标签:提交 lin 计算 executor 错误 一个个 需要 dag style
在spark的资源调度中
1、集群启动worker向master汇报资源情况
2、Client向集群提交app,向master注册一个driver(需要多少core、memery),启动一个driver
3、Driver将当前app注册给master,(当前app需要多少资源),并请求启动对应的Executor
4、driver分发任务给Executor的Thread Pool。
根据Spark源码可以知道:
1、一个worker默认为一个Application启动一个Executor
2、启动的Executor默认占用这个worker的全部资源
3、如果要在一个worker上启动多个Executor,(前提:在内存充足的情况下)需要设置--executor-cores num 参数
宽依赖、窄依赖
窄依赖:父RDD与子RDD,partition之间是一对一的关系,或者多对一的关系。
宽依赖:父RDD与子RDD,partition之间是一对多,多对多的关系。
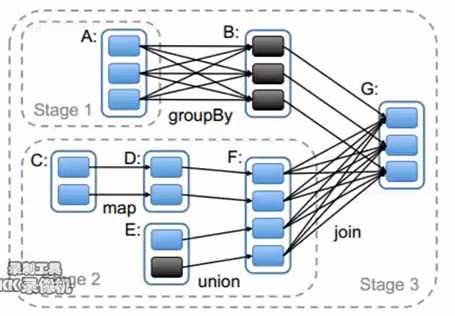
注意:
1、Stage的划分是根据宽窄依赖进行的,Satge与Satge之间是根据宽依赖划分的,每个Satge内部是窄依赖的。
2、窄依赖内部父RDD与子RDD之间的Partition是一对一的关系。
3、一个Satge内部是由多个RDD组成,在运行的过程中,会形成一个个并行的task,每个task形成一个pipeline。
4、在pipeline的运行过程中,数据不会落地,只有在右侧的join阶段的shuffle write才会数据落地。
Spark任务调度
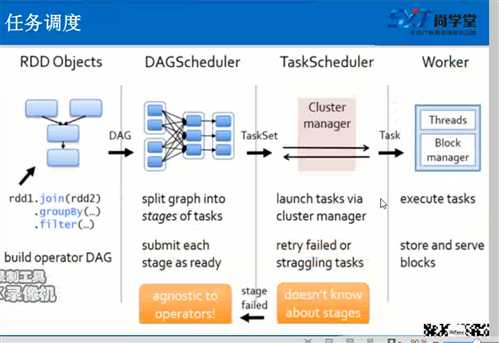
Spark的任务调度过程
RDD之间有依赖关系,所以可以根据依赖关系倒推回去,寻找到RDD的所有依赖关系,形成DAG(有向无环图)
由RDD Object将DAG传递给DAGScheduler
DAGScheduler会根据宽依赖将有向无环图划分为一个个的Satge
DAGScheduler将taskSet传递给TaskScheduler(实际上taskScheduler和Stage是相同的,只是叫法不同)
TaskScheduler会将TaskSet划分为一个个的task,传递给worker
worker会将task放入反序列化放入自己的线程池中,进行执行。
注意:
默认情况下TaskScheduler会对计算失败的task重试3次
默认情况下DAGScheduler会对计算失败的Stage重试4次
一共重试3*4=12次
未避免在对数据库操作时,操作一半失败,重试导致数据重复插入问题,可以采取两个办法
(1)设置主键
(2)关闭推测执行(默认是关闭的)
特殊情况:
如果task在执行的过程中报错shuffle file not find错误信息,此时TaskScheduler是不负责重试的,直接抛出对应的Satge运行失败,由DAGScheduler负责重试,如果DAGScheduler4次重试失败,则直接显示Job运行失败。
标签:提交 lin 计算 executor 错误 一个个 需要 dag style
原文地址:https://www.cnblogs.com/learn-bigdata/p/10793669.html