标签:default 安装步骤 退出 步骤 incr word database bashrc mapred
1.sqoop的概述
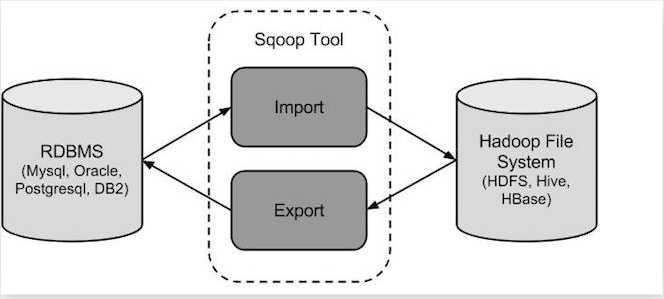
a.sqoop 是一款工具,是appche 旗下的一款工具,主要是负责 hadoop与RDBMS之间的数据迁移,即从hadoop 文件系统 导出数据到RDBMS,从RDBMS导入数据到hadoop hdfs,hive,hbase等数据存储系统。
b.其实就是将 sqoop命令转换成MR程序来完成数据的迁移。
c.本质就是执行和计算,依赖于hdfs存储数据,把sql转换成程序。
2.sqoop的工作机制
将导入或导出命令翻译成 MapReduce 程序来实现 在翻译出的 MapReduce 中主要是对 InputFormat 和 OutputFormat 进行定制
3.sqoop安装
a.前提概述
以后sqoop 会跟以下系统或者组件打交道:
HDFS,MapReduce,YARN,ZooKeeper,Hive,HBASE,Mysql
记住:sqoop就是一个工具,只需要在一个节点上进行安装即可。
b.软件下载
下载地址:http://mirrors.hust.edu.cn/apache/
版本选择:选择sqoop-1.4.6.bin_hadoop-2.0.4-alpha.tar.gz
c.安装步骤
1.拿到包之后,通过xftp上传到 mater /usr/local/app目录下
2.解压缩 tar -zxvf sqoop-1.4.6.bin_hadoop-2.0.4-alpha.tar.gz
3.将解压缩的文件移动到/usr/local/app/sqoop 目录下
sudo mv sqoop-1.4.6.bin_hadoop-2.0.4-alpha /usr/local/app/sqoop
4.进入到conf文件夹
cd /usr/local/app/sqoop/conf
5.将sqoop-env-template.sh复制为 sqoop-env.sh
6.修改sqoop-env.sh
vim sqoop-env,sh
加入以下代码,路径注意修改
export HADOOP_COMMON_HOME=/usr/local/app/hadoop
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/usr/local/app/hadoop
#set the path to where bin/hbase is available
#export HBASE_HOME=/home/hadoop/apps/hbase-1.2.6
#Set the path to where bin/hive is available
export HIVE_HOME=/usr/local/app/hive
#Set the path for where zookeper config dir is
#export ZOOCFGDIR=/home/hadoop/apps/zookeeper-3.4.10/conf
7.加入mysql驱动包到 /usr/local/app/sqoop/lib目录下
cp mysql-connector-java-5.1.40-bin.jar /usr/local/app/sqoop/lib/
8.环境变量配置
sudo gedit ~/.bashrc
添加以下变量:
#Sqoop variable
export SQOOP_HOME=/usr/local/app/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
#sqoop variable
保存退出,然后使其生效
source ~/.bashrc
9.验证安装是否成功
sqoop-version
4.sqoop的基本命令
sqoop help
查看sqoop的具体的一条命令使用,比如:
sqoop help import
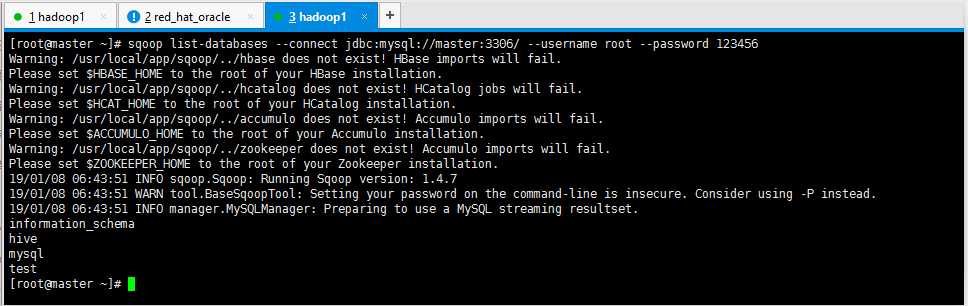
1.列出MySql数据有哪些数据库
sqoop list-databases --connect jdbc:mysql://master:3306/ --username root --password 123456
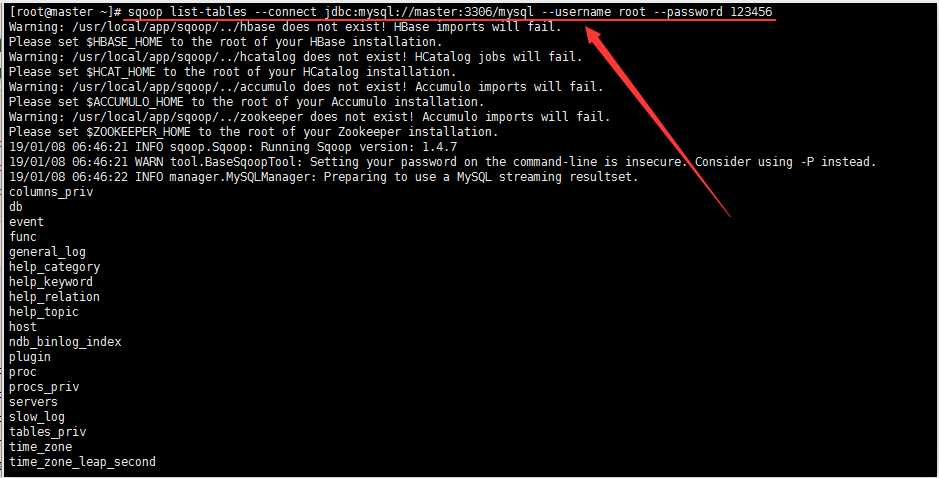
2.列出Mysql中的某个数据库有哪些数据表
3.创建一张跟mysql中help_keyword表一样的hive表hk
执行以下脚本,报错
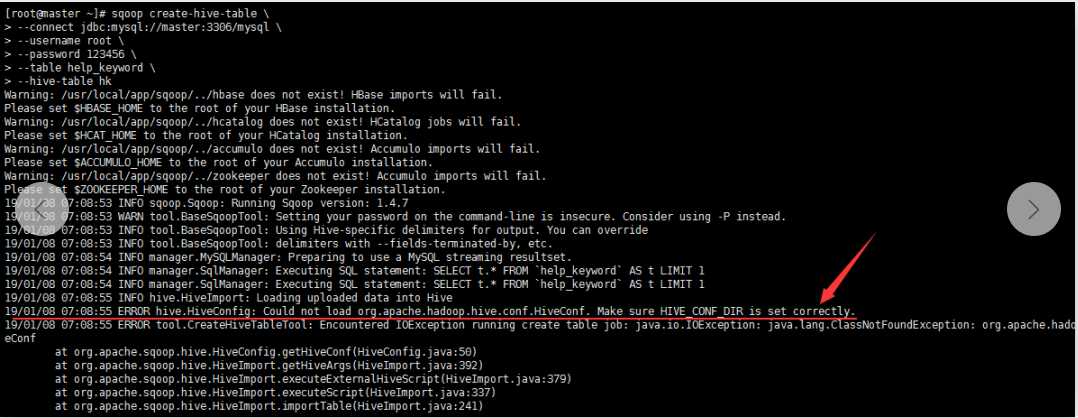
百度给到的解决办法:
Sqoop导入mysql表中的数据到hive,出现如下错误:
ERROR hive.HiveConfig: Could not load org.apache.hadoop.hive.conf.HiveConf. Make sure HIVE_CONF_DIR is set correctly.
命令如下:
./sqoop import --connect jdbc:mysql://slave2:3306/mysql --username root --password aaa --table people --hive-import --hive-overwrite --hive-table people --fields-terminated-by ‘\t‘;
解决方法:
往/etc/profile最后加入 export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
然后刷新配置,source /etc/profile
5.sqoop的数据导入导出
1.从RDBMS导入到HDFS
sqoop import \
--connect jdbc:mysql://master:3306/mysql \
--username root \
--password 123456 \
--table help_keyword \
-m 1
-m 1 表示使用1个mapreduce
sqoop是apache开源项目,主要用于关系型数据库数据和hdfs数据的相互同步.
主要记录下-m和--split-by参数的使用:
1. 这俩参数一般是放在一起使用
2.-m:表明需要使用几个map任务并发执行
3.--split-by :拆分数据的字段. -m设置为4,数据有100条,sqoop首先会获取拆分字段的最大值,最小值,步长为100/4=25;
那么第一个map执行拆分字段值为(1,25)之间的数据
第二个map执行拆分字段值为(26,50)之间的数据
第三个map执行拆分字段值为(51,75)之间的数据
第四个map执行拆分字段值为(76,100)之间的数据
注意事项:
1.拆分字段默认为主键
2.拆分字段的数据类型最好为int,如果不是则将-m设置为1,split-by不设置
3.拆分字段的值最好分布均匀,否则会造成数据倾斜的问题
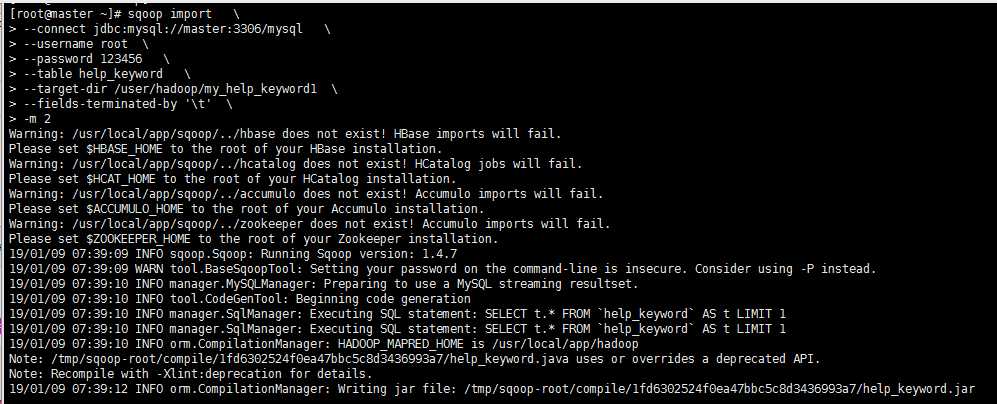
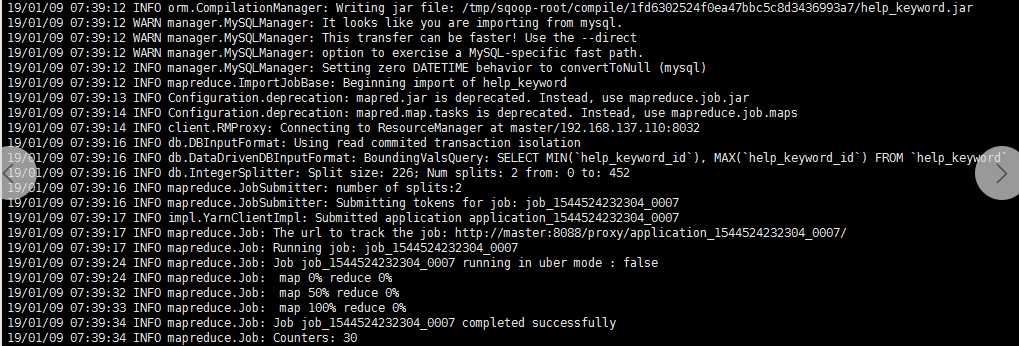
2.指定行分隔符和列分隔符,指定hive-import
sqoop import \
--connect jdbc:mysql://master:3306/mysql \
--username root \
--password 123456 \
--table help_keyword \
--target-dir /user/hadoop/my_help_keyword1 \
--fields-terminated-by ‘\t‘ \
-m 2
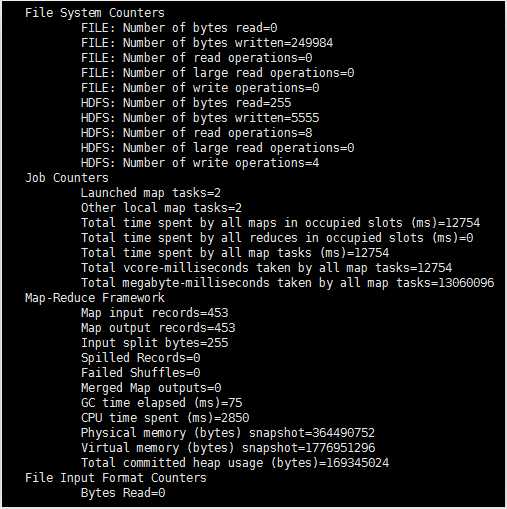
3.带where条件
sqoop import \
--connect jdbc:mysql://master:3306/mysql \
--username root \
--password 123456 \
--where "name=‘STRING‘ " \
--table help_keyword \
--target-dir /user/hadoop1/my_help_keyword1 \
-m 1
4.查询指定列
5.指定自定义查询sql
sqoop import \
--connect jdbc:mysql://master:3306/ \
--username root \
--password 123456 \
--target-dir /user/hadoop3/myimport33_1 \
--query ‘select help_keyword_id,name from mysql.help_keyword where $CONDITIONS and name = "STRING"‘ \
--split-by help_keyword_id \
--fields-terminated-by ‘\t‘ \
-m 4
说明:在以上需要按照自定义SQL语句导出数据到HDFS的情况下:
1、引号问题,要么外层使用单引号,内层使用双引号,$CONDITIONS的$符号不用转义, 要么外层使用双引号,那么内层使用单引号,然后$CONDITIONS的$符号需要转义
2、自定义的SQL语句中必须带有WHERE \$CONDITIONS
6.把Mysql数据库中的表数据导入到hive中
sqoop导入关系型数据到hive的过程,是先导入到hdf中,然后再load进入hive中
6.1.普通导入:数据存储在默认的default hive库中,表名就是对应的mysql的表名:
sqoop import \
--connect jdbc:mysql://master:3306/mysql \
--username root \
--password 123456 \
--table help_keyword \
--hive-import \
-m 1
删除HDFS文件:
hadoop fs -rm /user/root/help_keyword/*
删除HDFS目录:
hadoop fs -rm -R /user/root/help_keyword
6.2.指定行分隔符和列分隔符,指定hive-import,指定覆盖导入,指定自动创建hive表,指定表名,指定删除中间结果数据目录
sqoop import \
--connect jdbc:mysql://master:3306/mysql \
--username root \
--password 123456 \
--table help_keyword \
--fields-terminated-by "\t" \
--lines-terminated-by "\n" \
--hive-import \
--hive-overwrite \
--create-hive-table \
--delete-target-dir \
--hive-database mydb_test \
--hive-table new_help_keyword
执行失败,报以下错误
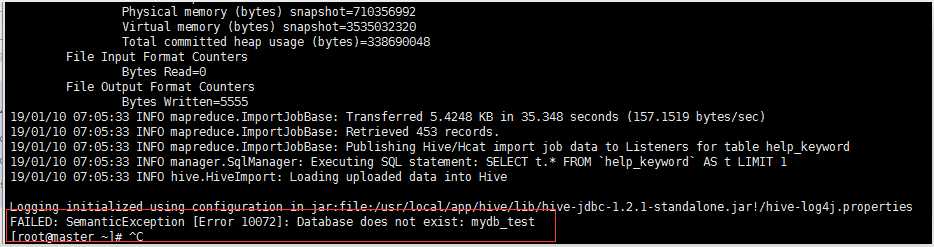
百度之后,解决方案如下:
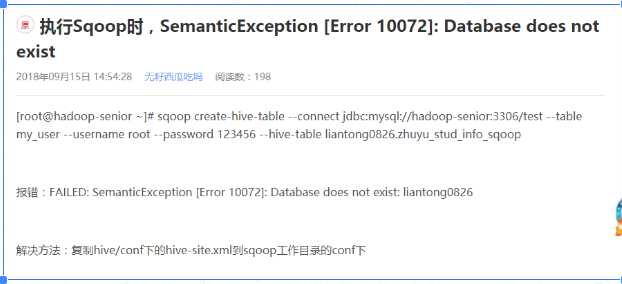
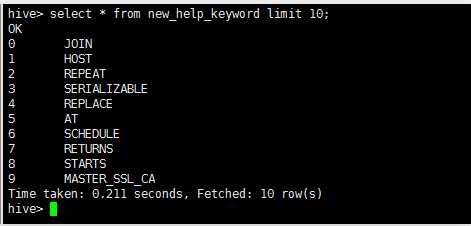
增量导入:
sqoop import \
--connect jdbc:mysql://hadoop1:3306/mysql \
--username root \
--password root \
--table help_keyword \
--target-dir /user/hadoop/myimport_add \
--incremental append \
--check-column help_keyword_id \
--last-value 500 \
-m 1
标签:default 安装步骤 退出 步骤 incr word database bashrc mapred
原文地址:https://www.cnblogs.com/eija/p/10821125.html