标签:inf ast lan 生态 property lin database 图片 集成
(一)Hive 概述

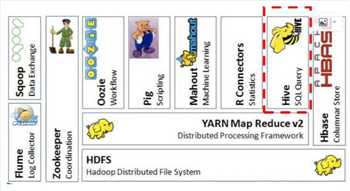
(二)Hive在Hadoop生态圈中的位置
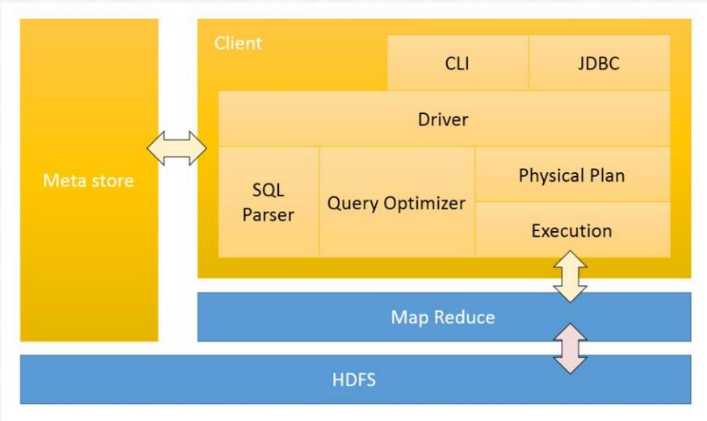
(三)Hive 架构设计

(四)Hive 的优点及应用场景

(五)Hive 的下载和安装部署
1.Hive 下载
Apache版本的Hive。
Cloudera版本的Hive。
这里选择下载Apache稳定版本apache-hive-0.13.1-bin.tar.gz,并上传至bigdata-pro03.kfk.com节点的/opt/softwares/目录下。
2.解压安装hive
tar -zxf apache-hive-0.13.1-bin.tar.gz -C /opt/modules/
3.修改hive-log4j.properties配置文件
cd /opt/modules/hive-0.13.1-bin/conf
mv hive-log4j.properties.template hive-log4j.properties
vi hive-log4j.properties
#日志目录需要提前创建
hive.log.dir=/opt/modules/hive-0.13.1-bin/logs
4.修改hive-env.sh配置文件
mv hive-env.sh.template hive-env.sh
vi hive-env.sh
export HADOOP_HOME=/opt/modules/hadoop-2.5.0
export HIVE_CONF_DIR=/opt/modules/hive-0.13.1-bin/conf
5.首先启动HDFS,然后创建Hive的目录
bin/hdfs dfs -mkdir -p /user/hive/warehouse
bin/hdfs dfs -chmod g+w /user/hive/warehouse
6.启动hive
./hive
#查看数据库
show databases;
#使用默认数据库
use default;
#查看表
show tables;
(六)Hive 与MySQL集成
1.在/opt/modules/hive-0.13.1-bin/conf目录下创建hive-site.xml文件,配置mysql元数据库。
vi hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata-pro01.kfk.com/metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
2.设置用户连接
1)查看用户信息
mysql -uroot -p123456
show databases;
use mysql;
show tables;
select User,Host,Password from user;
2)更新用户信息
update user set Host=‘%‘ where User = ‘root‘ and Host=‘localhost‘
3)删除用户信息
delete from user where user=‘root‘ and host=‘127.0.0.1‘
select User,Host,Password from user;
delete from user where host=‘localhost‘
4)刷新信息
flush privileges;
3.拷贝mysql驱动包到hive的lib目录下
cp mysql-connector-java-5.1.27.jar /opt/modules/hive-0.13.1/lib/
4.保证第三台集群到其他节点无秘钥登录
(七)Hive 服务启动与测试
1.启动HDFS和YARN服务
2.启动hive
./hive
3.通过hive服务创建表
CREATE TABLE stu(id INT,name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ ;
4.创建数据文件
vi /opt/datas/stu.txt
00001 zhangsan
00002 lisi
00003 wangwu
00004 zhaoliu
5.加载数据到hive表中
load data local inpath ‘/opt/datas/stu.txt‘ into table stu;
(八)Hive与HBase集成
1.在hive-site.xml文件中配置Zookeeper,hive通过这个参数去连接HBase集群。
<property>
<name>hbase.zookeeper.quorum</name> <value>bigdata-pro01.kfk.com,bigdata-pro02.kfk.com,bigdata-pro03.kfk.com</value>
</property>
2.将hbase的9个包拷贝到hive/lib目录下。如果是CDH版本,已经集成好不需要导包。

3.创建与HBase集成的Hive的外部表
create external table weblogs(id string,datatime string,userid string,searchname string,retorder string,cliorder string,cliurl string) STORED BY ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler‘ WITH SERDEPROPERTIES("hbase.columns.mapping" = ":key,info:datatime,info:userid,info:searchname,info:retorder,info:cliorder,info:cliurl") TBLPROPERTIES("hbase.table.name" = "weblogs");
#查看hbase数据记录
select count(*) from weblogs;
4.hive 中beeline和hiveserver2的使用
1)启动hiveserver2
bin/hiveserver2
2)启动beeline
bin/beeline
#连接hive2服务
!connect jdbc:hive2//bigdata-pro03.kfk.com:10000
#查看表
show tables;
#查看前10条数据
select * from weblogs limit 10;
新闻网大数据实时分析可视化系统项目——12、Hive与HBase集成进行数据分析
标签:inf ast lan 生态 property lin database 图片 集成
原文地址:https://www.cnblogs.com/ratels/p/10844946.html