标签:模式 info 项管 one bat body kibana ast 管道
ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源、任何格式的数据,并且能够实时地对数据进行搜索、分析和可视化。
最近查看 ELK 官方网站,发现新一代的日志采集器 Filebeat,他是 Beats 家族其中的一员,性能超越 logstash,部署简单,占用资源少,可以很方便的和 logstash,ES 对接。
从官方网站可以看出新一代 ELK 架构如下:
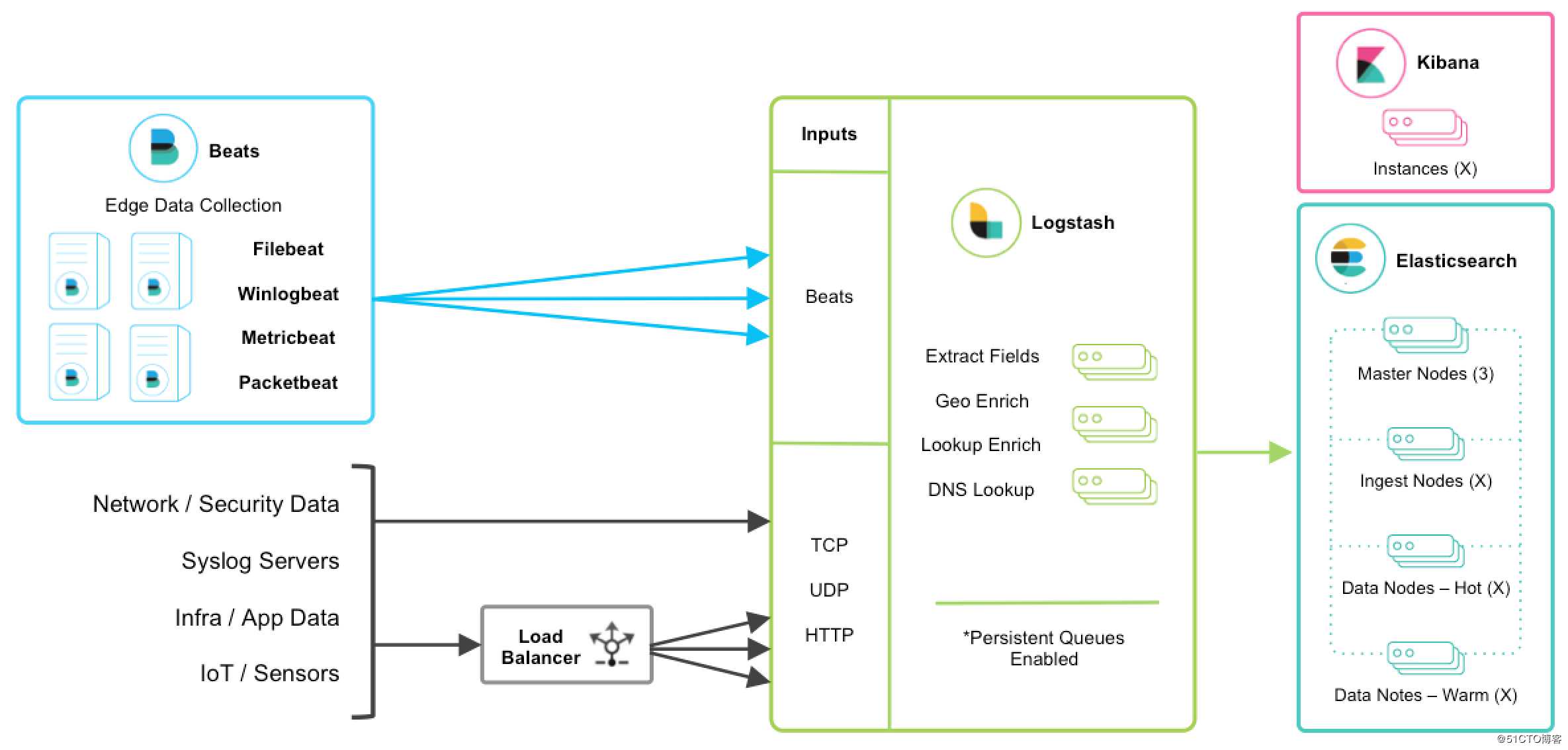
Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。
Beats 家族各采集器如下:
| 采集器 | 采集内容 |
|---|---|
| Auditbeat | 审计数据 |
| Filebeat | 日志文件 |
| Heartbeat | 可用性检测 |
| Metricbeat | 指标 |
| Packetbeat | 网络数据 |
| Winlogbeat | Windows 事件日志 |
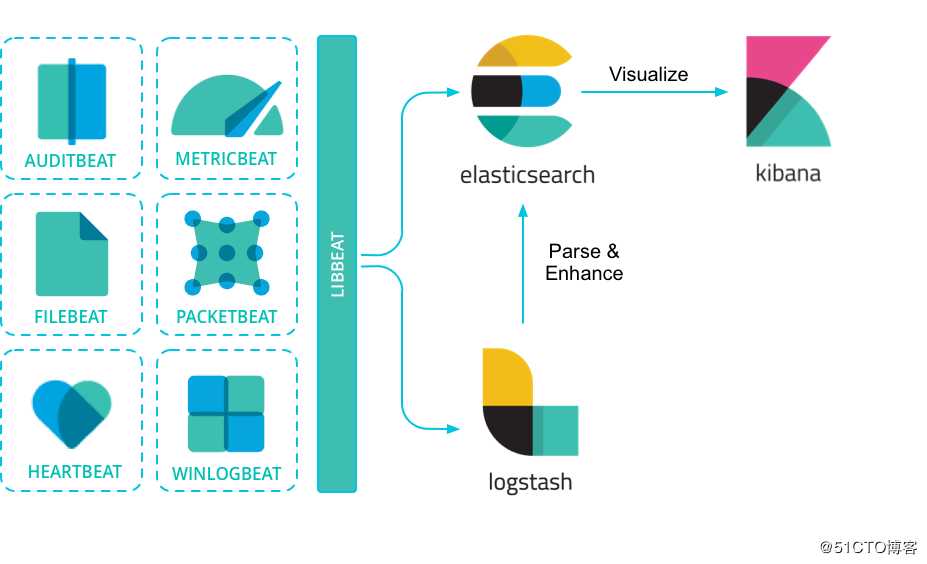
Beats可以直接发送数据到ElasticSearch或通过logstash,在那里您可以进一步处理和增强数据,然后在Kibana可视化。
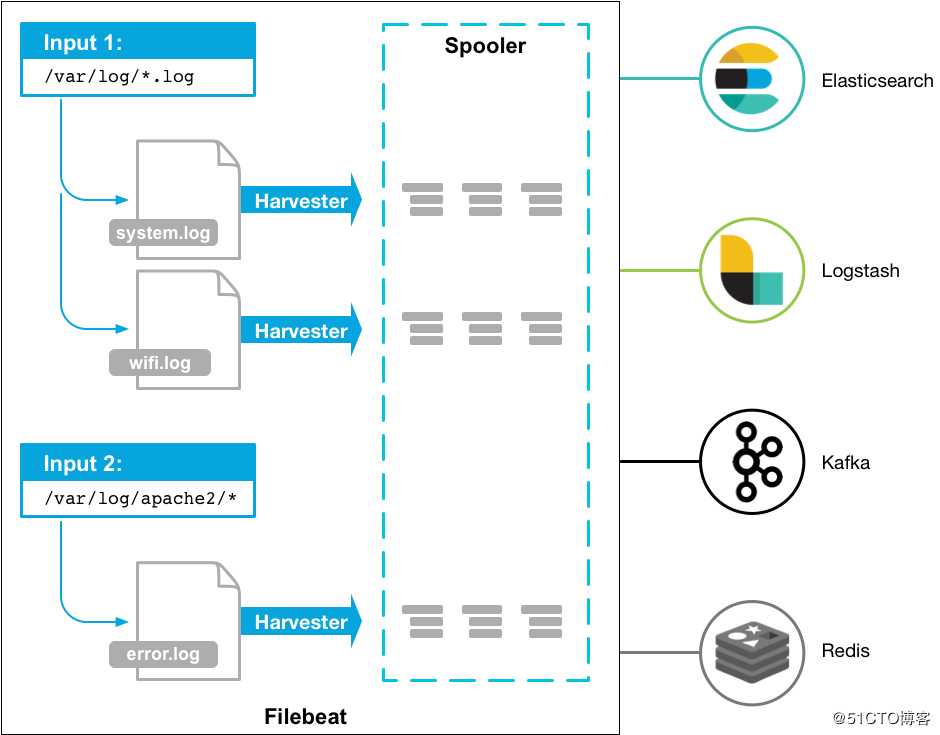
filebat是一个用于转发和集中日志数据的轻量级shipper。作为代理安装在服务器上,filebeat监视指定的日志文件或位置,收集日志事件,并将它们转发给ElasticSearch或logstash进行索引。
以下是filebeat的工作原理:当您启动filebeat时,它将启动一个或多个输入,这些输入位于您为日志数据指定的位置。对于文件记录所在的每一个日志,filebat启动一台harvester。每个harvester读取一个新内容的日志,并将新的日志数据发送到libbeat,ibbeat聚合事件并将聚合的数据发送到filebeat配置的输出。
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(我们的存储库当然是 Elasticsearch。)
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。 Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
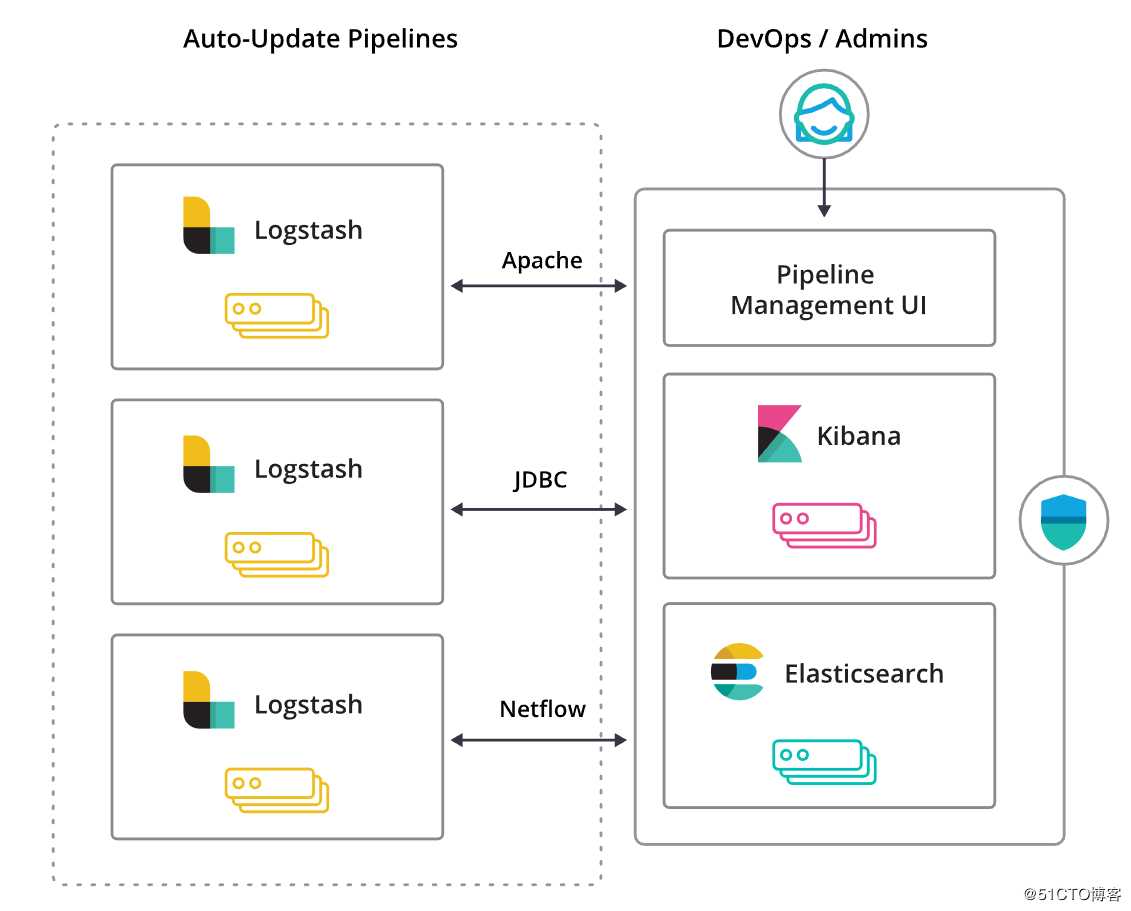
借助 Pipeline 管理图形界面来管理 Logstash 的部署,您可以轻而易举地治理数据加工管道。此外,此项管理功能也与 Elastic Stack 内置的安全特性无缝集成,用以避免任何意外操作。
Elasticsearch 是基于 JSON 的分布式搜索和分析引擎,专为实现水平扩展、高可靠性和管理便捷性而设计。
Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
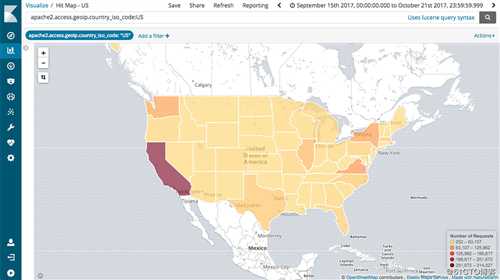
Elasticsearch 允许执行和合并多种类型的搜索 ( 结构化、非结构化、地理位置、度量指标 )搜索方式随心而变。先从一个简单的问题出发,试试看能够从中发现些什么。
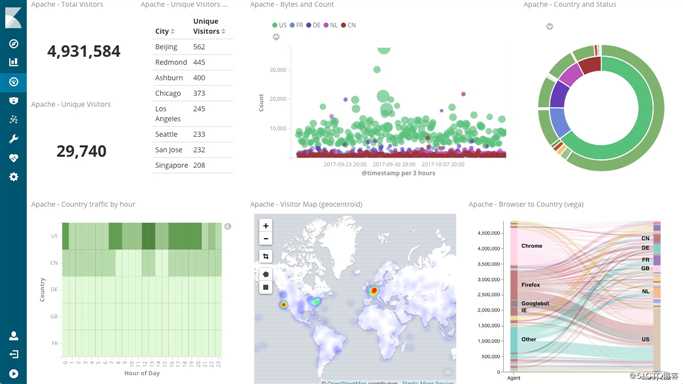
Kibana 能够以图表的形式呈现数据,并且具有可扩展的用户界面,供您全方位配置和管理 Elastic Stack。
Kibana 核心搭载了一批经典功能:柱状图、线状图、饼图、旭日图,等等。它们充分利用了 Elasticsearch 的聚合功能。
Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
Logstash:数据处理引擎,它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到 ES;
Kibana:数据分析和可视化平台。与 Elasticsearch 配合使用,对数据进行搜索、分析和以统计图表的方式展示;
Filebeat:ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,使用 golang 基于 Logstash-Forwarder 源代码开发,是对它的替代。在需要采集日志数据的 server 上安装 Filebeat,并指定日志目录或日志文件后,Filebeat 就能读取数据,迅速发送到 Logstash 进行解析。
在这种架构中,只有一个 Logstash、Elasticsearch 和 Kibana 实例,集中部署于一台服务器。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示。
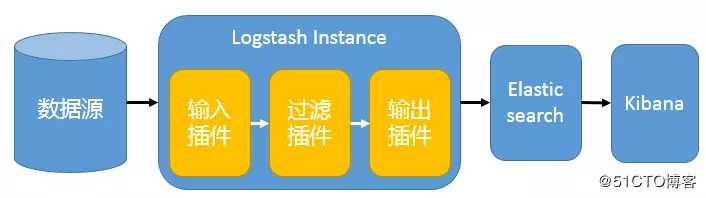
这种架构非常简单,使用场景也有限。初学者可以搭建这个架构,了解 ELK 如何工作。
这种架构是对上面架构的扩展,把一个 Logstash 数据搜集节点扩展到多个,分布于多台机器,将解析好的数据发送到 Elasticsearch server 进行存储,最后在 Kibana 查询、生成日志报表等。
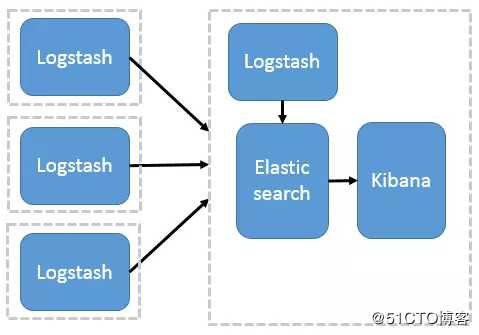
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
这种架构引入 Beats 作为日志搜集器。目前 Beats 包括四种:
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。
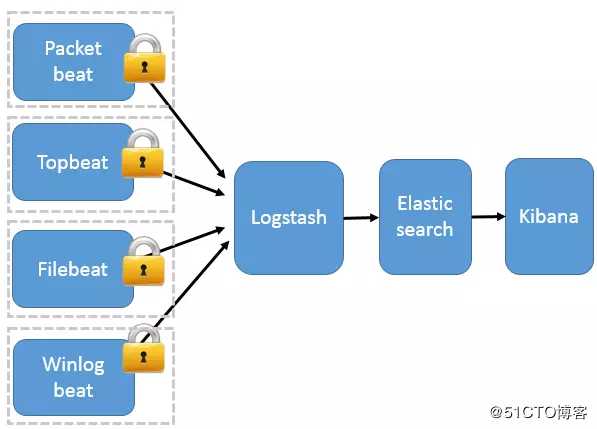
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
这种架构使用 Logstash 从各个数据源搜集数据,然后经消息队列输出插件输出到消息队列中。目前 Logstash 支持 Kafka、Redis、RabbitMQ 等常见消息队列。然后 Logstash 通过消息队列输入插件从队列中获取数据,分析过滤后经输出插件发送到 Elasticsearch,最后通过 Kibana 展示。
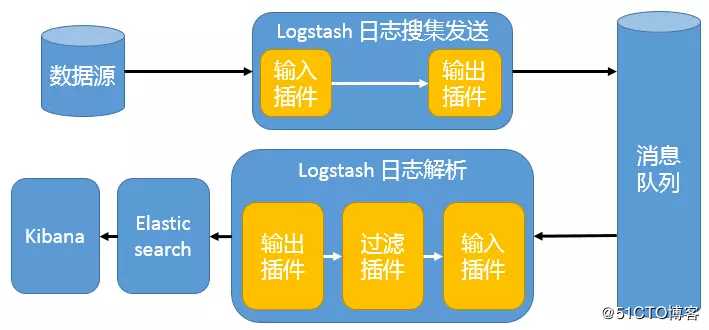
这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题。
Filebeat 已经支持 kafka 作为 ouput,5.2.1 版本的 Logstash 已经支持 Kafka 作为 Input,和上面的架构不同的地方仅在于,把 Logstash 日志搜集发送替换为了 Filebeat。这种架构是当前最为完美的,有极低的客户端采集开销,引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性。
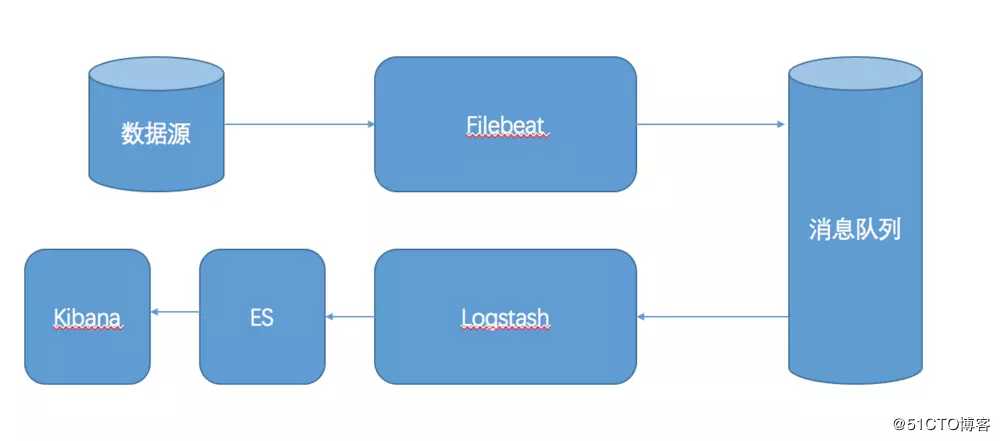
接下来我们进行初步的探视,利用测试环境体验下ELK Stack + Filebeat,测试环境我们就不进行 Kafka 的配置了,因为他的存在意义在于提高可靠性。
ES 集中式日志分析平台 Elastic Stack(介绍)
标签:模式 info 项管 one bat body kibana ast 管道
原文地址:https://www.cnblogs.com/xibuhaohao/p/10844837.html