标签:line false 自己 运行 通信 memory 就会 定时 错误
减少上下文切换的方法有无锁并发编程、CAS算法、使用最少线程和使用协程。 无锁并发编程。多线程竞争锁时,会引起上下文切换,所以多线程处理数据时,可以用一 些办法来避免使用锁,如将数据的ID按照Hash算法取模分段,不同的线程处理不同段的数据。 协程:在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换。 现在我们介绍避免死锁的几个常见方法。 ·避免一个线程同时获取多个锁。 ·避免一个线程在锁内同时占用多个资源,尽量保证每个锁只占用一个资源。 ·尝试使用定时锁,使用lock.tryLock(timeout)来替代使用内部锁机制。 ·对于数据库锁,加锁和解锁必须在一个数据库连接里,否则会出现解锁失败的情况。 硬件资源限 制有带宽的上传/下载速度、硬盘读写速度和CPU的处理速度。软件资源限制有数据库的连接 数和socket连接数等。 Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节 码,最终需要转化为汇编指令在CPU上执行,Java中所使用的并发机制依赖于JVM的实现和 CPU的指令。 volatile是轻量级的 synchronized,它在多处理器开发中保证了共享变量的“可见性”。可见性的意思是当一个线程 修改一个共享变量时,另外一个线程能读到这个修改的值。如果volatile变量修饰符使用恰当 的话,它比synchronized的使用和执行成本更低,因为它不会引起线程上下文的切换和调度。
x = 10; //语句1
y = x; //语句2
x++; //语句3
x = x + 1; //语句4
咋一看,有些朋友可能会说上面的4个语句中的操作都是原子性操作。其实只有语句1是原子性操作,其他三个语句都不是原子性操作。
语句1是直接将数值10赋值给x,也就是说线程执行这个语句的会直接将数值10写入到工作内存中。
语句2实际上包含2个操作,它先要去读取x的值,再将x的值写入工作内存,虽然读取x的值以及 将x的值写入工作内存 这2个操作都是原子性操作,但是合起来就不是原子性操作了。
同样的,x++和 x = x+1包括3个操作:读取x的值,进行加1操作,写入新的值。
所以上面4个语句只有语句1的操作具备原子性。
也就是说,只有简单的读取、赋值(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。
不过这里有一点需要注意:在32位平台下,对64位数据的读取和赋值是需要通过两个操作来完成的,不能保证其原子性。但是好像在最新的JDK中,JVM已经保证对64位数据的读取和赋值也是原子性操作了。
从上面可以看出,Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
2. 线程独有的工作内存和进程内存(主内存)之间通过8中原子操作来实现,如下图所示:
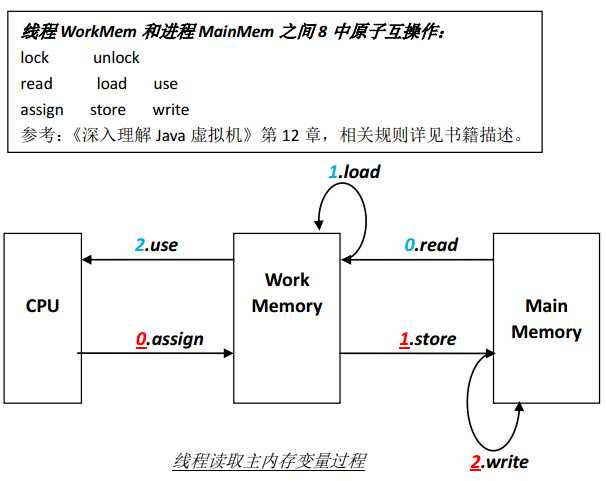
原子操作的规则(部分):
1) read,load必须连续执行,但是不保证原子性。
2) store,write必须连续执行,但是不保证原子性。
3) 不能丢失变量最后一次assign操作的副本,即遍历最后一次assign的副本必须要回写到MainMemory中。
其它规则详见《深入理解Java虚拟机》第12章 Java内存模型与线程
read(读取) :它把一个变量的值从主内存中传递到工作内存,
load(载入) :赋值给工作内存
store(存储) :把工作内存中的值传递到主内存中来
write(写入) :赋值给主内存
use(使用) :使用工作变量值
assign(赋值) :修改工作变量
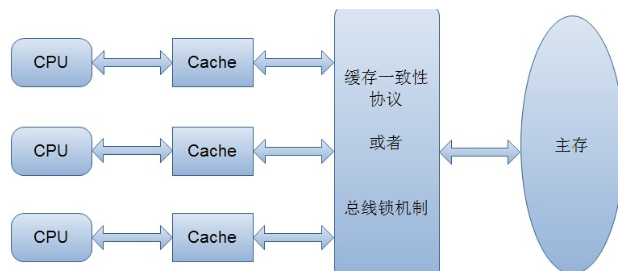
大家都知道,计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
也就是,当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如下面的这段代码:
i = i + 1;
当线程执行这个语句时,会先从主存当中读取i的值,然后复制一份到高速缓存当中,然后CPU执行指令对i进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。CPU只跟高速缓存交互。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。本文我们以多核CPU为例。
比如同时有2个线程执行这段代码,假如初始时i的值为0,那么我们希望两个线程执行完之后i的值变为2。但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。
最终结果i的值是1,而不是2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
也就是说,如果一个变量在多个CPU中都存在缓存(一般在多线程编程时才会出现),那么就可能存在缓存不一致的问题。
为了解决缓存不一致性问题,通常来说有以下2种解决方法:
1)通过在总线加LOCK#锁的方式
2)通过缓存一致性协议
这2种方式都是硬件层面上提供的方式。
在早期的CPU当中,是通过在总线上加LOCK#锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。比如上面例子中 如果一个线程在执行 i = i +1,如果在执行这段代码的过程中,在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从变量i所在的内存读取变量,然后进行相应的操作。这样就解决了缓存不一致的问题。
但是上面的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
所以就出现了缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。(这是没有涉及到java的内存的模型)
i = 9;
假若一个线程执行到这个语句时,我暂且假设为一个32位的变量赋值包括两个过程:为低16位赋值,为高16位赋值。
那么就可能发生一种情况:当将低16位数值写入之后,突然被中断,而此时又有一个线程去读取i的值,那么读取到的就是错误的数据。这就是原子性。
//线程1执行的代码 //线程2执行的代码
int i = 0; j = i;
i = 10;
假若执行线程1的是CPU1,执行线程2的是CPU2。由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到CPU1的高速缓存中,然后赋值为10,那么在CPU1的高速缓存当中i的值变为10了,却没有立即写入到主存当中。
此时线程2执行 j = i,它会先去主存读取i的值并加载到CPU2的缓存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10.
这就是可见性问题,线程1对变量i修改了之后,线程2没有立即看到线程1修改的值。
int i = 0;
boolean flag = false;
i = 1; //语句1
flag = true; //语句2
标签:line false 自己 运行 通信 memory 就会 定时 错误
原文地址:https://www.cnblogs.com/yaowen/p/10778314.html