标签:bytes 可靠性 共享 成功 打开 title 情况下 抽象类 进度
1、HDFS的设计
HDFS是什么:HDFS即Hadoop分布式文件系统(Hadoop Distributed Filesystem),以流式数据访问模式来存储超大文件,运行于商用硬件集群上,是管理网络中跨多台计算机存储的文件系统。
HDFS不适合用在:要求低时间延迟数据访问的应用,存储大量的小文件,多用户写入,任意修改文件。
2、HDFS的概念
HDFS数据块:HDFS上的文件被划分为块大小的多个分块,作为独立的存储单元,称为数据块,默认大小是64MB。
使用数据块的好处是:
查看块信息
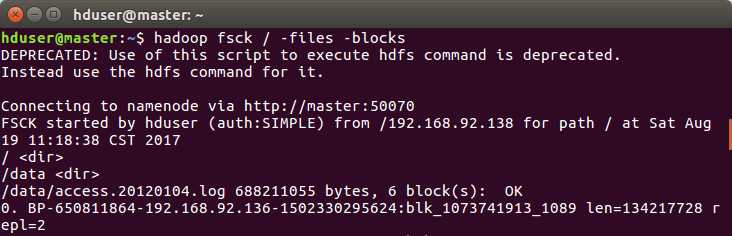
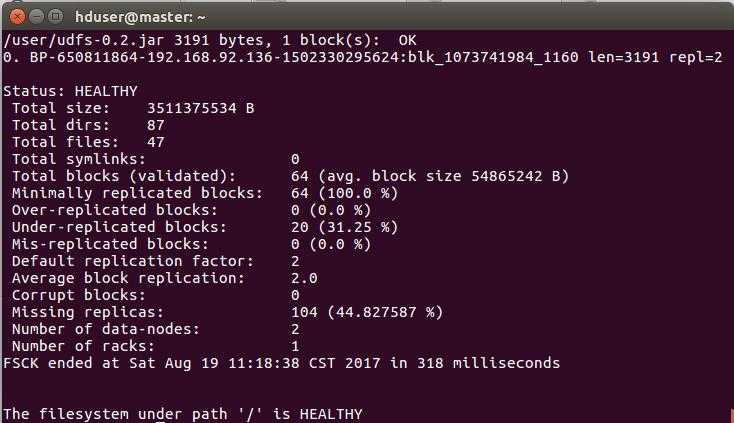
HDFS的三个节点:Namenode,Datanode,Secondary Namenode
Namenode:HDFS的守护进程,用来管理文件系统的命名空间,负责记录文件是如何分割成数据块,以及这些数据块分别被存储到那些数据节点上,它的主要功能是对内存及IO进行集中管理。
Datanode:文件系统的工作节点,根据需要存储和检索数据块,并且定期向namenode发送他们所存储的块的列表。
Secondary Namenode:辅助后台程序,与NameNode进行通信,以便定期保存HDFS元数据的快照。
HDFS Federation(联邦HDFS):
通过添加namenode实现扩展,其中每个namenode管理文件系统命名空间中的一部分。每个namenode维护一个命名空间卷,包括命名空间的源数据和该命名空间下的文件的所有数据块的数据块池。
HDFS的高可用性(High-Availability)
Hadoop的2.x发行版本在HDFS中增加了对高可用性(HA)的支持。在这一实现中,配置了一对活动-备用(active-standby)namenode。当活动namenode失效,备用namenode就会接管它的任务并开始服务于来自客户端的请求,不会有明显的中断。
架构的实现包括:
故障转移控制器:管理着将活动namenode转移给备用namenode的转换过程,基于ZooKeeper并由此确保有且仅有一个活动namenode。每一个namenode运行着一个轻量级的故障转移控制器,其工作就是监视宿主namenode是否失效并在namenode失效时进行故障切换。
3、命令行接口
两个属性项: fs.default.name 用来设置Hadoop的默认文件系统,设置hdfs URL则是配置HDFS为Hadoop的默认文件系统。dfs.replication 设置文件系统块的副本个数
文件系统的基本操作:hadoop fs -help可以获取所有的命令及其解释
常用的有:
HDFS的文件访问权限:只读权限(r),写入权限(w),可执行权限(x)
4、Hadoop文件系统
Hadoop有一个抽象的文件系统概念,HDFS只是其中的一个实现。Java抽象接口org.apache.hadoop.fs.FileSystem定义了Hadoop中的一个文件系统接口。该抽象类实现HDFS的具体实现是 hdfs.DistributedFileSystem
5、Java接口
最简单的从Hadoop URL读取数据 (这里在Eclipse上连接HDFS编译运行)

package filesystem;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws MalformedURLException, IOException {
InputStream in = null;
String input = "hdfs://192.168.92.138:9000/user/test.txt";
try {
in = new URL(input).openStream();
IOUtils.copyBytes(in, System.out, 4096,false);
}finally {
IOUtils.closeStream(in);
}
}
}
这里调用Hadoop的IOUtils类,在输入流和输出流之间复制数据(in和System.out)最后两个参数用于第一个设置复制的缓冲区大小,第二个设置结束后是否关闭数据流。
还可以通过FileSystem API读取数据
代码如下:
package filesystem;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileSystemCat {
public static void main(String[] args) throws IOException {
String uri = "hdfs://192.168.92.136:9000/user/test.txt";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 1024,false);
}finally {
IOUtils.closeStream(in);
}
}
}
这里调用open()函数来获取文件的输入流,FileSystem的get()方法获取FileSystem实例。
使用FileSystem API写入数据
代码如下:
package filesystem;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
public class FileCopyWithProgress {
public static void main(String[] args) throws Exception {
String localSrc = "E:\\share\\input\\2007_12_1.txt";
String dst = "hdfs://192.168.92.136:9000/user/logs/2008_10_2.txt";
InputStream in = new BufferedInputStream(new FileInputStream(localSrc));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst),conf);
OutputStream out = fs.create(new Path(dst),new Progressable() {
public void progress() {
System.out.print("*");
}
});
IOUtils.copyBytes(in, out, 1024,true);
}
}
FileSystem的create()方法用于新建文件,返回FSDataOutputStream对象。 Progressable()用于传递回掉窗口,可以用来把数据写入datanode的进度通知给应用。
使用FileSystem API删除数据
代码如下:
package filesystem;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileDelete {
public static void main(String[] args) throws Exception{
String uri = "hdfs://192.168.92.136:9000/user/1400.txt";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),conf);
fs.delete(new Path(uri));
}
}
使用delete()方法来永久性删除文件或目录。
FileSystem的其它一些方法:
6、数据流
HDFS读取文件过程:
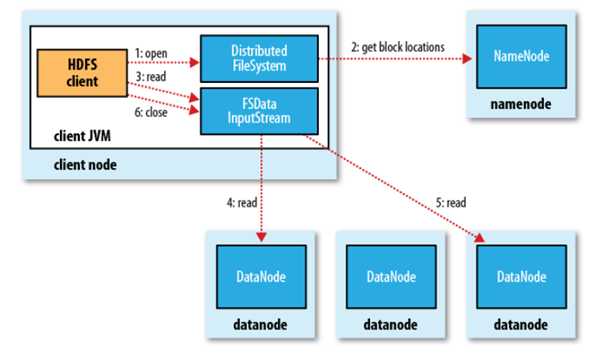
过程描述:
(1)客户端调用FileSyste对象的open()方法在分布式文件系统中打开要读取的文件。
(2)分布式文件系统通过使用RPC(远程过程调用)来调用namenode,确定文件起始块的位置。
(3)分布式文件系统的DistributedFileSystem类返回一个支持文件定位的输入流FSDataInputStream对象,FSDataInputStream对象接着封装DFSInputStream对象(存储着文件起始几个块的datanode地址),客户端对这个输入流调用read()方法。
(4)DFSInputStream连接距离最近的datanode,通过反复调用read方法,将数据从datanode传输到客户端。
(5) 到达块的末端时,DFSInputStream关闭与该datanode的连接,寻找下一个块的最佳datanode。
(6)客户端完成读取,对FSDataInputStream调用close()方法关闭连接。
HDFS文件写入的过程:
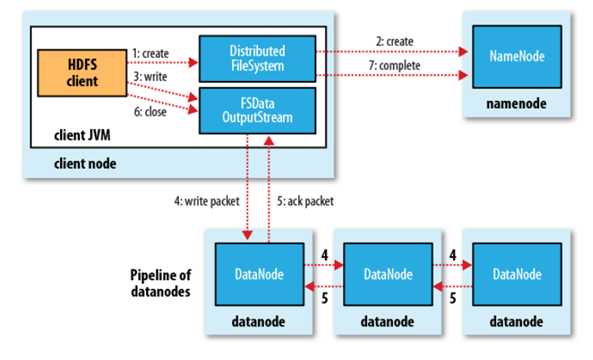
过程描述:
写文件过程分析:
(1) 客户端通过对DistributedFileSystem对象调用create()函数来新建文件。
(2) 分布式文件系统对namenod创建一个RPC调用,在文件系统的命名空间中新建一个文件。
(3)Namenode对新建文件进行检查无误后,分布式文件系统返回给客户端一个FSDataOutputStream对象,FSDataOutputStream对象封装一个DFSoutPutstream对象,负责处理namenode和datanode之间的通信,客户端开始写入数据。
(4)FSDataOutputStream将数据分成一个一个的数据包,写入内部队列“数据队列”,DataStreamer负责将数据包依次流式传输到由一组namenode构成的管线中。
(5)DFSOutputStream维护着确认队列来等待datanode收到确认回执,收到管道中所有datanode确认后,数据包从确认队列删除。
(6)客户端完成数据的写入,对数据流调用close()方法。
(7)namenode确认完成。
namenode如何选择在那个datanode存储复本?
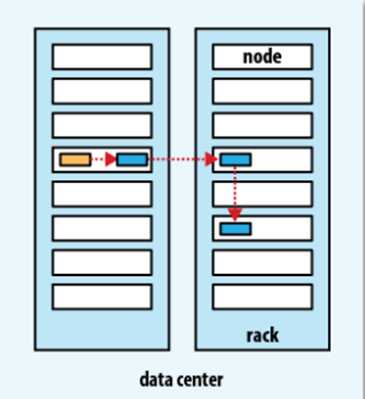
需要对可靠性,写入带宽和读取带宽进行权衡。默认布局是:在运行客户端的节点上放第一个复本(如果客户端运行在集群之外,则在避免挑选存储太满或太忙的节点的情况下随机选择一个节点。)第二个复本放在与第一个不同且随机另外选择的机架中节点上。第三个复本与第二个复本放在同一个机架上,且随机选择另一个节点。其它复本放在集群中随机选择的节点中,尽量避免在同一个机架上放太多复本。
一个复本个数为3的集群放置位置如图:
HDFS一致性:HDFS在写数据务必要保证数据的一致性与持久性,目前HDFS提供的两种两个保证数据一致性的方法 hsync()方法和hflush()方法。
hflush: 保证flush的数据被新的reader读到,但是不保证数据被datanode持久化。
hsync: 与hflush几乎一样,不同的是hsync保证数据被datanode持久化。
深入hsync()和hflush()参考两篇博客
http://www.cnblogs.com/foxmailed/p/4145330.html
http://www.cnblogs.com/yangjiandan/p/3540498.html
7、通过Flume和Sqoop导入数据
可以考虑使用一些现成的工具将数据导入。
Apache Fluem是一个将大规模流数据导入HDFS的工具。典型应用是从另外一个系统中收集日志数据并实现在HDFS中的聚集操作以便用于后期的分析操作。
Apache Sqoop用来将数据从结构化存储设备批量导入HDFS中,例如关系数据库。Sqoop应用场景是组织将白天生产的数据库中的数据在晚间导入Hive数据仓库中进行分析。
8、通过distcp并行复制
distcp分布式复制程序,它从Hadoop文件系统间复制大量数据,也可以将大量的数据复制到Hadoop。
典型应用场景是在HDFS集群之间传输数据。
% hadoop distcp hdfs://namenode1/foo hdfs://namenode2/bar
9、Hadoop存档
HDFS中每个文件均按块方式存储,每个块的元数据存储在namenode的内存中,因此Hadoop存储小文件会非常低效。因为大量的小文件会耗尽namenode中的大部分内存。Hadoop的存档文件或HAR文件,将文件存入HDFS块,减少namenode内存使用,允许对文件进行透明地访问。
Hadoop存档是通过archive工具根据一组文件创建而来的。运行archive指令:
% hadoop archive -archiveName files.har /my/files /my
列出HAR文件的组成部分:
% hadoop fs -ls /my/files.har
files.har是存档文件的名称,这句指令存储 HDFS下/my/files中的文件。
HAR文件的组成部分:两个索引文件以及部分文件的集合。
存档的不足:
新建一个存档文件会创建原始文件的一个副本,因此需要与要存档的文件容量相同大小的磁盘空间。
一旦存档文件,不能从中增加或删除文件。
标签:bytes 可靠性 共享 成功 打开 title 情况下 抽象类 进度
原文地址:https://www.cnblogs.com/1880su/p/10847665.html