标签:研究 文件 为什么 代码下载 mes 包含 提前 ipy class
首先介绍MNIST 数据集。如图1-1 所示, MNIST 数据集主要由一些手写数字的图片和相应的标签组成,图片一共有10 类,分别对应从0~9 ,共10 个阿拉伯数字。

原始的MNIST 数据库一共包含下面4 个文件, 见表1-1 。
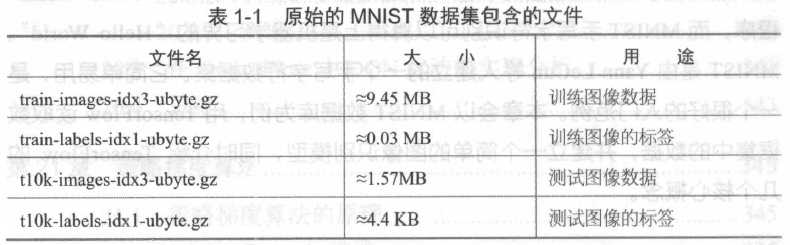
在表1 - 1 中,图像数据是指很多张手写字符的图像,图像的标签是指每一张图像实际对应的数字是几,也就是说,在MNIST 数据集中的每一张图像都事先标明了对应的数字。
在MNIST 数据集中有两类图像:一类是训练图像(对应文件train-images-idx3-ubyte.gz 和train - labels-idx1-ubyte.gz ), 另一类是测试图像(对应文件t10k-images-idx3-ubyte.gz 和t10k-labels-idx1-ubyte.gz ) 。训练图像一共有60000 张,供研究人员训练出合适的模型。测试图像一共有10000 张,供研究人员测试训练的模型的性能。在TensorFlow 中, 可以使用下面的Python 代码下载MNIST 数据(在随书附赠的代码中,该代码对应的文件是donwload.py )。
# 从tensorflow.examples.tutorials.mnist引入模块。这是TensorFlow为了教学MNIST而提前编制的程序
from tensorflow.examples.tutorials.mnist import input_data
# 从MNIST_data/中读取MNIST数据。这条语句在数据不存在时,会自动执行下载
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
在执行语句mnist = input_ data.read_ data_ sets("MNIST_data/”,one_hot=True)时, TensorFlow 会检测数据是否存在。当数据不存在时,系统会自动将数据下载到MNIST_data/ 文件夹中。当执行完语句后,读者可以自行前往MNIST_data/ 文件夹下查看上述4 个文件是否已经被正确地下载。

成功加载MNIST 数据集后,得到了一个mnist 对象,可以通过mnist对象的属性访问到MNIST 数据集,见表1 -2 。
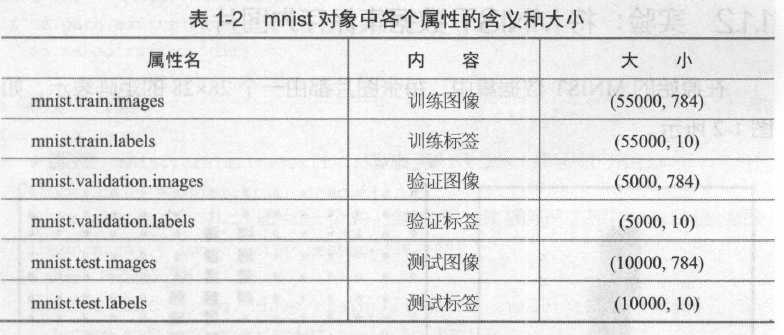
运行下列代码可以查看各个变量的形状大小:
# 查看训练数据的大小 print(mnist.train.images.shape) print(mnist.train.labels.shape) # 查看验证数据的大小 print(mnist.validation.images.shape) print(mnist.validation.labels.shape) # 查看测试数据的大小 print(mnist.test.images.shape) print(mnist.test.labels.shape)
原始的MNIST 数据集中包含了 60000 张训练图片和10000 张测试图片。而在TensorFlow 中,又将原先的60000 张训练图片重新划分成了新的55000张训练图片和5000 张验证图片。所以在mnist 对象中,数据一共分为三部分: mnist.train 是训练图片数据, mnist. validation 是验证图片数据, mnist.test是测试图片数据,这正好对应了机器学习中的训练集、验证集和测试集。一般来说,会在训练集上训练模型,通过模型在验证集上的表现调整参数,最后通过测试集确定模型的性能。
在原始的MNIST 数据集中,每张图片都由一个28 ×28 的矩阵表示,如图 所示。
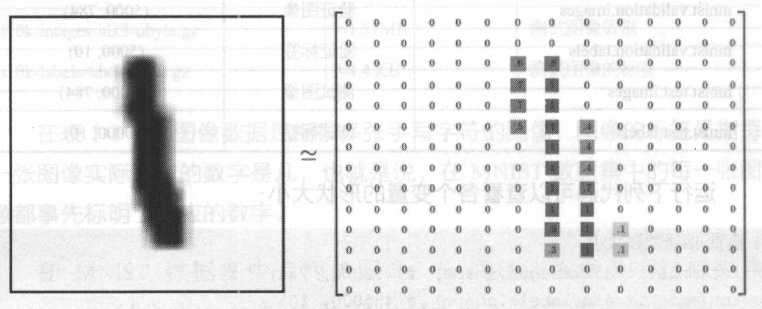
在TensorFlow 中,变量mnist.train.images 是训练样本, 它的形状为(55000,784)。其中,5000 是训练图像的个数,而784 实际为单个样本的维数,即每张图片都由一个784 维的向量表示( 784 正好等于28 ×28 ) 。可以使用以下代码打印出第0 张训练图片对应的向量表示:
# 打印出第0张图片的向量表示 print(mnist.train.images[0,:]) # 打印出第0幅图片的标签 print(mnist.train.labels[0, :])
为了加深对这种表示的理解,下面完成一个简单的程序:将MNIST 数据集读取出来,并保存为图片文件。对应的代码文件为save_pic.py。
from tensorflow.examples.tutorials.mnist import input_data
import scipy.misc
import os
# 读取MNIST数据集。如果不存在会事先下载
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
# 把原始图片保存在MNIST_data/raw/文件夹下 如果没有这个文件夹 会自动创建
save_dir = ‘MNIST_data/raw/‘
if os.path.exists(save_dir) is False:
os.mkdir(save_dir)
# 保存前20张图片
for i in range(20):
# 请注意,mnist.train.images[i, :]就表示第i张图片(序号从0开始)
image_array = mnist.train.images[i,:]
# TensorFlow中的MNIST图片是一个784维的向量,我们重新把它还原为28x28维的图像。
image_array = image_array.reshape(28,28)
# 保存文件的格式为 mnist_train_0.jpg, mnist_train_1.jpg, ... ,mnist_train_19.jpg
filename = save_dir+‘mnist_train_%d.jpg‘ % i
# 将image_array保存为图片
# 先用scipy.misc.toimage转换为图像,再调用save直接保存。
scipy.misc.toimage(image_array,cmin=0.0,cmax=1.0).save(filename) # 版本不支持但是还是可以保存为图片
运行此程序后, 在MNIST_data/raw/ 文件夹下就可以看到MNIST 数据集中训练集的前20 张图片。

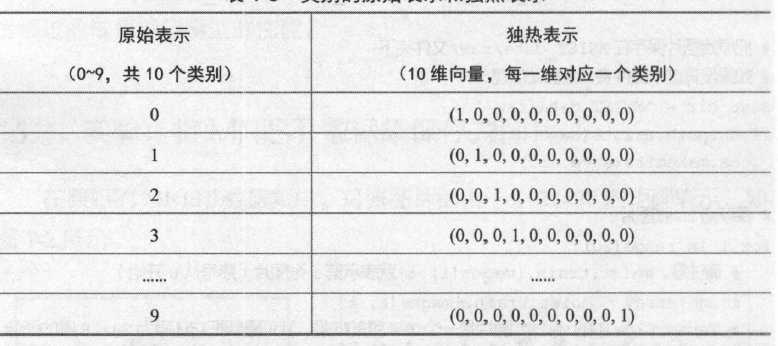
变量mnist. train.labels 表示训练图像的标签,它的形状是(55000, 10)。原始的图像标签是数字0~9 ,我们完全可以用一个数字来存储图像标签,但为什么这里每个训练标签是一个10 维的向量呢?其实,这个10 维的向量是原先类别号的独热( one-hot )表示。所谓独热表示,就是“一位高效编码” 。我们用N维的向量来表示N 个类别,每个类别占据独立的一位,任何时候独热表示中只再一位是1 ,其他都为0 。读者可以直接从表中理解独热表示。
我们可以打印出前20 张图片的标签(对应程序label.py ),读者可以尝试与前面程序中保存的图片对照,查看图像与图像的标签是否正确地对应上了。
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
# 读取MNIST数据集。如果不存在会事先下载
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
# 看前20张训练图片的label
for i in range(20):
# 得到独热表示,形如(0, 1, 0, 0, 0, 0, 0, 0, 0, 0)
one_hot_label = mnist.train.labels[i,:]
# 通过np.argmax我们可以直接获得原始的label
# 因为只有1位为1,其他都是0
label = np.argmax(one_hot_label)
print(‘mnist_train_%d.jpg label: %d‘ % (i, label))

标签:研究 文件 为什么 代码下载 mes 包含 提前 ipy class
原文地址:https://www.cnblogs.com/xiaoyh/p/10813413.html