标签:限制 注册 ret present span key tput als tom
//当底层设备驱动程序接收一个报文时,就会通过调用netif_receive_skb将报文的SKB上传至网络层。
/*
在netif_rx函数中会调用netif_rx_schedule, 然后该函数又会去调用__netif_rx_schedule
在函数__netif_rx_schedule中会去触发软中断NET_RX_SOFTIRQ, 也即是去调用net_rx_action.
然后在net_rx_action函数中会去调用设备的poll函数, 它是设备自己注册的.
在设备的poll函数中, 会去调用netif_receive_skb函数, 在该函数中有下面一条语句 pt_prev->func, 此处的func为一个函数指针,
因此, 就完成了从链路层上传到网络层的这一个过程了.
*/
/*非NAPI方式,从驱动硬件中断中调用这个netif_rx函数,
而NAPI方式从硬件中断中调用____napi_schedule激活软中断,
*/
/*
非NAPI方式 NAPI方式NAPI方式(NAPI的napi_struct是自己构造的,该结构上的poll钩子函数也是自己定义的。
IRQ
|
_______________________|_____________________________
| |
netif_rx(netif_rx_internal) napi_schedule
上半部 | |
enqueue_to_backlog __napi_schedule
| |
skb加入input_pkt_queuem中 napi_struct加入poll_list中
__napi_schedule
softnet_data->backlog加入poll_list中 |
|____________________________________________________|
|
net_rx_action
下半部 |
_______________________|_____________________________
| |
process_backlog->__netif_receive_skb 驱动poll方法->napi_gro_receive->netif_receive_skb->__netif_receive_skb
*/
static int netif_rx_internal(struct sk_buff *skb)
{
int ret;
net_timestamp_check(netdev_tstamp_prequeue, skb);
trace_netif_rx(skb);
#ifdef CONFIG_RPS
if (static_key_false(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu;
preempt_disable();
rcu_read_lock();
cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu < 0)
cpu = smp_processor_id();
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);//这里面的数据在process_backlog
rcu_read_unlock();
preempt_enable();
} else
#endif
{
unsigned int qtail;
ret = enqueue_to_backlog(skb, get_cpu(), &qtail);
put_cpu();
}
return ret;
}
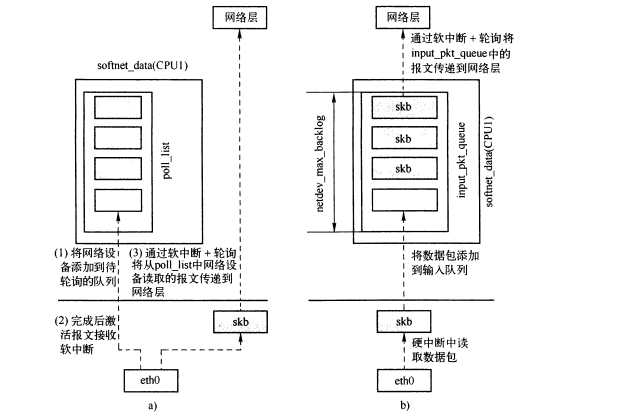
/* 队列中.在中断轮询的时候,软中断总函数do_softirq()直接到达网卡的接收软中断函数net_rx_action(),
在此函数中调用queue->backlog_dev.poll=process_backlog;即process_backlog()函数,它将queue->input_pkt_queue
队列中的数据向上层协议传输,比如网络层的ip协议等。
*/
/*
非NAPI方式 NAPI方式NAPI方式(NAPI的napi_struct是自己构造的,该结构上的poll钩子函数也是自己定义的
IRQ
|
_______________________|_____________________________
| |
netif_rx napi_schedule
上半部 | |
enqueue_to_backlog
____napi_schedule __napi_schedule
| |
skb加入input_pkt_queuem中 napi_struct加入poll_list中
softnet_data->backlog加入poll_list中 |
|____________________________________________________|
|
net_rx_action
下半部 |
_______________________|_____________________________
| |
porcess_backlog->__netif_receive_skb 驱动poll方法->napi_gro_receive->netif_receive_skb->__netif_receive_skb
*/
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
struct softnet_data *sd;
unsigned long flags;
unsigned int qlen;
sd = &per_cpu(softnet_data, cpu);//获取cpu接口缓存队列(每cpu变量下次写内核同步介绍)
local_irq_save(flags);//关中断,当该SKB添加到输入队列input_pkt_queue后打开中断,继续从硬件中断中接收输入然后放入该接收队列中
rps_lock(sd);
if (!netif_running(skb->dev))
goto drop;
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) {如果链路层缓存队列还没有满,则加入队列,否者上层处理严重阻塞,丢失,drop++
if (qlen) { 队列不为空,说明已经有数据,只需加入队列,等待下次软中断处理
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);/* 挂softnet_data输入队列 */ //net_rx_action中会对包的个数,以及软中断处理时间进行限制
input_queue_tail_incr_save(sd, qtail);
rps_unlock(sd);
local_irq_restore(flags);//打开中断,当该SKB添加到输入队列input_pkt_queue后打开中断,继续从硬件中断中接收输入然后放入该接收队列中
return NET_RX_SUCCESS;
}
/* Schedule NAPI for backlog device
* We can use non atomic operation since we own the queue lock
*/ /* &sd->backlog加入napi->poll_list,backlog即函数process_backlog */
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {
if (!rps_ipi_queued(sd))//这里就会调用net_dev_init中的->backlog_dev.poll=process_backlog从而到process_backlog中执行

for_each_possible_cpu(i) { struct softnet_data *sd = &per_cpu(softnet_data, i); skb_queue_head_init(&sd->input_pkt_queue); skb_queue_head_init(&sd->process_queue); INIT_LIST_HEAD(&sd->poll_list); sd->output_queue_tailp = &sd->output_queue; #ifdef CONFIG_RPS sd->csd.func = rps_trigger_softirq; sd->csd.info = sd; sd->cpu = i; #endif sd->backlog.poll = process_backlog; sd->backlog.weight = weight_p; } dev_boot_phase = 0; /* The loopback device is special if any other network devices * is present in a network namespace the loopback device must * be present. Since we now dynamically allocate and free the * loopback device ensure this invariant is maintained by * keeping the loopback device as the first device on the * list of network devices. Ensuring the loopback devices * is the first device that appears and the last network device * that disappears. */ if (register_pernet_device(&loopback_net_ops)) goto out; if (register_pernet_device(&default_device_ops)) goto out; open_softirq(NET_TX_SOFTIRQ, net_tx_action); open_softirq(NET_RX_SOFTIRQ, net_rx_action);
____napi_schedule(sd, &sd->backlog);//加入list 并激活软中断
/*NAPI方式,把dev设备添加到了poll_list链表中。
每个网络设备(MAC层)都有自己的net_device数据结构,这个结构上有napi_struct。每当收到数据包时,网络设备驱动会把自己的napi_struct挂到CPU私有变量上。
这样在软中断时,net_rx_action会遍历cpu私有变量的poll_list,执行上面所挂的napi_struct结构的poll钩子函数,将数据包从驱动传到网络协议栈。
NAPI的napi_struct是自己构造的,该结构上的poll钩子函数也是自己定义的。
非NAPI的napi_struct结构是默认的,也就是per cpu的softnet_data>backlog,起poll钩子函数为process_backlog
*/
/* Called with irq disabled */ static inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi) { list_add_tail(&napi->poll_list, &sd->poll_list); __raise_softirq_irqoff(NET_RX_SOFTIRQ); }
} goto enqueue; } drop: sd->dropped++; rps_unlock(sd); local_irq_restore(flags); atomic_long_inc(&skb->dev->rx_dropped); kfree_skb(skb); return NET_RX_DROP; }
标签:限制 注册 ret present span key tput als tom
原文地址:https://www.cnblogs.com/codestack/p/9163165.html
