标签:soc lambda ext 高斯 Nid 正是 span The 概率分布
线性回归很简单,用线性函数拟合数据,用 mean square error (mse) 计算损失(cost),然后用梯度下降法找到一组使 mse 最小的权重。
lasso 回归和岭回归(ridge regression)其实就是在标准线性回归的基础上分别加入 L1 和 L2 正则化(regularization)。
本文的重点是解释为什么 L1 正则化会比 L2 正则化让线性回归的权重更加稀疏,即使得线性回归中很多权重为 0,而不是接近 0。或者说,为什么 L1 正则化(lasso)可以进行 feature selection,而 L2 正则化(ridge)不行。
线性回归(linear regression),就是用线性函数 \(f(\bm x) = \bm w^{\top} \bm x + b\) 去拟合一组数据 \(D = \{(\bm x_1, y_1), (\bm x_2, y_2), ..., (\bm x_n, y_n)\}\) 并使得损失 \(J = \frac{1}{n}\sum_{i = 1}^n (f(\bm x_i) - y_i)^2\) 最小。线性回归的目标就是找到一组 \((\bm w^*, b^*)\),使得损失 \(J\) 最小。
线性回归的拟合函数(或 hypothesis)为:
\[
f(\bm x) = \bm w^{\top} \bm x + b
\tag{1}
\]
cost function (mse) 为:
\[
\begin{split}
J &= \frac{1}{n}\sum_{i = 1}^n (f(\bm x_i) - y_i)^2
\\ & = \frac{1}{n}\sum_{i = 1}^n (\bm w^{\top} \bm x_i + b - y_i)^2
\end{split}
\tag{2}
\]
Lasso 回归和岭回归(ridge regression)都是在标准线性回归的基础上修改 cost function,即修改式(2),其它地方不变。
Lasso 的全称为 least absolute shrinkage and selection operator,又译最小绝对值收敛和选择算子、套索算法。
Lasso 回归对式(2)加入 L1 正则化,其 cost function 如下:
\[
J = \frac{1}{n}\sum_{i = 1}^n (f(\bm x_i) - y_i)^2 + \lambda \|w\|_1
\tag{3}
\]
岭回归对式(2)加入 L2 正则化,其 cost function 如下:
\[
J = \frac{1}{n}\sum_{i = 1}^n (f(\bm x_i) - y_i)^2 + \lambda \|w\|_2^2
\tag{4}
\]
Lasso回归和岭回归的同和异:
lasso 和 ridge regression 的目标都是 \(\min_{\bm w, b} J\),式(3)和(4)都是拉格朗日形式,其中 \(\lambda\) 为拉格朗日乘子,我们也可以将 \(\min_{\bm w, b} J\) 写成如下形式:
lasso regression:
\[
\begin{array}{cl}
{\min \limits_{w, b}} & {\dfrac{1}{n}\sum_{i = 1}^n (\bm w^{\top} \bm x_i + b - y_i)^2}
\\ {\text{s.t.}} &{\|w\|_1 \le t}
\end{array}
\tag{5}
\]
ridge regression:
\[
\begin{array}{cl}
{\min \limits_{w, b}} & {\dfrac{1}{n}\sum_{i = 1}^n (\bm w^{\top} \bm x_i + b - y_i)^2}
\\ {\text{s.t.}} &{\|w\|_2^2 \le t}
\end{array}
\tag{6}
\]
式(5)和(6)可以理解为,在 \(\bm w\) 限制的取值范围内,找一个点 \(\hat{\bm w}\) 使得 mean square error 最小,\(t\) 可以理解为正则化的力度,式(5)和(6)中的 \(t\) 越小,就意味着式(3)和(4)中 \(\lambda\) 越大,正则化的力度越大 。
以 \(\bm x \in R^2\) 为例,式(5)中对 \(\bm w\) 的限制空间是方形,而式(6)中对 \(\bm w\) 的限制空间是圆形。因为 lasso 对 \(\bm w\) 的限制空间是有棱角的,因此 \(\arg \min_{w, b} {\frac{1}{n}\sum_{i = 1}^n (\bm w^{\top} \bm x_i + b - y_i)^2}\) 的解更容易切在 \(\bm w\) 的某一个维为 0 的点。如下图所示:
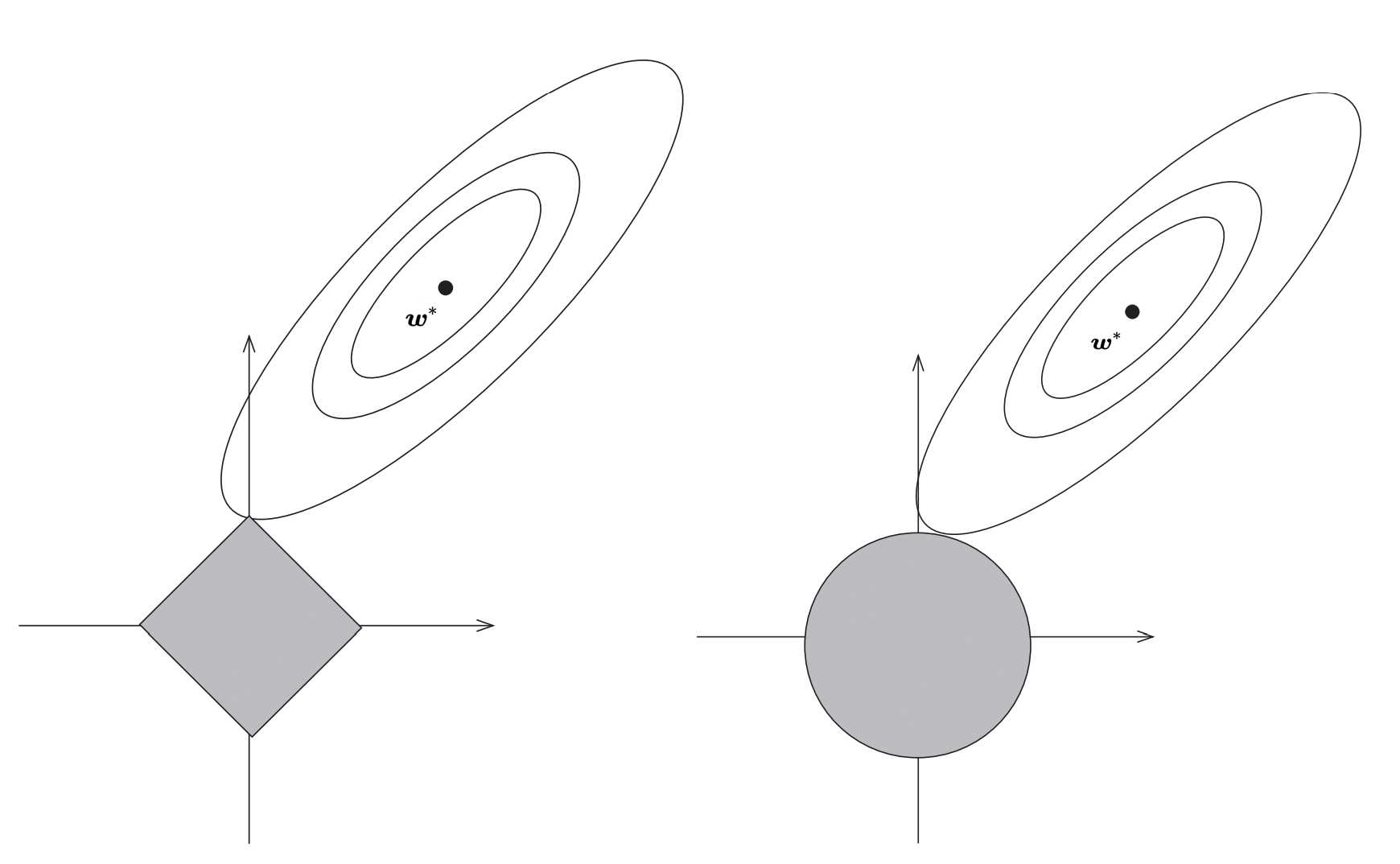
Fig. 1 中的坐标系表示 \(\bm w\) 的两维,一圈又一圈的椭圆表示函数 \(J = {\frac{1}{n}\sum_{i = 1}^n (\bm w^{\top} \bm x_i + b - y_i)^2}\) 的等高线,椭圆越往外,\(J\) 的值越大,\(\bm w^*\) 表示使得损失 \(J\) 取得全局最优的值。使用 Gradient descent,也就是让 \(\bm w\) 向着 \(\bm w^*\) 的位置走。如果没有 L1 或者 L2 正则化约束,\(\bm w^*\) 是可以被取到的。但是,由于有了约束 \(\|w\|_1 \le t\) 或 \(\|w\|_2^2 \le t\),\(\bm w\) 的取值只能限制在 Fig. 1 所示的灰色方形和圆形区域。当然调整 \(t\) 的值,我么能够扩大这两个区域。
等高线从低到高第一次和 \(\bm w\) 的取值范围相切的点,即是 lasso 和 ridge 回归想要找的权重 \(\hat{\bm w}\)。
lasso 限制了 \(\bm w\) 的取值范围为有棱角的方形,而 ridge 限制了 \(\bm w\) 的取值范围为圆形,等高线和方形区域的切点更有可能在坐标轴上,而等高线和圆形区域的切点在坐标轴上的概率很小。这就是为什么 lasso(L1 正则化)更容易使得部分权重取 0,使权重变稀疏;而 ridge(L2 正则化)只能使权重接近 0,很少等于 0。
正是由于 lasso 容易使得部分权重取 0,所以可以用其做 feature selection,lasso 的名字就指出了它是一个 selection operator。权重为 0 的 feature 对回归问题没有贡献,直接去掉权重为 0 的 feature,模型的输出值不变。
对于 ridge regression 进行 feature selection,你说它完全不可以吧也不是,weight 趋近于 0 的 feature 不要了不也可以,但是对模型的效果还是有损伤的,这个前提还得是 feature 进行了归一化。
[1] Tibshirani, R. (1996). Regression Shrinkage and Selection Via the Lasso. Journal Of The Royal Statistical Society: Series B (Methodological), 58(1), 267-288. doi: 10.1111/j.2517-6161.1996.tb02080.x
[2] Lasso算法 -- 维基百科
[3] 机器学习总结(一):线性回归、岭回归、Lasso回归 -- 她说巷尾的樱花开了
[4] 从贝叶斯角度深入理解正则化 -- Zxdon
线性回归——lasso回归和岭回归(ridge regression)
标签:soc lambda ext 高斯 Nid 正是 span The 概率分布
原文地址:https://www.cnblogs.com/wuliytTaotao/p/10837533.html