/sample-3-figure-5.png", dpi=200, format=‘png‘) 176 plt.show() 177 plt.close()
xxx
问题描述
在Anaconda3创建的运行环境中,执行“import tensorflow.keras import layers”失败,提示“Unresolved reference”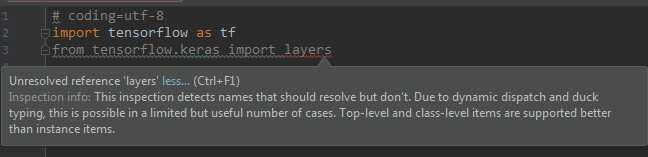
处理方法
改写为“from tensorflow.python.keras import layers”
导入包时,需要根据实际的具体位置进行导入。
确认TensorFlow中Keras的实际位置:“D:\DownLoadFiles\anaconda3\envs\mlcc\Lib\site-packages\tensorflow\python\keras\”。
实际上多了一层目录“python”,所以正确的导入方式为“from tensorflow.python.keras import layers”。
参考信息
https://stackoverflow.com/questions/47262955/how-to-import-keras-from-tf-keras-in-tensorflow
问题描述
执行keras.utils.get_file("auto-mpg.data", "https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")报错:
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data
Traceback (most recent call last):
......
Exception: URL fetch failure on https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data: None -- [WinError 10060] A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond
处理方法
“网络”的原因,导致无法下载。手工下载,然后放置在当前目录,从当前目录地址导入数据文件。
标签:示例 example href period ESS 处理 blank dpi training
原文地址:https://www.cnblogs.com/anliven/p/10777595.html