标签:和我 标准 实现 表示 程序运行时间 http 单线程 roo 而且
买新电脑的时候,我们会说:"原来的电脑性能跟不上了"
写程序的时候,我们会说:"这个程序西能需要优化一下"
在计算机组成原理乃至体系结构中"性能"都是最重要的一个主题。我在前面说过学习和研究计算机组成原理,就是在理解计算机是怎么运作的,
以及为什么要这么运作。"为什么"?所要解决的事情,很多时候就是提升"性能"
计算机的性能,其实和我们干体力劳动很像,好比是我们要搬东西,对于计算机的性能,我们需要有个标准来衡量这个标准中主要有两个指标
响应时间:第一个是响应时间或者叫执行事假,要想提升响应时间这个性能指标,你可以理解为计算机"跑的更快"
响应时间指的就是,我们执行一个程序,到底需要花多少时间,花的时间越少,自然性能就越好
吞吐率
吞吐率:第二个是吞吐率或者带宽,想要提升这个指标,你可以理解为让计算机"搬得更多"
服务器使用的网络带宽,通常就是一个吞吐率性能指标,
吞吐率是指我们在一定的时间范围内,到底能处理多少事情,这里的"时间",在计算机里就是处理数据或者执行的程序指令
1、缩短程序的相应时间能提高吞吐率吗?
和搬东西来比,如果我们的响应时间短,跑得快,我们可以来回多跑几趟多搬几趟,所以说,缩短程序的响应时间,一般来说都会提升吞吐率
2、除了缩短响应时间,我们还有别的方法吗?
当然有,比如说,我们还可以多找几人一起来搬,这就是类似现代的服务器都是8核、16核的人多力量大,同时处理数据,在单位时间内就可以处理更多的数据,吞吐率自然就上去了
各大CPU和服务器厂商组织了一个叫SPEC的第三方机构,专门用来指定各种"跑分"的规则
提供的CPU基准测试程序,就好像CPU届的"高考",通过数十个不同的计算机程序,对于的性能给出一个最终评分,
虽然时间是一个很自然的用来衡量性能的指标、但是用时间来衡量时,有两个问题
第一就是时间不准 如果你随便写的一个程序,来统计程序运行的时间,每一次统计结果不会完全一样。有可能这一次花了45ms,下一次变成了53ms
1、但是计算机可能同时运行着好多程序,CPU实际上不停地在各个程序之间进行切换。在这些走掉的时间里,很可能CPU切换去运行别的程序了,
2、而且,游戏程序在运行的时候,可能要从网络、硬盘去读取数据,要等网络和应哦按把数据读出来,给到内存和CPU
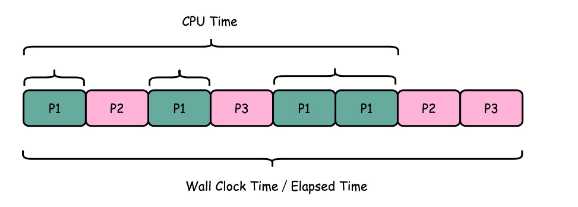
所以说:要想准确统计某个程序运行时间,进而去比较两个程序的实际性能,我们得把这些时间给刨删掉
[root@nfs ~]# time seq 1000000 | wc -l 1000000 real 0m0.101s #Wall Clock Time 也就是运行程序整个过程中流失的时间 user 0m0.031s #CPU在运行你的程序,在用户态运行指令的时间, sys 0m0.016s #CPU在运行你的程序,在操作系统内核里运行指令的时间
而程序实际花费的CPU执行时间,就是User Time加上sys Time
在我给的这个例子里,你可以看到,实际上程序用了0.101s,但是CPU Time只有0.031+0.016=0.047s。运行程序的时间里,
只有不到一半是是花在这个程序上的
即使在统一台计算机上,CPU可能满载运行也可能降频运行,降频运行的时间自然花的时间会多一些
除了CPU之外,时间这个西能指标还会受到主板、内存这些其他相关硬件的影响,所以我们需要对"时间"这个我们可以感知的指标进行拆解
把程序的CPU执行时间编程CPU时钟周期数C和时钟周期时间的乘积
程序的CPU执行时间=CPU时钟周期数*时间周期时间
比如我手头这台电脑就是Intel Core-i7-7700HQ 2.8GHz,这里2.8GHz就是电脑的主频,可以先粗浅地认为cpu1秒时间内,可以执行的简单质量的数量是2.8G条
准确一点描述2.8GHz就代表CPU的一个“钟表”能识别出来的最小的时间间隔,就像我们挂在墙上的挂钟的最小能够识别单位就是秒
在这个的CPU上,这个时钟周期时间,就是1/2.8G。我们的 CPU,是按照这个“时钟”提示的时间来进行自己的操作。主频越高,意味着这个表走得越快,
就相当于把买回来的CPU内部的钟给调快了,于是CPU的计算跟着这个时钟的节奏,也就自然快了,
当然这个快不是没有代价的,CPU跑得越快,散热的压力也就越大,就和人一样,超过生理极限,CPU就会崩溃了
如果能够减少程序需要的CPU时钟周期数,一样能够提升程序性能
每条指令的平均时钟周期数,不同指令需要的Cycles 是不同的,加法和乘法都对应着一条 CPU 指令但是乘法需要的 Cycles 就比加法要多,自然也就慢。
在这样拆分了之后,我们的程序的 CPU 执行时间就可以变成这样三个部分的乘积
程序的 CPU 执行时间 = 指令数×CPI×Clock Cycle Time
就是计算机主频,这个取决于计算机硬件,我们所熟知的摩尔定律就一直在不停地提高我们计算机的主频
比如说,我最早使用的80386主频只有33MHZ,现在手头的笔记本就有2.8GHz,在主频层面,就提升了将近100倍
每条指令的平均时钟周期数CPI,就是一条指令到底需要多少CPU Cycle,在后面讲解CPU结构的时候,我们会看到,现代CPU
通过流水线技术,让一条指令需要的CPU Cycle尽可能地少,因此对于CPI的优化,也是计算机组成和体系结构中重要的一环
指令数,代表执行我们的程序到底需要多少条指令,用那些指令。这个很多时候就把挑战交给了编译器,同样的代码,编译
成计算机指令时候,就有格子能够不同的表示方式
我们可以把自己想像成一个CPU,坐在那里写程序。计算机主频就好像是你打字的速度,打字越快,你自然可以多写一点程序;
CPI相当于你在写程序的时候,熟悉各种快捷键,越是打同样的内容,需要敲击键盘的次数就越少,
指令相当于你的程序设计的够合理,同样的程序要写的代码行数就少,
如果三者皆能实现,你自然可以很快地写出一个优秀的程序,你的“性能”从外面来看就是好的
每次有新手机发布的时候,总会有一些对于手机的跑分结果的议论。乃至于有“作弊”跑分或者“针对跑分优化”的说法。我们能针对“
“跑分”作弊么?怎么做到呢?“作弊”出来的分数对于手机性能还有参考意义?
可以通过超频作弊,也就是老师说的调高时钟,这种做法事不顾功耗专门针对跑分来全力冲刺,不能作为日常使用的标准,不过依然能反应出机器性能的极限,如果用户可以选择进入超频状态,一些发烧友有特殊需求时是能用上的。
不太清楚跑分测试的机制,似乎是送样机给相关机构,是不是还能直接给出特殊机型来作弊呢?这种就完全是欺骗了。
2019-04-29
作者回复: ??只要有考试,总会出现有作弊的情况的。不过现在已经很罕见了,大家对于跑分也没有那么关注了
[root@nfs ~]# time seq 1000000 | wc -l 1000000 real 0m0.058s #Wall Clock Time 也就是运行程序整个过程中流失的时间 user 0m0.047s #CPU在运行你的程序,在用户态运行指令的时间, sys 0m0.044s #CPU在运行你的程序,在操作系统内核里运行指令的时间
我知道原因了,这个的确是因为“并行原因”的运行的。虽然seq和wc这两个命令都是单线程运行的,但是这两个命令在多核cpu运行的情况下,会分别分配到两个不同的cpu,
于是user和sys的时间都是两个cpu上运行的时间之和,就可能超过real的时间。你可以这样来快速验证运行
time seq 100000000 | wc -l &
让这个命令多跑一会儿,并且在后台运行。
然后利用 top 命令看不同进程的cpu占用情况,你会在top的前几行里看到seq和wc的cpu占用都接近100,实际是各被分配到了一个不同的cpu执行。
我写文稿测试的时候开了一个1u的最小的虚拟机,只有一个cpu所以不会遇到这个问题。
深入浅出计算机组成原理:通过你的CPU主频,我们来谈谈“性能”究竟是什么?(第3讲)
标签:和我 标准 实现 表示 程序运行时间 http 单线程 roo 而且
原文地址:https://www.cnblogs.com/luoahong/p/10798372.html