标签:tom running span loopback tcp init 内核空间 output 多少
二层发送中,实现qdisc的主要函数是__dev_xmit_skb和net_tx_action,本篇将分析qdisc实现的原理,仅对框架进行分析。
其框架如下图所示
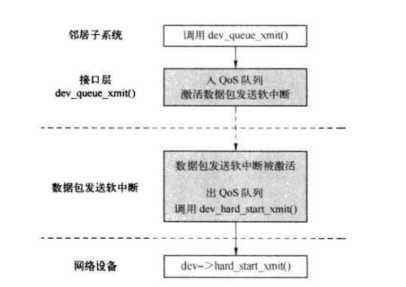
pktsched_init注册了几个系统算法,register_qdisc只是添加算法到一个全局的链表中
注册设备驱动的时候会调用register_netdevice(), register_netdevice()会调用dev_init_scheduler来初始化默认的qidsc为noop_qdisc,
noop_qdisc算法什么也不做,enqueue函数为丢弃数据包。
当ifconfig up网卡后,会调用dev_open()最终分配默认的qdisc算法给队列;
/* "NOOP" scheduler: the best scheduler, recommended for all interfaces
under all circumstances. It is difficult to invent anything faster or
cheaper.
*/
static int noop_enqueue(struct sk_buff *skb, struct Qdisc *qdisc)
{
kfree_skb(skb);
return NET_XMIT_CN;
}
static struct sk_buff *noop_dequeue(struct Qdisc *qdisc)
{
return NULL;
}
struct Qdisc_ops noop_qdisc_ops __read_mostly = {
.id = "noop",
.priv_size = 0,
.enqueue = noop_enqueue,
.dequeue = noop_dequeue,
.peek = noop_dequeue,
.owner = THIS_MODULE,
};
static struct netdev_queue noop_netdev_queue = {
.qdisc = &noop_qdisc,
.qdisc_sleeping = &noop_qdisc,
};
struct Qdisc noop_qdisc = {
.enqueue = noop_enqueue,
.dequeue = noop_dequeue,
.flags = TCQ_F_BUILTIN,
.ops = &noop_qdisc_ops,
.list = LIST_HEAD_INIT(noop_qdisc.list),
.q.lock = __SPIN_LOCK_UNLOCKED(noop_qdisc.q.lock),
.dev_queue = &noop_netdev_queue,
.busylock = __SPIN_LOCK_UNLOCKED(noop_qdisc.busylock),
};
//此时网络设备还不能发送任何数据包,必须等网络设备启用之后才能发送数据包
void dev_init_scheduler(struct net_device *dev)
{
dev->qdisc = &noop_qdisc;
netdev_for_each_tx_queue(dev, dev_init_scheduler_queue, &noop_qdisc);
dev_init_scheduler_queue(dev, &dev->rx_queue, &noop_qdisc);
setup_timer(&dev->watchdog_timer, dev_watchdog, (unsigned long)dev);
}
TC 框架的初始化
/*
tc可以使用以下命令对QDisc、类和过滤器进行操作:
add,在一个节点里加入一个QDisc、类或者过滤器。添加时,需要传递一个祖先作为参数,传递参数时既可以使用ID也可以直接传递设备的根。如果要建立一个QDisc或者过滤器,可以使用句柄(handle)来命名;如果要建立一个类,可以使用类识别符(classid)来命名。
remove,删除有某个句柄(handle)指定的QDisc,根QDisc(root)也可以删除。被删除QDisc上的所有子类以及附属于各个类的过滤器都会被自动删除。
change,以替代的方式修改某些条目。除了句柄(handle)和祖先不能修改以外,change命令的语法和add命令相同。换句话说,change命令不能一定节点的位置。
replace,对一个现有节点进行近于原子操作的删除/添加。如果节点不存在,这个命令就会建立节点。
link,只适用于DQisc,替代一个现有的节点。
tc qdisc [ add | change | replace | link ] dev DEV [ parent qdisc-id | root ] [ handle qdisc-id ] qdisc [ qdisc specific parameters ]
tc class [ add | change | replace ] dev DEV parent qdisc-id [ classid class-id ] qdisc [ qdisc specific parameters ]
tc filter [ add | change | replace ] dev DEV [ parent qdisc-id | root ] protocol protocol prio priority filtertype [ filtertype specific parameters ] flowid flow-id
tc [-s | -d ] qdisc show [ dev DEV ]
tc [-s | -d ] class show dev DEV tc filter show dev DEV
*/
/*
(四)用户空间如何和内核通信
iproute2是一个用户空间的程序,它的功能是解释以tc开头的命令,如果解释成功,把它们通过AF_NETLINK的socket传给Linux的内核空间,使用的netlink协议类型是NETLINK_ROUTE。
发送的netlink数据包都必须包含两个字段:protocol和msgtype,内核根据这两个字段来定位接收函数。
在系统初始化的时候将会调用如下函数:
*/
static int __init pktsched_init(void)
{
int err;
err = register_pernet_subsys(&psched_net_ops);
if (err) {
pr_err("pktsched_init: "
"cannot initialize per netns operations\n");
return err;
}
register_qdisc(&pfifo_fast_ops);
register_qdisc(&pfifo_qdisc_ops);
register_qdisc(&bfifo_qdisc_ops);
register_qdisc(&pfifo_head_drop_qdisc_ops);
register_qdisc(&mq_qdisc_ops);
register_qdisc(&noqueue_qdisc_ops);
//tc filer 的注册在tc_filter_init
//通过rtnetlink_rcv_msg和应用层netlink方式交互
//其中的rtnl_register()函数用于注册TC要接收的消息类型以及对应的接收函数。
//每个表头rtnl_msg_handlers[i]上面存储RTM_NR_MSGTYPES个rtnl_link,图解见TC流量控制实现分析
rtnl_register(PF_UNSPEC, RTM_NEWQDISC, tc_modify_qdisc, NULL, NULL); //tc qdisc add和tc calss change的时候会调用tc_modify_qdisc
rtnl_register(PF_UNSPEC, RTM_DELQDISC, tc_get_qdisc, NULL, NULL);//tc qdisc del的时候会调用tc_modify_qdisc
rtnl_register(PF_UNSPEC, RTM_GETQDISC, tc_get_qdisc, tc_dump_qdisc, NULL);//tc qdisc ls 的时候会调用tc_modify_qdisc
rtnl_register(PF_UNSPEC, RTM_NEWTCLASS, tc_ctl_tclass, NULL, NULL); //tc class add 的时候会调用这个
rtnl_register(PF_UNSPEC, RTM_DELTCLASS, tc_ctl_tclass, NULL, NULL);//tc class del 的时候会调用这个
rtnl_register(PF_UNSPEC, RTM_GETTCLASS, tc_ctl_tclass, tc_dump_tclass, NULL);//tc class ls的时候调用这个
return 0;
}
对于多队列设备,会先调用mq_qdisc_ops算法来做一次代理
在mq_init中为每个队列分配默认的pfifo_fast_ops算法保持在mq_qdisc_ops的private结构中
然后马上调用mq_attach, 把这些分配好的qdisc,设置到设备队列的qdisc_sleeping中。
最终在dev_activate中把qdisc_sleeping中的qdisc算法,通过transition_one_qdisc赋值到netdev_queue->qdisc
int dev_open(struct net_device *dev)
{
..............................
ret = __dev_open(dev);
..............................
}
static int __dev_open(struct net_device *dev)
{
...................
dev_activate(dev);
add_device_randomness(dev->dev_addr, dev->addr_len);
......................
}
void dev_activate(struct net_device *dev)
{
..................................
/* No queueing discipline is attached to device;
* create default one for devices, which need queueing
* and noqueue_qdisc for virtual interfaces
*/
/*如果没有Qdisc的规则设置到device,就给设备create一个默认的规则*/
if (dev->qdisc == &noop_qdisc)
attach_default_qdiscs(dev);//设置默认qdisc算法
.........................
}
static void attach_default_qdiscs(struct net_device *dev)
{
struct netdev_queue *txq;
struct Qdisc *qdisc;
txq = netdev_get_tx_queue(dev, 0);
/*这个地方判断dev是否是多Q的设备,如果是不是多Q的设备,或者tx_queue_len为0 就会进入if判断
*这个地方比较疑惑,if内部使用的是一个循环去遍历tx_queue 感觉是要处理multiqueue的状况,现在
*却用来处理一个的...*/
if (!netif_is_multiqueue(dev) || dev->tx_queue_len == 0) {
netdev_for_each_tx_queue(dev, attach_one_default_qdisc, NULL);
dev->qdisc = txq->qdisc_sleeping;
atomic_inc(&dev->qdisc->refcnt);
} else {
/*如果不满足上述条件,就创建一个默认的,mq_qdisc_ops,从他的注释来看 mq 的Qdisc只使用与多Q状况*/
qdisc = qdisc_create_dflt(txq, &mq_qdisc_ops, TC_H_ROOT);//调用mq_init
if (qdisc) {
dev->qdisc = qdisc;
qdisc->ops->attach(qdisc);//mq_attach
}
}
}
truct Qdisc *qdisc_create_dflt(struct netdev_queue *dev_queue,
const struct Qdisc_ops *ops,
unsigned int parentid)
{
struct Qdisc *sch;
if (!try_module_get(ops->owner))
return NULL;
sch = qdisc_alloc(dev_queue, ops);
if (IS_ERR(sch)) {
module_put(ops->owner);
return NULL;
}
sch->parent = parentid;
if (!ops->init || ops->init(sch, NULL) == 0) //mq_init
return sch;
qdisc_destroy(sch);
return NULL;
}
struct mq_sched {
struct Qdisc **qdiscs;
};
static int mq_init(struct Qdisc *sch, struct nlattr *opt)
{
struct net_device *dev = qdisc_dev(sch);
struct mq_sched *priv = qdisc_priv(sch);
struct netdev_queue *dev_queue;
struct Qdisc *qdisc;
unsigned int ntx;
if (sch->parent != TC_H_ROOT)
return -EOPNOTSUPP;
if (!netif_is_multiqueue(dev))
return -EOPNOTSUPP;
/* pre-allocate qdiscs, attachment can‘t fail */
priv->qdiscs = kcalloc(dev->num_tx_queues, sizeof(priv->qdiscs[0]),
GFP_KERNEL);
if (priv->qdiscs == NULL)
return -ENOMEM;
for (ntx = 0; ntx < dev->num_tx_queues; ntx++) {
dev_queue = netdev_get_tx_queue(dev, ntx);
qdisc = qdisc_create_dflt(dev_queue, get_default_qdisc_ops(dev, ntx), //为每个队列分配默认的qdisc算法
TC_H_MAKE(TC_H_MAJ(sch->handle),
TC_H_MIN(ntx + 1)));
if (qdisc == NULL)
goto err;
priv->qdiscs[ntx] = qdisc;
qdisc->flags |= TCQ_F_ONETXQUEUE | TCQ_F_NOPARENT;
}
sch->flags |= TCQ_F_MQROOT;
return 0;
err:
mq_destroy(sch);
return -ENOMEM;
}
static inline const struct Qdisc_ops *
get_default_qdisc_ops(const struct net_device *dev, int ntx)
{
return ntx < dev->real_num_tx_queues ?
default_qdisc_ops : &pfifo_fast_ops;
}
static void mq_attach(struct Qdisc *sch)
{
struct net_device *dev = qdisc_dev(sch);
struct mq_sched *priv = qdisc_priv(sch);
struct Qdisc *qdisc, *old;
unsigned int ntx;
for (ntx = 0; ntx < dev->num_tx_queues; ntx++) {
qdisc = priv->qdiscs[ntx];
old = dev_graft_qdisc(qdisc->dev_queue, qdisc); //设置qdisc到设备队列的qdisc_sleeping中
if (old)
qdisc_destroy(old);
#ifdef CONFIG_NET_SCHED
if (ntx < dev->real_num_tx_queues)
qdisc_hash_add(qdisc);
#endif
}
kfree(priv->qdiscs);
priv->qdiscs = NULL;
}
/* Attach toplevel qdisc to device queue. */
struct Qdisc *dev_graft_qdisc(struct netdev_queue *dev_queue,
struct Qdisc *qdisc)
{
struct Qdisc *oqdisc = dev_queue->qdisc_sleeping;
spinlock_t *root_lock;
root_lock = qdisc_lock(oqdisc);
spin_lock_bh(root_lock);
/* Prune old scheduler */
if (oqdisc && atomic_read(&oqdisc->refcnt) <= 1)
qdisc_reset(oqdisc);
/* ... and graft new one */
if (qdisc == NULL)
qdisc = &noop_qdisc;
dev_queue->qdisc_sleeping = qdisc;
rcu_assign_pointer(dev_queue->qdisc, &noop_qdisc);
spin_unlock_bh(root_lock);
return oqdisc;
}
我们在使用的netdevice基本上都是单队列的,默认情况下都是这个pfifo_fast_ops队列;
/*pfifo_fast_ops pfifo_qdisc_ops tbf_qdisc_ops sfq_qdisc_ops prio_class_ops这几个都为出口,ingress_qdisc_ops为入口 */
struct Qdisc_ops pfifo_fast_ops { //;//__read_mostly = {
.id = "pfifo_fast",
.priv_size = sizeof(struct pfifo_fast_priv),
.enqueue = pfifo_fast_enqueue,
.dequeue = pfifo_fast_dequeue,
.peek = pfifo_fast_peek,
.init = pfifo_fast_init,
.reset = pfifo_fast_reset,
.dump = pfifo_fast_dump,
.owner = THIS_MODULE,
};
可以看到TCQ_F_CAN_BYPASS,这个flag置位,就表明数据包发送不一定非得走队列的规则,可以by pass这个规则,直接通过发送到driver,不过在一般没有阻塞的通讯状况下,有了这个flag,基本就都是直接发送出去了!
假设interface就是使用的pfifo_fast Qdisc规则,那么我们调用的enqueue直接走到pfifo_fast_enqueue,在里面就直接放到队列里,如果超出了最大的积攒数量就DROP掉了,返回NET_XMIT_DROP
//通过skb->priority计算出band,从而来确定把该SKB加入到pfifo_fast_priv的q[i]队列中
static int pfifo_fast_enqueue(struct sk_buff *skb, struct Qdisc* qdisc) //和下面的pfifo_fast_enqueue结合使用
{/*先是要判断一下在Q中的数据包的数量,是否超过了tx_queue_len的值*/
if (skb_queue_len(&qdisc->q) < qdisc_dev(qdisc)->tx_queue_len) {
int band = prio2band[skb->priority & TC_PRIO_MAX];
struct pfifo_fast_priv *priv = qdisc_priv(qdisc);
struct sk_buff_head *list = band2list(priv, band);
//例如0 1 2频道都有数据,则bitmap=二进制0111,也就是7,bitmap2band[7]对应0,也就是首先发送第0频道pfifo_fast_priv->q[0]skb队列数据,
//同理如果0发送完毕,则bitmap变为0x0110,也就是6,bitmap2band[6]对应1,也就是发送第1频道pfifo_fast_priv->q[1]skb队列数据,
priv->bitmap |= (1 << band);
qdisc->q.qlen++;
return __qdisc_enqueue_tail(skb, qdisc, list);
}
return qdisc_drop(skb, qdisc);
}
回到__dev_xmit_skb 这个函数,enqueue完毕之后,如果这个Qdisc不是Running状态,就开启Running状态,然后调用了这个函数__qdisc_run(q);
在其中主要是调用了qdisc_restart来从队列中dequeue出封包,然后再调用sch_direct_xmit函数去直接发送封包,这个函数我们上面有分析过,就是直接发送给driver了
然后出现BUSY的就requeue到队列中。因为有可能从队列中取封包,所以这个函数可能发若干个包,要注意的是这些发送封包的过程都是出于process context
/*
__QDISC_STATE_RUNNING标志用于保证一个流控对象不会同时被多个例程运行。
软中断线程的动作:运行加入到output_queue链表中的所有流控对象,如果试图运行某个流控对象时,发现已经有其他内核路径在运行这个对象,直接返回,并试图运行下一个流控对象。
*/
void __qdisc_run(struct Qdisc *q)
{
int quota = weight_p;
int packets;
/*这个函数是调用qdisc_restart去发送Q中的数据包,packet记录这次发送了多少...*/
while (qdisc_restart(q, &packets)) {
/*
* Ordered by possible occurrence: Postpone processing if
* 1. we‘ve exceeded packet quota
* 2. another process needs the CPU;
*//* 这边会有限定额度64个封包,如果超过64个就不能再次连续发了,
* 需要以后执行softirq去发送了*/
quota -= packets;
if (quota <= 0 || need_resched()) {//将本队列加入软中断的output_queue链表中。
/*将队列加入发送软中断NET_TX_SOFTIRQ的处理队列,当软中断被执行时,队列又会继续发送数据包。*/
__netif_schedule(q);//激活发送软件中的,最终调用net_tx_action
break;
}
}
qdisc_run_end(q);
}

//__qdisc_run -> qdisc_restart -> dequeue_skb -> prio_dequeue(这里面有个递归调用过程) -> qdisc_dequeue_head static inline int qdisc_restart(struct Qdisc *q, int *packets) { struct netdev_queue *txq; struct net_device *dev; spinlock_t *root_lock; struct sk_buff *skb; bool validate; /* Dequeue packet */ skb = dequeue_skb(q, &validate, packets); if (unlikely(!skb)) return 0; root_lock = qdisc_lock(q); dev = qdisc_dev(q); txq = skb_get_tx_queue(dev, skb); /*这个函数之前在将第一种状况的时候讲过,在Qdisc的状况下 也有通过这个函数直接发送的情况 *实际上这个函数是在直接去发送,这个可以直接发送之前留存下来的包,所以函数的解释是 *可以发送若干个封包*/ return sch_direct_xmit(skb, q, dev, txq, root_lock, validate); }
假设已经发送了若干个封包了,已经超过64个,那么会调用__netif_schedule去打开softirq利用软中断去发送在queue的封包;
/*
* 激活数据包输出软中断有多个接口,而
* __netif_schedule()是最常用的。
*///激活发送软件中的,最终调用net_tx_action
void __netif_schedule(struct Qdisc *q)
{
/*
* 如果输出网络设备没有处于流量
* 控制的调度中,则调用__netif_reschedule()
* 激活输出软中断
*/
if (!test_and_set_bit(__QDISC_STATE_SCHED, &q->state))
__netif_reschedule(q);
}
//把Qdisc中的数据放入cpu sd的output_queue_tailp输出队列,将队列加入发送软中断NET_TX_SOFTIRQ的处理队列,当软中断被执行时,队列又会继续发送数据包。__netif_reschedule
/*
由于软中断被激活,软中断的优先级仅次于硬中断,这样就保证了队列会被及时的运行,即保证了数据包会被及时的发送。
*///激活发送软件中的,最终调用net_tx_action
//dev_queue_xmit -> __dev_xmit_skb -> __qdisc_run最终调用到该函数,把流控对象Qdisc添加到CPU软中断的output_queue
static inline void __netif_reschedule(struct Qdisc *q)
{
struct softnet_data *sd;
unsigned long flags;
/*
* 将网络设备链接到softnet_data中的output_queu
* 队列上,然后激活网络输出软中断对该
* 队列进行处理。
*/
local_irq_save(flags);
sd = &__get_cpu_var(softnet_data);
q->next_sched = NULL;
////在net_dev_init中,sd->output_queue_tailp = &sd->output_queue;所以相当于把q添加到了output_queue队列中
*sd->output_queue_tailp = q;
sd->output_queue_tailp = &q->next_sched;
raise_softirq_irqoff(NET_TX_SOFTIRQ); //激活发送软件中的,最终调用net_tx_action
local_irq_restore(flags);
}
net_tx_action便是软中断的执行函数,主要是做2件事情
第一件事情就是free使用完的skb,driver一般发送完数据之后,就会调用dev_kfree_skb_irq 届时这个地方就是来free的
第二件事情就是调用qdisc_run发送数据包了
/*
* net_tx_action()是数据包输出软中断的例程,
* 一旦激活便会遍历output_queue队列中
* 待处理的输出网络设备,然后调用
* qdisc_run()在合适的时机发送数据包。
* 数据包输出软中断通常有netif_schedule()激活。
*/ //qos tc 流量控制的时候会用到
static void net_tx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
/*
* 如果当前CPU的softnet_data中存在已完成
* 输出待释放的数据包,则遍历
* completion_queue队列,释放该队列中所有
* 数据包,对于发送而言,硬中断只是通过网卡把包发走,但是回收内存的事情是通过软中断来做的,
*设备驱动发送完数据之后,会调用dev_kfree_skb_irq,不过也有的设备比较个别
*自己去free,这个其实也没有什么问题的...省掉了软中断的处理*/
*/
if (sd->completion_queue) {
struct sk_buff *clist;
local_irq_disable();
clist = sd->completion_queue;
sd->completion_queue = NULL;
local_irq_enable();
while (clist) {
struct sk_buff *skb = clist;
clist = clist->next;
WARN_ON(atomic_read(&skb->users));
if (likely(get_kfree_skb_cb(skb)->reason == SKB_REASON_CONSUMED))
trace_consume_skb(skb);
else
trace_kfree_skb(skb, net_tx_action);
if (skb->fclone != SKB_FCLONE_UNAVAILABLE)
__kfree_skb(skb);
else
__kfree_skb_defer(skb);
}
__kfree_skb_flush();
}
/*
* 如果当前CPU的softnet_data中存在待处理的输出网络
* 设备,则遍历output_queue队列,调用qdisc_run()来发送
* 数据包或者再次调度数据包输出软中断,在
* 合适的时机发送数据包。
*/
if (sd->output_queue) {
struct Qdisc *head;
local_irq_disable();
head = sd->output_queue;
sd->output_queue = NULL;
sd->output_queue_tailp = &sd->output_queue;
local_irq_enable();
while (head) {
struct Qdisc *q = head;
spinlock_t *root_lock;
head = head->next_sched;
root_lock = qdisc_lock(q);
if (spin_trylock(root_lock)) {
smp_mb__before_atomic();
clear_bit(__QDISC_STATE_SCHED,
&q->state);
qdisc_run(q);
spin_unlock(root_lock);
} else {
if (!test_bit(__QDISC_STATE_DEACTIVATED,
&q->state)) {
__netif_reschedule(q);
} else {
smp_mb__before_atomic();
clear_bit(__QDISC_STATE_SCHED,
&q->state);
}
}
}
}
根据设备有无enqueue的方法,可以分成两种发送数据包的方式,第一就是有拥塞控制的数据传输,第二个就是什么都没有的直接传输到driver的,当然大部分的于外界沟通的interface都属于第一种,像loopback,tunnel一些设备就属于第二种没有enqueue的!
2. 对于有拥塞控制的数据传输,也有2条路径,第一条就是在满足3个前提条件下,直接发送数据包到硬件,和上述第二种case是一样的, 第二条就是出现拥塞的状况,就是有封包发送不成功,或者数据包量比较大的状况,这时候会用到enqueue,应该是保证顺序,所以一般q有包的状况 就都需要enqueue,然后再去dequeue发送到硬件,毕竟进程的上下文不会让你过多的占用时间,有一定的量的限制,限制条件到了就会中断发送,改用软中断的方式!
从抓包工具中抓出来的网络日志的现象以及其他可疑的点来看可以分为2类:
1. 有些数据包被不断的重传(并不是TCP/UDP层的重传),同一个ipid的包不断的被抓到
2.数据包被送到netdevice层,但是并没有看到被送到driver
主要原因是driver 发送数据包出现问题,返回Error,导致数据包被放到Qdisc的queue中,但是还是会不断被尝试着重新发送!
下面我们从code 逻辑来分析:
正常的flow一般情况下是不会enqueue的,会直接发送,如果一旦driver发送失败了,就先将数据包enqueue,详细的发送过程可以参考文章:
最接近driver的函数__netdev_start_xmit如果发送失败会返回一个Error,如下面的值,例如Tx_Busy
enum netdev_tx {
__NETDEV_TX_MIN = INT_MIN, /* make sure enum is signed */
NETDEV_TX_OK = 0x00, /* driver took care of packet */
NETDEV_TX_BUSY = 0x10, /* driver tx path was busy*/
NETDEV_TX_LOCKED = 0x20, /* driver tx lock was already taken */
};
static inline netdev_tx_t __netdev_start_xmit(const struct net_device_ops *ops,
struct sk_buff *skb, struct net_device *dev,
bool more)
{
skb->xmit_more = more ? 1 : 0;
return ops->ndo_start_xmit(skb, dev);
}
返回一个错误的值,表示这个数据包发送出现问题,但是目前Qdisc会进行拥塞处理,将数据包在放到queue中,下面的代码段是在sch_direct_xmit函数中返回值处理的部分
如果发送成功,就会返回Q的len,如果NETDEV_TX_LOCKED会说明driver去lock的时候失败,其他状况下一般认为是默认的错误即TX BUSY,这个时候会调用dev_requeue_skb把数据包重新放到Qdisc的队列中
/*进行返回值处理! 如果ret < NET_XMIT_MASK 为true 否则 flase*/
if (dev_xmit_complete(ret)) {
/* Driver sent out skb successfully or skb was consumed */
/*这个地方需要注意可能有driver的负数的case,也意味着这个skb被drop了*/
ret = qdisc_qlen(q);//成功发送报文,如果缓存区中还有报文,则尝试继续发送报文
} else {
/* Driver returned NETDEV_TX_BUSY - requeue skb */
if (unlikely(ret != NETDEV_TX_BUSY))
net_warn_ratelimited("BUG %s code %d qlen %d\n",
dev->name, ret, q->q.qlen);
/*发生Tx Busy的时候,重新进行requeue*/
ret = dev_requeue_skb(skb, q);//发送失败,则 入队重新进行发送
}
把skb放到q->gso_skb中,然后增加q数量,然后调用__netif_schedule,这个是来使用软中断去发送数据包!
/* Modifications to data participating in scheduling must be protected with
* qdisc_lock(qdisc) spinlock.
*
* The idea is the following:
* - enqueue, dequeue are serialized via qdisc root lock
* - ingress filtering is also serialized via qdisc root lock
* - updates to tree and tree walking are only done under the rtnl mutex.
*/
static inline int dev_requeue_skb(struct sk_buff *skb, struct Qdisc *q)
{
q->gso_skb = skb;
q->qstats.requeues++;
qdisc_qstats_backlog_inc(q, skb);
q->q.qlen++; /* it‘s still part of the queue */
__netif_schedule(q);
return 0;
}
基本上这个包被放入queue中,还会通过软中断,或者下一个数据包包来的时候去触发__qdisc_run, 这里应该就是谁快就使用谁吧。
中间发送的过程中重点说一点就是dequeue skb的时候,发现TX stop的状况下都不会dequeue出skb
从下面来看,数据包仍然是能够被dequeue出来,之后还是会走到dev_hard_start_xmit 发送给driver, 如果driver还是无作为的话,那就看到netdevice层同一个ipid的包被不断的重发...
/* Note that dequeue_skb can possibly return a SKB list (via skb->next). * A requeued skb (via q->gso_skb) can also be a SKB list. */ static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate, int *packets) { struct sk_buff *skb = q->gso_skb; const struct netdev_queue *txq = q->dev_queue; *packets = 1; *validate = true; if (unlikely(skb)) { /* check the reason of requeuing without tx lock first */ txq = skb_get_tx_queue(txq->dev, skb); if (!netif_xmit_frozen_or_stopped(txq)) { q->gso_skb = NULL; qdisc_qstats_backlog_dec(q, skb); q->q.qlen--; } else//如果TXQ被stop了,那么无法dequeue出skb 就返回空 skb = NULL; /* skb in gso_skb were already validated */ *validate = false; } else { //如果是多Q或者txq没有被stop 就dequeue skb if (!(q->flags & TCQ_F_ONETXQUEUE) || !netif_xmit_frozen_or_stopped(txq)) { skb = q->dequeue(q); if (skb && qdisc_may_bulk(q)) try_bulk_dequeue_skb(q, skb, txq, packets); } } return skb; }
问题 2:
如果TCP协议中有数据包发送,送到netdevice了,但是driver并没有收到,在网络抓包工具中也没有显示出来任何发包的痕迹,不过一般情况下是 发着发着就不能发了。这个的原因主要是上层管理interface的process或者driver调用了netif_tx_stop_queue, 这个函数的作用就是把interface的txq停掉,不让发包
来看下发包过程中会不会遇到阻碍,假设没有enqueue的状况下,一个数据包跑到了sch_direct_xmit里面,会判断txq是否为stop或者frozen状态,如果是 就不发了
直接requeue了.
if (likely(skb)) { HARD_TX_LOCK(dev, txq, smp_processor_id()); /*如果说txq被stop,即置位QUEUE_STATE_ANY_XOFF_OR_FROZEN,就直接ret = NETDEV_TX_BUSY *如果说txq 正常运行,那么直接调用dev_hard_start_xmit发送数据包*/ if (!netif_xmit_frozen_or_stopped(txq)) skb = dev_hard_start_xmit(skb, dev, txq, &ret);//调用驱动发送报文 HARD_TX_UNLOCK(dev, txq); } else { spin_lock(root_lock); return qdisc_qlen(q); } spin_lock(root_lock); /*进行返回值处理! 如果ret < NET_XMIT_MASK 为true 否则 flase*/ if (dev_xmit_complete(ret)) { /* Driver sent out skb successfully or skb was consumed */ /*这个地方需要注意可能有driver的负数的case,也意味着这个skb被drop了*/ ret = qdisc_qlen(q);//成功发送报文,如果缓存区中还有报文,则尝试继续发送报文 } else { /* Driver returned NETDEV_TX_BUSY - requeue skb */ if (unlikely(ret != NETDEV_TX_BUSY)) net_warn_ratelimited("BUG %s code %d qlen %d\n", dev->name, ret, q->q.qlen); /*发生Tx Busy的时候,重新进行requeue*/ ret = dev_requeue_skb(skb, q);//发送失败,则 入队重新进行发送 }
既然requeue了,还可以dequeue再去发,想一下,及时能够dequeue出来,还是要调用到sch_direct_xmit,还是被down的继续requeue,这样其实舅舅白白的操作了链表,实际上kernel也没有那么傻了,在dequeue的时候就已经做了手脚,可以参考dequeue_skb的解释了... 如果txq 被stop直接就dequeue失败了..
static struct sk_buff *dequeue_skb(struct Qdisc *q, bool *validate, int *packets) { struct sk_buff *skb = q->gso_skb; const struct netdev_queue *txq = q->dev_queue; *packets = 1; *validate = true; if (unlikely(skb)) { /* check the reason of requeuing without tx lock first */ txq = skb_get_tx_queue(txq->dev, skb); if (!netif_xmit_frozen_or_stopped(txq)) { q->gso_skb = NULL; qdisc_qstats_backlog_dec(q, skb); q->q.qlen--; } else//如果TXQ被stop了,那么无法dequeue出skb 就返回空 skb = NULL; /* skb in gso_skb were already validated */ *validate = false; } else { //如果是多Q或者txq没有被stop 就dequeue skb if (!(q->flags & TCQ_F_ONETXQUEUE) || !netif_xmit_frozen_or_stopped(txq)) { skb = q->dequeue(q); if (skb && qdisc_may_bulk(q)) try_bulk_dequeue_skb(q, skb, txq, packets); } } return skb; }
看到不能上网,但上层确实有数据包发出来,不过Q最多帮你顶到1000个包,如果超了就彻底被drop了。这时就会产生丢包现象,另外提一下就是在driver发送速度较慢,上层输送数据较快的状况下,这样会不断的有数据包被enqueue,当达到一定的瓶颈的时候,也就是1000的时候,后面灌输过来的数据包就会被丢掉了,这样就会产生掉包的现象
标签:tom running span loopback tcp init 内核空间 output 多少
原文地址:https://www.cnblogs.com/codestack/p/9314057.html
