标签:dimen 数据 type lse cpu 视图 变量 ini view
原文:DirectX11--深入理解与使用缓冲区资源在Direct3D 11中,缓冲区属于其中一种资源类型,它在内存上的布局是一维线性的。根据HLSL支持的类型以及C++的使用情况,缓冲区可以分为下面这些类型:
因此这一章主要讲述上面这些资源的创建和使用方法
DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
顾名思义,顶点缓冲区存放的是一连串的顶点数据,尽管缓冲区的数据实际上还是一堆二进制流,但在传递给输入装配阶段的时候,就会根据顶点输入布局将其装配成HLSL的顶点结构体数据。顶点缓冲区的数据可以用自定义的顶点结构体数组来初始化。顶点可以包含的成员有:顶点坐标(必须有),顶点颜色,顶点法向量,纹理坐标,顶点切线向量等等。每个顶点的成员必须匹配合适的DXGI数据格式。
当然,纯粹的顶点数组只是针对单个物体而言的。如果需要绘制大量相同的物体,需要同时用到多个顶点缓冲区。这允许你将顶点数据分开成多个顶点缓冲区来存放。
这里还提供了顶点缓冲区的另一种形式:实例缓冲区。我们可以提供一到多个的顶点缓冲区,然后再提供一个实例缓冲区。其中实例缓冲区存放的可以是物体的世界矩阵、世界矩阵的逆转置、材质等。这样做可以减少大量重复数据的产生,以及减少大量的CPU绘制调用。
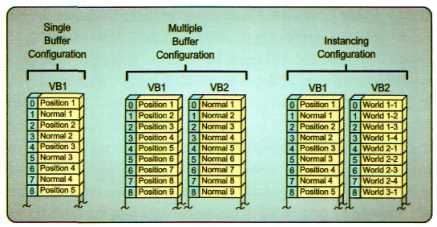
顶点缓冲区的创建需要区分下面两种情况:
如果顶点缓冲区在创建的时候提供了D3D11_SUBRESOURCE_DATA来完成初始化,并且之后都不需要更新,则可以使用D3D11_USAGE_IMMUTABLE。
如果顶点缓冲区需要频繁更新,则可以使用D3D11_USAGE_DYNAMIC,并允许CPU写入(D3D11_CPU_ACCESS_WRITE)。
如果顶点缓冲区需要绑定到流输出,则说明顶点缓冲区需要允许GPU写入,可以使用D3D11_USAGE_DEFAULT,并且需要提供绑定标签D3D11_BIND_STREAM_OUTPUT。
下图说明了顶点缓冲区可以绑定的位置:
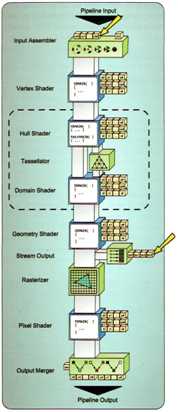
顶点缓冲区不需要创建资源视图,它可以直接绑定到输入装配阶段或流输出阶段。
创建顶点缓冲区和一般的创建缓冲区函数如下:
// ------------------------------
// CreateBuffer函数
// ------------------------------
// 创建缓冲区
// [In]d3dDevice D3D设备
// [In]data 初始化结构化数据
// [In]byteWidth 缓冲区字节数
// [Out]structuredBuffer 输出的结构化缓冲区
// [In]usage 资源用途
// [In]bindFlags 资源绑定标签
// [In]cpuAccessFlags 资源CPU访问权限标签
// [In]structuredByteStride 每个结构体的字节数
// [In]miscFlags 资源杂项标签
HRESULT CreateBuffer(
ID3D11Device * d3dDevice,
void * data,
UINT byteWidth,
ID3D11Buffer ** buffer,
D3D11_USAGE usage,
UINT bindFlags,
UINT cpuAccessFlags,
UINT structureByteStride,
UINT miscFlags)
{
D3D11_BUFFER_DESC bufferDesc;
bufferDesc.Usage = usage;
bufferDesc.ByteWidth = byteWidth;
bufferDesc.BindFlags = bindFlags;
bufferDesc.CPUAccessFlags = cpuAccessFlags;
bufferDesc.StructureByteStride = structureByteStride;
bufferDesc.MiscFlags = miscFlags;
D3D11_SUBRESOURCE_DATA initData;
ZeroMemory(&initData, sizeof(initData));
initData.pSysMem = data;
return d3dDevice->CreateBuffer(&bufferDesc, &initData, buffer);
}
// ------------------------------
// CreateVertexBuffer函数
// ------------------------------
// [In]d3dDevice D3D设备
// [In]data 初始化数据
// [In]byteWidth 缓冲区字节数
// [Out]vertexBuffer 输出的顶点缓冲区
// [InOpt]dynamic 是否需要CPU经常更新
// [InOpt]streamOutput 是否还用于流输出阶段(不能与dynamic同时设为true)
HRESULT CreateVertexBuffer(
ID3D11Device * d3dDevice,
void * data,
UINT byteWidth,
ID3D11Buffer ** vertexBuffer,
bool dynamic,
bool streamOutput)
{
UINT bindFlags = D3D11_BIND_VERTEX_BUFFER;
D3D11_USAGE usage;
UINT cpuAccessFlags = 0;
if (dynamic && streamOutput)
{
return E_INVALIDARG;
}
else if (!dynamic && !streamOutput)
{
usage = D3D11_USAGE_IMMUTABLE;
}
else if (dynamic)
{
usage = D3D11_USAGE_DYNAMIC;
cpuAccessFlags |= D3D11_CPU_ACCESS_WRITE;
}
else
{
bindFlags |= D3D11_BIND_STREAM_OUTPUT;
usage = D3D11_USAGE_DEFAULT;
}
return CreateBuffer(d3dDevice, data, byteWidth, vertexBuffer,
usage, bindFlags, cpuAccessFlags, 0, 0);
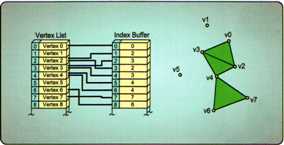
}索引缓冲区通常需要与顶点缓冲区结合使用,它的作用就是以索引的形式来引用顶点缓冲区中的某一顶点,并按索引缓冲区的顺序和图元类型来组装图元。它可以有效地减少顶点缓冲区中重复的顶点数据,从而减小网格模型占用的数据大小。使用相同的索引值就可以多次引用同一个顶点。
索引缓冲区的使用不需要创建资源视图,它仅用于输入装配阶段,并且在装配的时候你需要指定每个索引所占的字节数:
| DXGI_FORMAT | 字节数 | 索引范围 |
|---|---|---|
| DXGI_FORMAT_R8_UINT | 1 | 0-255 |
| DXGI_FORMAT_R16_UINT | 2 | 0-65535 |
| DXGI_FORMAT_R32_UINT | 4 | 0-2147483647 |
将索引缓冲区绑定到输入装配阶段后,你就可以用带Indexed的Draw方法,指定起始索引偏移值和索引数目来进行绘制。
索引缓冲区的创建只考虑数据是否需要动态更新。
如果索引缓冲区在创建的时候提供了D3D11_SUBRESOURCE_DATA来完成初始化,并且之后都不需要更新,则可以使用D3D11_USAGE_IMMUTABLE
如果索引缓冲区需要频繁更新,则可以使用D3D11_USAGE_DYNAMIC,并允许CPU写入(D3D11_CPU_ACCESS_WRITE)。
// ------------------------------
// CreateIndexBuffer函数
// ------------------------------
// [In]d3dDevice D3D设备
// [In]data 初始化数据
// [In]byteWidth 缓冲区字节数
// [Out]indexBuffer 输出的索引缓冲区
// [InOpt]dynamic 是否需要CPU经常更新
HRESULT CreateIndexBuffer(
ID3D11Device * d3dDevice,
void * data,
UINT byteWidth,
ID3D11Buffer ** indexBuffer,
bool dynamic)
{
D3D11_USAGE usage;
UINT cpuAccessFlags = 0;
if (dynamic)
{
usage = D3D11_USAGE_DYNAMIC;
cpuAccessFlags |= D3D11_CPU_ACCESS_WRITE;
}
else
{
usage = D3D11_USAGE_IMMUTABLE;
}
return CreateBuffer(d3dDevice, data, byteWidth, indexBuffer,
usage, D3D11_BIND_INDEX_BUFFER, cpuAccessFlags, 0, 0);
}常量缓冲区是我们接触到的第一个可以给所有可编程着色器程序使用的缓冲区。由于着色器函数的形参没法从C++端传入,我们只能通过类似全局变量的方式来让着色器函数访问,这些参数被打包在一个常量缓冲区中。而C++可以通过创建对应的常量缓冲区来绑定到HLSL对应的cbuffer,以实现从C++到HLSL的数据的传递。C++的常量缓冲区是以字节流来对待;而HLSL的cbuffer内部可以像结构体那样包含各种类型的参数,而且还需要注意它的打包规则。
关于常量缓冲区,有太多值得需要注意的细节了:
cbuffer需要指定register(b#), #的范围为0到14packoffset修饰符可以指定起始向量和分量位置cbuffer的所有成员都被更新。为了减少不必要的更新,可以根据这些参数的更新频率划分出多个常量缓冲区以节省带宽资源*.hlsli文件同时被多个着色器文件引用,只是说明这些着色器使用相同的常量缓冲区布局,如果该缓冲区需要在多个着色器阶段使用,你还需要在C++同时将相同的常量缓冲区绑定到各个着色器阶段上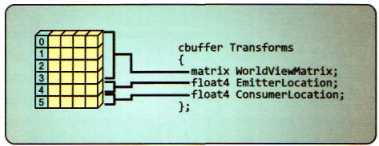
下面是一个HLSL常量缓冲区的例子(注释部分可省略,效果等价):
cbuffer CBChangesRarely : register(b2)
{
matrix gView /* : packoffset(c0) */;
float3 gSphereCenter /* : packoffset(c4.x) */;
float gSphereRadius /* : packoffset(c4.w) */;
float3 gEyePosW /* : packoffset(c5.x) */;
float gPad /* : packoffset(c5.w) */;
}常量缓冲区的创建需要区分下面两种情况:
如果常量缓冲区在创建的时候提供了D3D11_SUBRESOURCE_DATA来完成初始化,并且之后都不需要更新,则可以使用D3D11_USAGE_IMMUTABLE。
如果常量缓冲区需要频繁更新,则可以使用D3D11_USAGE_DYNAMIC,并允许CPU写入(D3D11_CPU_ACCESS_WRITE)。
如果常量缓冲区在较长的一段时间才需要更新一次,则可以考虑使用D3D11_USAGE_DEFAULT。
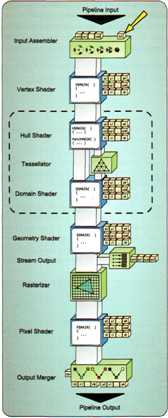
下图说明了常量缓冲区可以绑定的位置:
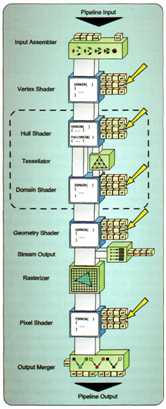
常量缓冲区的使用同样不需要创建资源视图。
// ------------------------------
// CreateConstantBuffer函数
// ------------------------------
// [In]d3dDevice D3D设备
// [In]data 初始化数据
// [In]byteWidth 缓冲区字节数,必须是16的倍数
// [Out]indexBuffer 输出的索引缓冲区
// [InOpt]cpuUpdates 是否允许CPU更新
// [InOpt]gpuUpdates 是否允许GPU更新
HRESULT CreateConstantBuffer(
ID3D11Device * d3dDevice,
void * data,
UINT byteWidth,
ID3D11Buffer ** constantBuffer,
bool cpuUpdates,
bool gpuUpdates)
{
D3D11_USAGE usage;
UINT cpuAccessFlags = 0;
if (cpuUpdates && gpuUpdates)
{
return E_INVALIDARG;
}
else if (!cpuUpdates && !gpuUpdates)
{
usage = D3D11_USAGE_IMMUTABLE;
}
else if (cpuUpdates)
{
usage = D3D11_USAGE_DYNAMIC;
cpuAccessFlags |= D3D11_CPU_ACCESS_WRITE;
}
else
{
usage = D3D11_USAGE_DEFAULT;
}
return CreateBuffer(d3dDevice, data, byteWidth, constantBuffer,
usage, D3D11_BIND_CONSTANT_BUFFER, cpuAccessFlags, 0, 0);
}这是一种创建和使用起来最简单的缓冲区,但实际使用频率远不如上面所讲的三种缓冲区。它的数据可以在HLSL被解释成基本HLSL类型的数组形式。
在HLSL中,如果是只读的缓冲区类型,则声明方式如下:
Buffer<float4> gBuffer : register(t0);需要留意的是,当前缓冲区和纹理需要共用纹理寄存器,即t#,因此要注意和纹理避开使用同一个寄存器槽。
如果是可读写的缓冲区类型,则声明方式如下:
RWBuffer<float4> gRWBuffer : register(u0);有类型的缓冲区具有下面的方法:
| 方法 | 作用 |
|---|---|
| void GetDimensions(out uint) | 获取资源各个维度下的大小 |
| T Load(in int) | 按一维索引读取缓冲区数据 |
| T Operator | Buffer仅允许读取,RWBuffer允许读写 |
有类型的缓冲区需要创建着色器资源视图以绑定到对应的着色器阶段。由于HLSL的语法知识定义了有限的类型和元素数目,但在DXGI_FORMAT中,有许多种成员都能够用于匹配一种HLSL类型。比如,HLSL的float4你可以使用DXGI_FORMAT_R32G32B32A32_FLOAT, DXGI_FORMAT_R16G16B16A16_FLOAT或DXGI_FORMAT_R8G8B8A8_UNORM。而HLSL的int2你可以使用DXGI_FORMAT_R32G32_SINT,DXGI_FORMAT_R16G16_SINT或DXGI_FORMAT_R8G8_SINT。
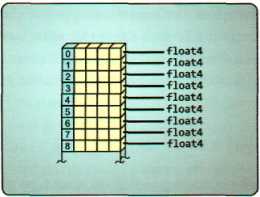
有类型的缓冲区通常需要绑定到着色器上作为资源使用,因此需要将bindFlags设为D3D11_BIND_SHADER_RESOURCE。
此外,有类型的缓冲区的创建需要区分下面两种情况:
如果缓冲区在创建的时候提供了D3D11_SUBRESOURCE_DATA来完成初始化,并且之后都不需要更新,则可以使用D3D11_USAGE_IMMUTABLE。
如果缓冲区需要频繁更新,则可以使用D3D11_USAGE_DYNAMIC,并允许CPU写入(D3D11_CPU_ACCESS_WRITE)。
如果缓冲区需要允许GPU写入,说明后面可能需要创建UAV绑定到RWBuffer<T>,为此还需要给bindFlags添加D3D11_BIND_UNORDERED_ACCESS。
如果缓冲区的数据需要读出到内存,则可以使用D3D11_USAGE_STAGING,并允许CPU读取(D3D11_CPU_ACCESS_READ)。
下图说明了有类型的(与结构化)缓冲区可以绑定的位置:
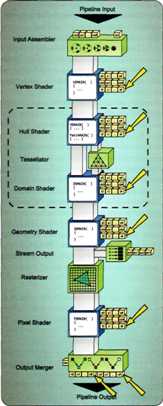
// ------------------------------
// CreateTypedBuffer函数
// ------------------------------
// [In]d3dDevice D3D设备
// [In]data 初始化数据
// [In]byteWidth 缓冲区字节数
// [Out]typedBuffer 输出的有类型的缓冲区
// [InOpt]cpuUpdates 是否允许CPU更新
// [InOpt]gpuUpdates 是否允许使用RWBuffer
HRESULT CreateTypedBuffer(
ID3D11Device * d3dDevice,
void * data,
UINT byteWidth,
ID3D11Buffer ** typedBuffer,
bool cpuUpdates,
bool gpuUpdates)
{
UINT bindFlags = D3D11_BIND_SHADER_RESOURCE;
D3D11_USAGE usage;
UINT cpuAccessFlags = 0;
if (cpuUpdates && gpuUpdates)
{
bindFlags = 0;
usage = D3D11_USAGE_STAGING;
cpuAccessFlags |= D3D11_CPU_ACCESS_READ;
}
else if (!cpuUpdates && !gpuUpdates)
{
usage = D3D11_USAGE_IMMUTABLE;
}
else if (cpuUpdates)
{
usage = D3D11_USAGE_DYNAMIC;
cpuAccessFlags |= D3D11_CPU_ACCESS_WRITE;
}
else
{
usage = D3D11_USAGE_DEFAULT;
bindFlags |= D3D11_BIND_UNORDERED_ACCESS;
}
return CreateBuffer(d3dDevice, data, byteWidth, typedBuffer,
usage, bindFlags, cpuAccessFlags, 0, 0);
}关于追加/消耗缓冲区,我们后面再讨论。
如果我们希望它作为Buffer<float4>使用,则需要创建着色器资源视图:
D3D11_SHADER_RESOURCE_VIEW_DESC srvDesc;
srvDesc.Format = DXGI_FORMAT_R32G32B32A32_FLOAT;
srvDesc.ViewDimension = D3D11_SRV_DIMENSION_BUFFER;
srvDesc.Buffer.FirstElement = 0; // 起始元素的索引
srvDesc.Buffer.NumElements = numElements; // 元素数目
HR(m_pd3dDevice->CreateShaderResourceView(m_pBuffer.Get(), &srvDesc, m_pBufferSRV.GetAddressOf()));而如果我们希望它作为RWBuffer<float4>使用,则需要创建无序访问视图:
D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc;
uavDesc.Format = DXGI_FORMAT_R32G32B32A32_FLOAT;
uavDesc.ViewDimension = D3D11_UAV_DIMENSION_BUFFER;
uavDesc.Buffer.FirstElement = 0; // 起始元素的索引
uavDesc.Buffer.Flags = 0;
uavDesc.Buffer.NumElements = numElements; // 元素数目
m_pd3dDevice->CreateUnorderedAccessView(m_pBuffer.Get(), &uavDesc, m_pBufferUAV.GetAddressOf());由于这些缓冲区仅支持GPU读取,我们需要另外新建一个缓冲区以允许它CPU读取和GPU写入(STAGING),然后将保存结果的缓冲区拷贝到该缓冲区,再映射出内存即可:
HR(CreateTypedBuffer(md3dDevice.Get(), nullptr, sizeof data,
mBufferOutputCopy.GetAddressOf(), true, true));
md3dImmediateContext->CopyResource(mVertexOutputCopy.Get(), mVertexOutput.Get());
D3D11_MAPPED_SUBRESOURCE mappedData;
HR(md3dImmediateContext->Map(mVertexOutputCopy.Get(), 0, D3D11_MAP_READ, 0, &mappedData));
memcpy_s(data, sizeof data, mappedData.pData, sizeof data);
md3dImmediateContext->Unmap(mVertexOutputCopy.Get(), 0);结构化缓冲区可以说是缓冲区的复合形式,它允许模板类型T是用户自定义的类型,即缓冲区存放的内容可以被解释为结构体数组。
现在HLSL有如下结构体:
struct Data
{
float3 v1;
float2 v2;
};如果是只读的结构化缓冲区,则声明方式如下:
StructuredBuffer<Data> gStructuredBuffer : register(t0);如果是可读写的结构化缓冲区类型,则声明方式如下:
RWStructuredBuffer<Data> gRWStructuredBuffer : register(u0);结构化缓冲区也具有下面的方法:
| 方法 | 作用 |
|---|---|
| void GetDimensions(out uint) | 获取资源各个维度下的大小 |
| T Load(in int) | 按一维索引读取结构化缓冲区数据 |
| T Operator | StructuredBuffer仅允许读取,RWStructuredBuffer允许读写 |
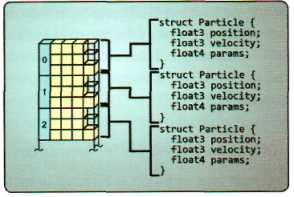
结构化缓冲区的创建和有类型的缓冲区创建比较相似,区别在于:
MiscFlags指定D3D11_RESOURCE_MISC_BUFFER_STRUCTUREDstructureByteStride说明结构体的大小// ------------------------------
// CreateStructuredBuffer函数
// ------------------------------
// 如果需要创建Append/Consume Buffer,需指定cpuUpdates为false, gpuUpdates为true
// [In]d3dDevice D3D设备
// [In]data 初始化数据
// [In]byteWidth 缓冲区字节数
// [In]structuredByteStride 每个结构体的字节数
// [Out]structuredBuffer 输出的结构化缓冲区
// [InOpt]cpuUpdates 是否允许CPU更新
// [InOpt]gpuUpdates 是否允许使用RWStructuredBuffer
HRESULT CreateStructuredBuffer(
ID3D11Device * d3dDevice,
void * data,
UINT byteWidth,
UINT structuredByteStride,
ID3D11Buffer ** structuredBuffer,
bool cpuUpdates,
bool gpuUpdates)
{
UINT bindFlags = D3D11_BIND_SHADER_RESOURCE;
D3D11_USAGE usage;
UINT cpuAccessFlags = 0;
if (cpuUpdates && gpuUpdates)
{
bindFlags = 0;
usage = D3D11_USAGE_STAGING;
cpuAccessFlags |= D3D11_CPU_ACCESS_READ;
}
else if (!cpuUpdates && !gpuUpdates)
{
usage = D3D11_USAGE_IMMUTABLE;
}
else if (cpuUpdates)
{
usage = D3D11_USAGE_DYNAMIC;
cpuAccessFlags |= D3D11_CPU_ACCESS_WRITE;
}
else
{
usage = D3D11_USAGE_DEFAULT;
bindFlags |= D3D11_BIND_UNORDERED_ACCESS;
}
return CreateBuffer(d3dDevice, data, byteWidth, structuredBuffer,
usage, bindFlags, cpuAccessFlags, structuredByteStride,
D3D11_RESOURCE_MISC_BUFFER_STRUCTURED);
}无论是SRV还是UAV,在指定Format时只能指定DXGI_FORMAT_UNKNOWN。
如果我们希望它作为StructuredBuffer<Data>使用,则需要创建着色器资源视图:
D3D11_SHADER_RESOURCE_VIEW_DESC srvDesc;
srvDesc.Format = DXGI_FORMAT_UNKNOWN;
srvDesc.ViewDimension = D3D11_SRV_DIMENSION_BUFFER;
srvDesc.Buffer.FirstElement = 0; // 起始元素的索引
srvDesc.Buffer.NumElements = numElements; // 元素数目
HR(m_pd3dDevice->CreateShaderResourceView(m_pBuffer.Get(), &srvDesc, m_pBufferSRV.GetAddressOf()));而如果我们希望它作为RWStructuredBuffer<float4>使用,则需要创建无序访问视图:
D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc;
uavDesc.Format = DXGI_FORMAT_UNKNOWN;
uavDesc.ViewDimension = D3D11_UAV_DIMENSION_BUFFER;
uavDesc.Buffer.FirstElement = 0; // 起始元素的索引
uavDesc.Buffer.Flags = 0;
uavDesc.Buffer.NumElements = numElements; // 元素数目
m_pd3dDevice->CreateUnorderedAccessView(m_pBuffer.Get(), &uavDesc, m_pBufferUAV.GetAddressOf());追加缓冲区和消耗缓冲区类型实际上是结构化缓冲区的特殊变体资源。因为涉及到修改操作,它们都只能以无序访问视图的方式来使用。如果你只是希望这些结构体数据经过着色器变换并且不需要考虑最终的输出顺序要一致,那么使用这两个缓冲区是一种不错的选择。
ConsumeStructuredBuffer<float3> gVertexIn : register(u0);
AppendStructuredBuffer<float3> gVertexOut : register(u1);在HLSL中,AppendStructuredBuffer仅提供了Append方法用于尾端追加成员;而ConsumeStructuredBuffer则仅提供了Consume方法用于消耗尾端成员。这两种操作实际上可以看做是对栈的操作。此外,你也可以使用GetDimensions方法来获取当前缓冲区还剩下多少元素。
一旦某个线程消耗了一个数据元素,就不能再被另一个线程给消耗掉,并且一个线程将只消耗一个数据。需要注意的是,因为线程之间的执行顺序是不确定的,因此无法根据线程ID来确定当前消耗的是哪个索引的资源。
此外,追加/消耗缓冲区实际上并不能动态增长,你必须在创建缓冲区的时候就要分配好足够大的空间。
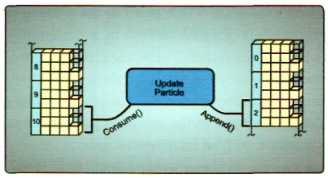
追加/消耗缓冲区可以经由CreateStructuredBuffer函数来创建,需要指定cpuUpdates为false, gpuUpdates为true.
比较关键的是UAV的创建,需要像结构化缓冲区一样指定Format为DXGI_FORMAT_UNKNOWN。并且无论是追加缓冲区,还是消耗缓冲区,都需要在Buffer.Flags中指定D3D11_BUFFER_UAV_FLAG_APPEND:
D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc;
uavDesc.Format = DXGI_FORMAT_UNKNOWN;
uavDesc.ViewDimension = D3D11_UAV_DIMENSION_BUFFER;
uavDesc.Buffer.FirstElement = 0; // 起始元素的索引
uavDesc.Buffer.Flags = D3D11_BUFFER_UAV_FLAG_APPEND;
uavDesc.Buffer.NumElements = numElements; // 元素数目
HR(m_pd3dDevice->CreateUnorderedAccessView(m_pVertexInput.Get(), &uavDesc, m_pVertexInputUAV.GetAddressOf()));然后在将UAV绑定到着色器时,如果是追加缓冲区,通常需要指定初始元素数目为0,然后提供给ID3D11DeviceContext::*SSetUnorderedAccessViews方法的最后一个参数:
UINT initCounts[1] = { 0 };
m_pd3dImmediateContext->CSSetUnorderedAccessViews(0, 1, m_pVertexInputUAV.GetAddressOf(), initCounts);而如果是消耗缓冲区,则需要指定初始元素数目:
UINT initCounts[1] = { numElements };
m_pd3dImmediateContext->CSSetUnorderedAccessViews(1, 1, m_pVertexInputUAV.GetAddressOf(), initCounts);(未完待续)
DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
标签:dimen 数据 type lse cpu 视图 变量 ini view
原文地址:https://www.cnblogs.com/lonelyxmas/p/10811454.html