标签:amount etag 过滤 level 一个 数据量 server spirng sea
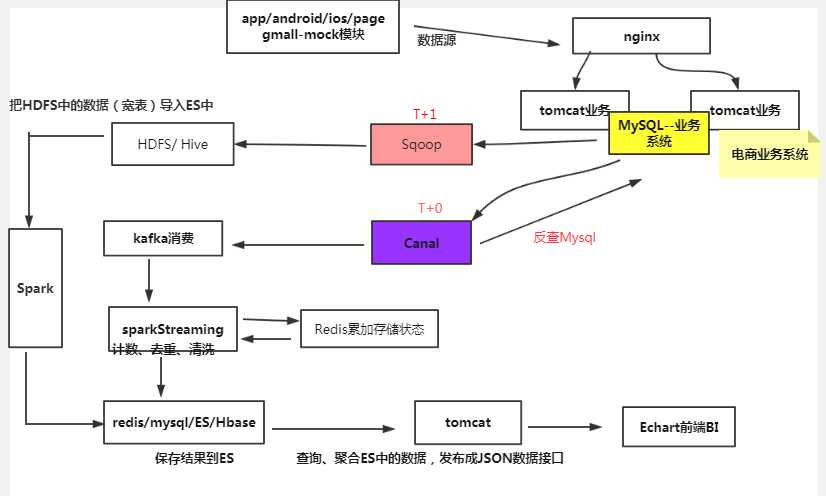
一般现在的实时框架两种:
①数据(日志log、DB)--->SparkStreaming(计算)---->Mysql / Redis (得到计算结果,一般数据量比较小,直接给前台即可);
DB-->Canal--->ES(es中没有join操作)
如果前台想根据数据进行分析,再进行统计,就不能拿结果进行分析,要拿明细宽表;这个宽表时要多个表进行join操作,而上边不管从mysql还是log都是单表操作;
②数据(hive宽表)---->SparkStreaming-----> ES(存储数据量大,也可以实时进行交互);有些可以容忍T+1(可以容忍一天),就可以使用hive进行join组成宽表;
T+0即使有canal得到更新变化的进行反查得到更多数据,在canal中做一个jdbc的查询mysql,实效有点延迟,对mysql的业务数据库也会增加一定的压力;
最终交互效果图:
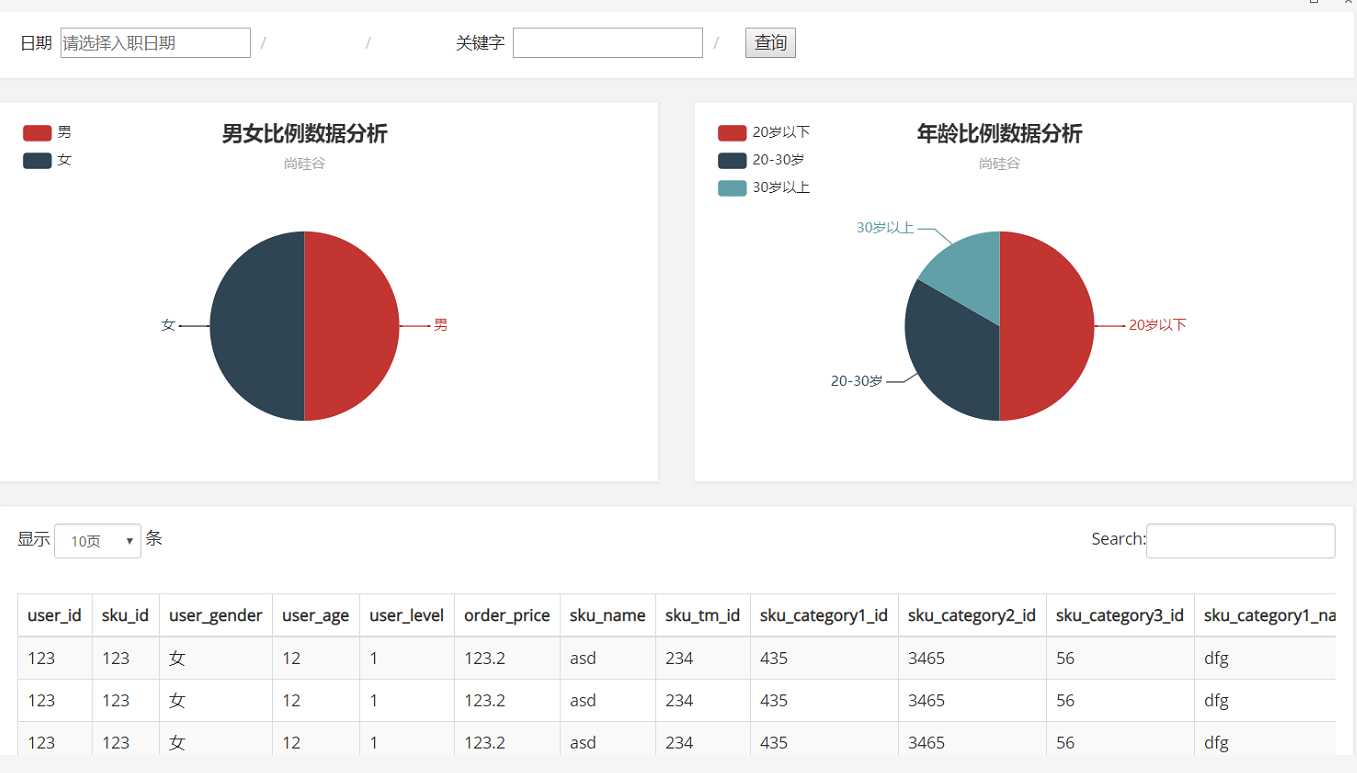
数仓中存储了大量的明细数据,但是hadoop存储的数仓计算必须经过mr ,所以即时交互性非常糟糕。为了方便数据分析人员查看信息,数据平台需要提供一个能够根据文字及选项等条件,进行灵活分析判断的数据功能。
建立gmall-hiveToES的maven模块
从hive中查询到宽表信息,导入到ES中;resources/ hive-site.xml ===>找hive中的源数据,要有mysql-connect-java的maven包
宽表dws_sale_detail_daycount的每个字段要和 样例类SaleDetailDaycount的类型要一致,对应不上就用cast进行转换;
只导入当天的数据,加上日期;最后程序会打成jar包,linux中传参数日期;
object SaleApp { def main(args: Array[String]): Unit = { var date: String = "" if (args.length > 0){ val date = args(0) }else{ date = "2019-05-09" } val sparkConf: SparkConf = new SparkConf().setAppName("gmall").setMaster("local[*]") val sparkSession: SparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate() // 读取hive 的宽表 sparkSession.sql("use gmall") import sparkSession.implicits._ //sparkSession.sql("select * from dws_sale_detail_daycount where dt=‘2019-05-09‘ and order_price is not null").show() val sqlSale = "select user_id,sku_id,user_gender," + "cast(user_age as int) user_age," + "user_level," + "cast(order_price as double) sku_price," + "sku_name,sku_tm_id, sku_category3_id,sku_category2_id, sku_category1_id,sku_category3_name,sku_category2_name,sku_category1_name,spu_id," + "cast(sku_num as long) sku_num, " + "cast(order_count as long) order_count," + "cast(order_amount as double) order_amount," + "dt from dws_sale_detail_daycount where dt=‘"+date+"‘ and order_price is not null" //如果hive中有大量null数据是不行的 val saleRdd: RDD[SaleDetailDaycount] = sparkSession.sql(sqlSale).as[SaleDetailDaycount].rdd //saleRdd.foreach(println) /*val filterRDD: RDD[SaleDetailDaycount] = saleRdd.filter(row => row != null)//过滤掉空null的,使用sql语句进行过滤 filterRDD.foreach(println)*/ // 往es中写入 saleRdd.foreachPartition { saleItr => var i = 0 val listBuffer: ListBuffer[SaleDetailDaycount] = new ListBuffer for (saleDetail <- saleItr) { listBuffer += saleDetail i += 1 //达到100进行批量保存 if (i%100 == 0){ MyEsUtil.insertEsBatch(GmallConstant.ES_INDEX_SALE, listBuffer.toList) listBuffer.clear() } } //零头 批量保存 if (listBuffer.size > 0){ MyEsUtil.insertEsBatch(GmallConstant.ES_INDEX_SALE, listBuffer.toList) } } } }
分析宽表字段:
字段一共分3类 : 需要分词匹配的,需要索引(过滤、聚合、排序)的,不需要索引的 string comment ‘用户 id‘, string comment ‘商品 Id‘, string comment ‘用户性别‘, string comment ‘用户年龄‘, string comment ‘用户等级‘, decimal(10,2) comment ‘订单价格‘, string comment ‘商品名称‘, string comment ‘品牌id‘, string comment ‘商品三级品类id‘, string comment ‘商品二级品类id‘, string comment ‘商品一级品类id‘, string comment ‘商品三级品类名称‘, string comment ‘商品二级品类名称‘, string comment ‘商品一级品类名称‘, string comment ‘商品 spu‘, int comment ‘购买个数‘, string comment ‘当日下单单数‘, string comment ‘当日下单金额‘ user_id 需要过滤匹配的 sku_id 需要过滤匹配的 user_gender 需要过滤匹配的 user_age 需要过滤匹配的 user_level 需要过滤匹配的 sku_price 需要过滤匹配的 sku_name 需要分词匹配的 sku_tm_id 需要过滤匹配的 sku_category1_id 需要过滤匹配的 sku_category2_id 需要过滤匹配的 sku_category3_id 需要过滤匹配的 sku_category1_name 需要分词匹配的 sku_category2_name 需要分词匹配的 sku_category3_name 需要分词匹配的 spu_id 需要过滤匹配的 sku_num 需要过滤匹配的 order_count 需要过滤匹配的 order_amount 需要过滤匹配的
建立mapping时,要考虑要不要分词,要不要索引
mapping表结构定义
ES字段定义要考虑:
1.某个字段要不要分词;(分词时用来查询的;是否要全文索引,是否需要查询) 商品名称、文章、文章标题 取决于字段类型;
分词时要选择text, keyword不分词;
关键词查询, ; 中文的索引需要选分词器:ik有两种:ik_smart(尽可能精简的分)、 ik_max_word(尽可能多的分),商品名称一般用这个分词器;
2.某个字段要不要索引; index=true就是索引,index=false就不用索引 过滤 排序 聚合
text既分词又索引,但不能聚合;
首先要安装分词器 https://www.cnblogs.com/shengyang17/p/10583596.html 中文分词
PUT gmall_sale_detail { "mappings": { "_doc":{ "properties":{ "user_id":{ "type":"keyword" }, "sku_id":{ "type":"keyword" }, "user_gender":{ "type":"keyword" }, "user_age":{ "type":"short" }, "user_level":{ "type":"keyword" }, "sku_price":{ "type":"double" }, "sku_name":{ "type":"text", "analyzer": "ik_max_word" }, "sku_tm_id ":{ "type":"keyword" }, "sku_category3_id":{ "type":"keyword" }, "sku_category2_id":{ "type":"keyword" }, "sku_category1_id":{ "type":"keyword" }, "sku_category3_name":{ "type":"text", "analyzer": "ik_max_word" }, "sku_category2_name":{ "type":"text", "analyzer": "ik_max_word" }, "sku_category1_name":{ "type":"text", "analyzer": "ik_max_word" }, "spu_id":{ "type":"keyword" }, "sku_num":{ "type":"long" }, "order_count":{ "type":"long" }, "order_amount":{ "type":"long" }, "dt":{ "type":"keyword" } } } } }
需要利用关键词查询
传入路径及参数:
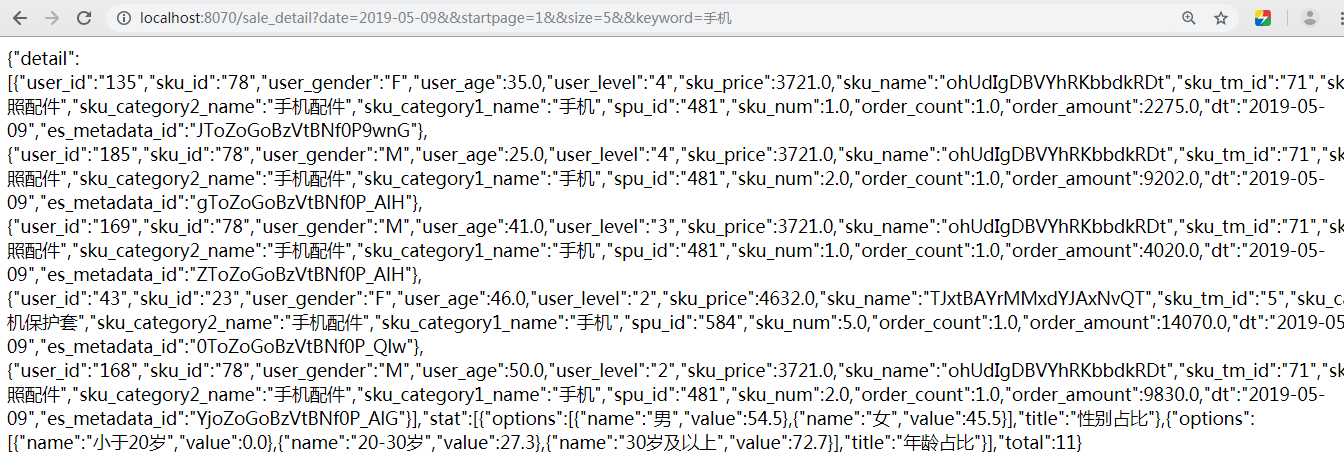
http://localhost:8070/sale_detail?date=2019-05-09&&startpage=1&&size=5&&keyword=手机
返回格式JSON串:
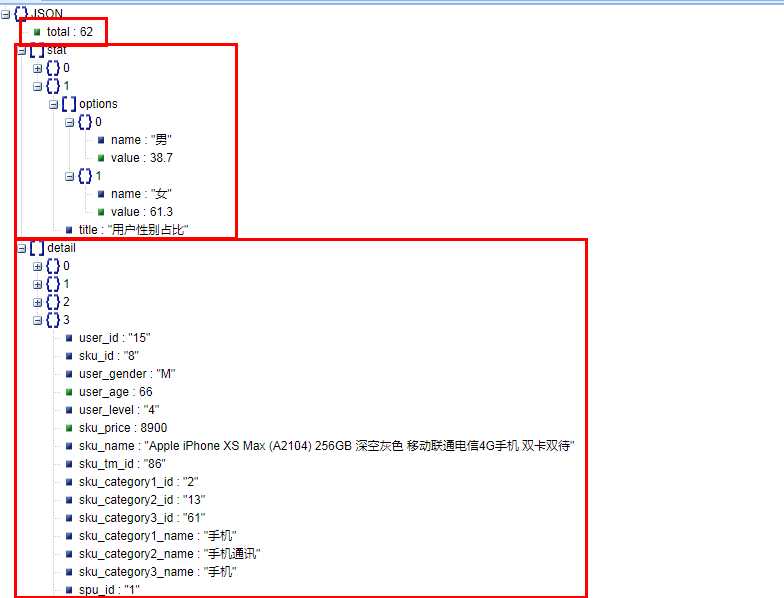
DSL查询语句:
match匹配; 小米且 手机,使用operator: and;#######过滤: 日期、关键词、匹配
######日期+关键字匹配
GET gmall_sale_detail/_search { "query": { "bool": { "filter": { "term": { "dt": "2019-05-09" } }, "must": [ {"match":{ "sku_category1_name": { "query": "手机", "operator": "and" } } } ] } } , "size": 100 }
聚合性别和 年龄
##聚合性别 GET gmall_sale_detail/_search { "query": { "bool": { "filter": { "term": { "dt": "2019-05-09" } }, "must": [ {"match":{ "sku_category1_name": { "query": "手机", "operator": "and" } } } ] } } , "aggs": { "groupby_gender": { "terms": { "field": "user_gender", "size": 2 } } } , "size": 100 }
同理聚合年龄;这两个聚合是并列的,不能写在一块:

##聚合年龄 GET gmall_sale_detail/_search { "query": { "bool": { "filter": { "term": { "dt": "2019-05-09" } }, "must": [ {"match":{ "sku_category1_name": { "query": "手机", "operator": "and" } } } ] } } , "aggs": { "groupby_age": { "terms": { "field": "user_age", "size": 100 } } } , "size": 100 }
把DSL语句转变成代码实现:
SpringBoot---gmall-publisher
publisherServerImpl.java
/** 宽表导入ES中,es中进行过滤、匹配、聚合 **/ @Override public SaleInfo getSaleInfo(String date, String keyword, int startPage, int pagesize, String aggsFieldName, int aggsize) { SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder(); //过滤日期 boolQueryBuilder.filter(new TermQueryBuilder("dt", date)); //匹配: 商品关键词 boolQueryBuilder.must(new MatchQueryBuilder("sku_category1_name", keyword).operator(MatchQueryBuilder.Operator.AND)); searchSourceBuilder.query(boolQueryBuilder); //聚合 TermsBuilder termsAggs = AggregationBuilders.terms("groupby_" + aggsFieldName).field(aggsFieldName).size(aggsize); searchSourceBuilder.aggregation(termsAggs); //分页 searchSourceBuilder.from((startPage-1) * pagesize); searchSourceBuilder.size(pagesize); Search search = new Search.Builder(searchSourceBuilder.toString()).addIndex(GmallConstant.ES_INDEX_SALE).addType(GmallConstant.ES_TYPE_DEFAULT).build(); SaleInfo saleInfo = new SaleInfo(); List<Map> detailList = new ArrayList<>(); try { SearchResult searchResult = jestClient.execute(search); //总数 saleInfo.setTotal(searchResult.getTotal()); //要set; 不然后边查询时会报java.lang.NullPointerException: null //明细 List<SearchResult.Hit<Map, Void>> hits = searchResult.getHits(Map.class); for (SearchResult.Hit<Map, Void> hit : hits) { Map source = hit.source; detailList.add(source); } saleInfo.setDetail(detailList); //饼图(聚合结果) Map aggsTempMap = new HashMap<>(); List<TermsAggregation.Entry> buckets = searchResult.getAggregations().getTermsAggregation("groupby_" + aggsFieldName).getBuckets(); for (TermsAggregation.Entry bucket : buckets) { aggsTempMap.put(bucket.getKey(), bucket.getCount()); } saleInfo.setTempAggsMap(aggsTempMap); } catch (IOException e) { e.printStackTrace(); } return saleInfo; }
启动SpringBoot的类:com.atguigu.gmall.publisher.GmallPublisherApplication
启动SpirngBoot---db-chart的主类:com.demo.DemoApplication
localhost:8089/table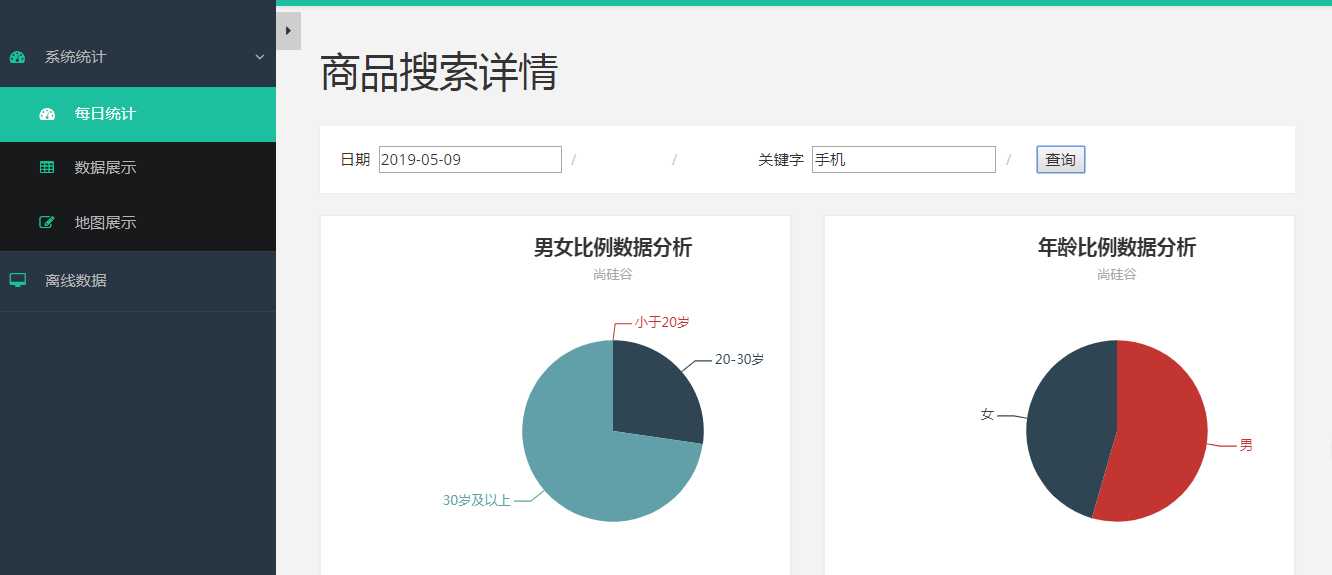
标签:amount etag 过滤 level 一个 数据量 server spirng sea
原文地址:https://www.cnblogs.com/shengyang17/p/10851782.html
